 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSV4D 2.0: Enhancing Spatio-Temporal Consistency in Multi-View Video Diffusion for High-Quality 4D Generation
Mar 21, 2025



We present Stable Video 4D 2.0 (SV4D 2.0), a multi-view video diffusion model for dynamic 3D asset generation. Compared to its predecessor SV4D, SV4D 2.0 is more robust to occlusions and large motion, generalizes better to real-world videos, and produces higher-quality outputs in terms of detail sharpness and spatio-temporal consistency. We achieve this by introducing key improvements in multiple aspects: 1) network architecture: eliminating the dependency of reference multi-views and designing blending mechanism for 3D and frame attention, 2) data: enhancing quality and quantity of training data, 3) training strategy: adopting progressive 3D-4D training for better generalization, and 4) 4D optimization: handling 3D inconsistency and large motion via 2-stage refinement and progressive frame sampling. Extensive experiments demonstrate significant performance gain by SV4D 2.0 both visually and quantitatively, achieving better detail (-14\% LPIPS) and 4D consistency (-44\% FV4D) in novel-view video synthesis and 4D optimization (-12\% LPIPS and -24\% FV4D) compared to SV4D.
Stable Virtual Camera: Generative View Synthesis with Diffusion Models
Mar 18, 2025We present Stable Virtual Camera (Seva), a generalist diffusion model that creates novel views of a scene, given any number of input views and target cameras. Existing works struggle to generate either large viewpoint changes or temporally smooth samples, while relying on specific task configurations. Our approach overcomes these limitations through simple model design, optimized training recipe, and flexible sampling strategy that generalize across view synthesis tasks at test time. As a result, our samples maintain high consistency without requiring additional 3D representation-based distillation, thus streamlining view synthesis in the wild. Furthermore, we show that our method can generate high-quality videos lasting up to half a minute with seamless loop closure. Extensive benchmarking demonstrates that Seva outperforms existing methods across different datasets and settings.
DecompDreamer: Advancing Structured 3D Asset Generation with Multi-Object Decomposition and Gaussian Splatting
Mar 15, 2025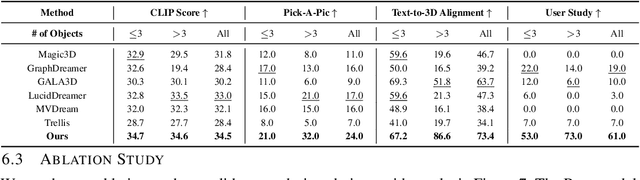
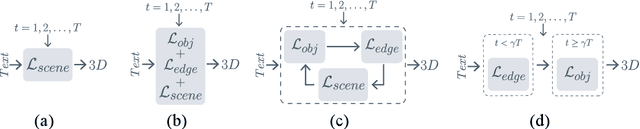

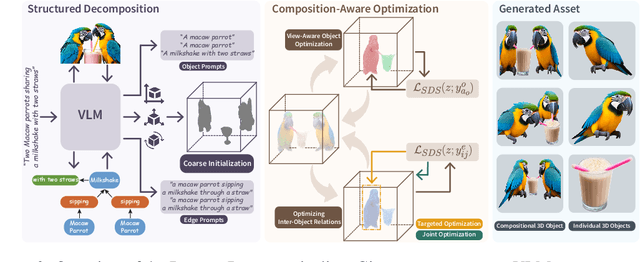
Text-to-3D generation saw dramatic advances in recent years by leveraging Text-to-Image models. However, most existing techniques struggle with compositional prompts, which describe multiple objects and their spatial relationships. They often fail to capture fine-grained inter-object interactions. We introduce DecompDreamer, a Gaussian splatting-based training routine designed to generate high-quality 3D compositions from such complex prompts. DecompDreamer leverages Vision-Language Models (VLMs) to decompose scenes into structured components and their relationships. We propose a progressive optimization strategy that first prioritizes joint relationship modeling before gradually shifting toward targeted object refinement. Our qualitative and quantitative evaluations against state-of-the-art text-to-3D models demonstrate that DecompDreamer effectively generates intricate 3D compositions with superior object disentanglement, offering enhanced control and flexibility in 3D generation. Project page : https://decompdreamer3d.github.io
Unified Dense Prediction of Video Diffusion
Mar 12, 2025



We present a unified network for simultaneously generating videos and their corresponding entity segmentation and depth maps from text prompts. We utilize colormap to represent entity masks and depth maps, tightly integrating dense prediction with RGB video generation. Introducing dense prediction information improves video generation's consistency and motion smoothness without increasing computational costs. Incorporating learnable task embeddings brings multiple dense prediction tasks into a single model, enhancing flexibility and further boosting performance. We further propose a large-scale dense prediction video dataset~\datasetname, addressing the issue that existing datasets do not concurrently contain captions, videos, segmentation, or depth maps. Comprehensive experiments demonstrate the high efficiency of our method, surpassing the state-of-the-art in terms of video quality, consistency, and motion smoothness.
SPAR3D: Stable Point-Aware Reconstruction of 3D Objects from Single Images
Jan 08, 2025



We study the problem of single-image 3D object reconstruction. Recent works have diverged into two directions: regression-based modeling and generative modeling. Regression methods efficiently infer visible surfaces, but struggle with occluded regions. Generative methods handle uncertain regions better by modeling distributions, but are computationally expensive and the generation is often misaligned with visible surfaces. In this paper, we present SPAR3D, a novel two-stage approach aiming to take the best of both directions. The first stage of SPAR3D generates sparse 3D point clouds using a lightweight point diffusion model, which has a fast sampling speed. The second stage uses both the sampled point cloud and the input image to create highly detailed meshes. Our two-stage design enables probabilistic modeling of the ill-posed single-image 3D task while maintaining high computational efficiency and great output fidelity. Using point clouds as an intermediate representation further allows for interactive user edits. Evaluated on diverse datasets, SPAR3D demonstrates superior performance over previous state-of-the-art methods, at an inference speed of 0.7 seconds. Project page with code and model: https://spar3d.github.io
Not all Views are Created Equal: Analyzing Viewpoint Instabilities in Vision Foundation Models
Dec 27, 2024



In this paper, we analyze the viewpoint stability of foundational models - specifically, their sensitivity to changes in viewpoint- and define instability as significant feature variations resulting from minor changes in viewing angle, leading to generalization gaps in 3D reasoning tasks. We investigate nine foundational models, focusing on their responses to viewpoint changes, including the often-overlooked accidental viewpoints where specific camera orientations obscure an object's true 3D structure. Our methodology enables recognizing and classifying out-of-distribution (OOD), accidental, and stable viewpoints using feature representations alone, without accessing the actual images. Our findings indicate that while foundation models consistently encode accidental viewpoints, they vary in their interpretation of OOD viewpoints due to inherent biases, at times leading to object misclassifications based on geometric resemblance. Through quantitative and qualitative evaluations on three downstream tasks - classification, VQA, and 3D reconstruction - we illustrate the impact of viewpoint instability and underscore the importance of feature robustness across diverse viewing conditions.
CompGS: Unleashing 2D Compositionality for Compositional Text-to-3D via Dynamically Optimizing 3D Gaussians
Oct 28, 2024



Recent breakthroughs in text-guided image generation have significantly advanced the field of 3D generation. While generating a single high-quality 3D object is now feasible, generating multiple objects with reasonable interactions within a 3D space, a.k.a. compositional 3D generation, presents substantial challenges. This paper introduces CompGS, a novel generative framework that employs 3D Gaussian Splatting (GS) for efficient, compositional text-to-3D content generation. To achieve this goal, two core designs are proposed: (1) 3D Gaussians Initialization with 2D compositionality: We transfer the well-established 2D compositionality to initialize the Gaussian parameters on an entity-by-entity basis, ensuring both consistent 3D priors for each entity and reasonable interactions among multiple entities; (2) Dynamic Optimization: We propose a dynamic strategy to optimize 3D Gaussians using Score Distillation Sampling (SDS) loss. CompGS first automatically decomposes 3D Gaussians into distinct entity parts, enabling optimization at both the entity and composition levels. Additionally, CompGS optimizes across objects of varying scales by dynamically adjusting the spatial parameters of each entity, enhancing the generation of fine-grained details, particularly in smaller entities. Qualitative comparisons and quantitative evaluations on T3Bench demonstrate the effectiveness of CompGS in generating compositional 3D objects with superior image quality and semantic alignment over existing methods. CompGS can also be easily extended to controllable 3D editing, facilitating scene generation. We hope CompGS will provide new insights to the compositional 3D generation. Project page: https://chongjiange.github.io/compgs.html.
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
Oct 04, 2024



Estimating geometry from dynamic scenes, where objects move and deform over time, remains a core challenge in computer vision. Current approaches often rely on multi-stage pipelines or global optimizations that decompose the problem into subtasks, like depth and flow, leading to complex systems prone to errors. In this paper, we present Motion DUSt3R (MonST3R), a novel geometry-first approach that directly estimates per-timestep geometry from dynamic scenes. Our key insight is that by simply estimating a pointmap for each timestep, we can effectively adapt DUST3R's representation, previously only used for static scenes, to dynamic scenes. However, this approach presents a significant challenge: the scarcity of suitable training data, namely dynamic, posed videos with depth labels. Despite this, we show that by posing the problem as a fine-tuning task, identifying several suitable datasets, and strategically training the model on this limited data, we can surprisingly enable the model to handle dynamics, even without an explicit motion representation. Based on this, we introduce new optimizations for several downstream video-specific tasks and demonstrate strong performance on video depth and camera pose estimation, outperforming prior work in terms of robustness and efficiency. Moreover, MonST3R shows promising results for primarily feed-forward 4D reconstruction.
ConDense: Consistent 2D/3D Pre-training for Dense and Sparse Features from Multi-View Images
Aug 30, 2024



To advance the state of the art in the creation of 3D foundation models, this paper introduces the ConDense framework for 3D pre-training utilizing existing pre-trained 2D networks and large-scale multi-view datasets. We propose a novel 2D-3D joint training scheme to extract co-embedded 2D and 3D features in an end-to-end pipeline, where 2D-3D feature consistency is enforced through a volume rendering NeRF-like ray marching process. Using dense per pixel features we are able to 1) directly distill the learned priors from 2D models to 3D models and create useful 3D backbones, 2) extract more consistent and less noisy 2D features, 3) formulate a consistent embedding space where 2D, 3D, and other modalities of data (e.g., natural language prompts) can be jointly queried. Furthermore, besides dense features, ConDense can be trained to extract sparse features (e.g., key points), also with 2D-3D consistency -- condensing 3D NeRF representations into compact sets of decorated key points. We demonstrate that our pre-trained model provides good initialization for various 3D tasks including 3D classification and segmentation, outperforming other 3D pre-training methods by a significant margin. It also enables, by exploiting our sparse features, additional useful downstream tasks, such as matching 2D images to 3D scenes, detecting duplicate 3D scenes, and querying a repository of 3D scenes through natural language -- all quite efficiently and without any per-scene fine-tuning.
SF3D: Stable Fast 3D Mesh Reconstruction with UV-unwrapping and Illumination Disentanglement
Aug 01, 2024



We present SF3D, a novel method for rapid and high-quality textured object mesh reconstruction from a single image in just 0.5 seconds. Unlike most existing approaches, SF3D is explicitly trained for mesh generation, incorporating a fast UV unwrapping technique that enables swift texture generation rather than relying on vertex colors. The method also learns to predict material parameters and normal maps to enhance the visual quality of the reconstructed 3D meshes. Furthermore, SF3D integrates a delighting step to effectively remove low-frequency illumination effects, ensuring that the reconstructed meshes can be easily used in novel illumination conditions. Experiments demonstrate the superior performance of SF3D over the existing techniques. Project page: https://stable-fast-3d.github.io