 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMAG: Concept-Scaffolded Retrieval for Marketplace Avatar Generation
May 18, 2026Metaverse platforms rely on creator-driven marketplaces where avatars are assembled from discrete, taxonomy-labeled 3D assets (e.g., tops, bottoms, shoes, accessories) under strict category and topology constraints. While users increasingly expect free-form text control, text-only retrieval is brittle: natural language is ambiguous with respect to platform taxonomies, metadata is often noisy or informal, and independently retrieved components can be stylistically inconsistent or geometrically incompatible. We propose \textbf{CMAG}, a concept-scaffolded retrieval and verified composition framework for marketplace avatar generation. Given a prompt, CMAG first synthesizes an intermediate 3D concept scaffold that disambiguates intent beyond text by providing global spatial and stylistic context. In parallel, a view-aware part discovery module extracts localized visual evidence via prompt decomposition and text-grounded segmentation. A prompt-conditioned taxonomy router enforces category coverage and resolves semantic-to-taxonomic mismatch, after which a hybrid category-wise retriever combines part-based fusion with a concept-residual fallback using feature suppression. Finally, an agentic vision--language model filters and re-ranks candidates across categories and drives an iterative verification loop to assemble prompt-faithful, topologically consistent avatars from catalog assets. We evaluate CMAG on diverse compositional prompts and demonstrate improved retrieval robustness and compositional correctness compared to strong baselines, highlighting the importance of 3D concept scaffolding under prompt ambiguity.
Mesquite MoCap: Democratizing Real-Time Motion Capture with Affordable, Bodyworn IoT Sensors and WebXR SLAM
Dec 27, 2025Motion capture remains costly and complex to deploy, limiting use outside specialized laboratories. We present Mesquite, an open-source, low-cost inertial motion-capture system that combines a body-worn network of 15 IMU sensor nodes with a hip-worn Android smartphone for position tracking. A low-power wireless link streams quaternion orientations to a central USB dongle and a browser-based application for real-time visualization and recording. Built on modern web technologies -- WebGL for rendering, WebXR for SLAM, WebSerial and WebSockets for device and network I/O, and Progressive Web Apps for packaging -- the system runs cross-platform entirely in the browser. In benchmarks against a commercial optical system, Mesquite achieves mean joint-angle error of 2-5 degrees while operating at approximately 5% of the cost. The system sustains 30 frames per second with end-to-end latency under 15ms and a packet delivery rate of at least 99.7% in standard indoor environments. By leveraging IoT principles, edge processing, and a web-native stack, Mesquite lowers the barrier to motion capture for applications in entertainment, biomechanics, healthcare monitoring, human-computer interaction, and virtual reality. We release hardware designs, firmware, and software under an open-source license (GNU GPL).
DecompDreamer: Advancing Structured 3D Asset Generation with Multi-Object Decomposition and Gaussian Splatting
Mar 15, 2025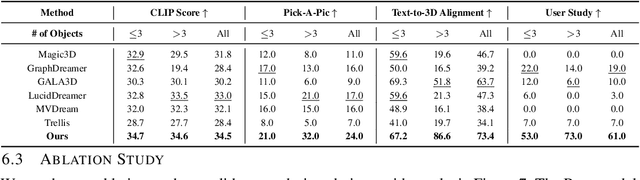
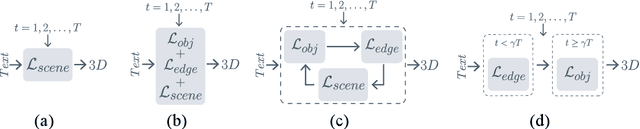

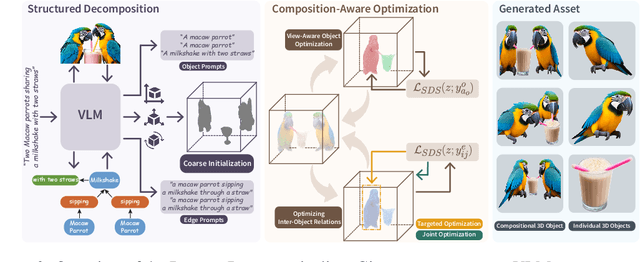
Text-to-3D generation saw dramatic advances in recent years by leveraging Text-to-Image models. However, most existing techniques struggle with compositional prompts, which describe multiple objects and their spatial relationships. They often fail to capture fine-grained inter-object interactions. We introduce DecompDreamer, a Gaussian splatting-based training routine designed to generate high-quality 3D compositions from such complex prompts. DecompDreamer leverages Vision-Language Models (VLMs) to decompose scenes into structured components and their relationships. We propose a progressive optimization strategy that first prioritizes joint relationship modeling before gradually shifting toward targeted object refinement. Our qualitative and quantitative evaluations against state-of-the-art text-to-3D models demonstrate that DecompDreamer effectively generates intricate 3D compositions with superior object disentanglement, offering enhanced control and flexibility in 3D generation. Project page : https://decompdreamer3d.github.io