 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction
Dec 15, 2025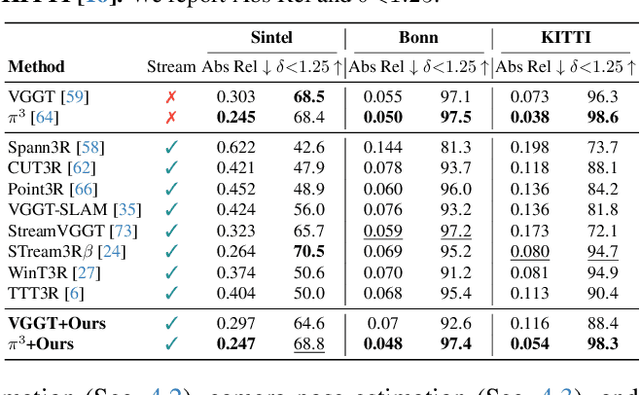
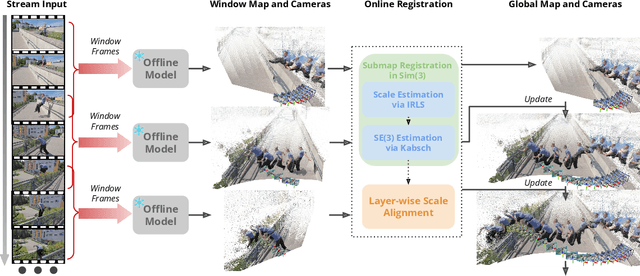
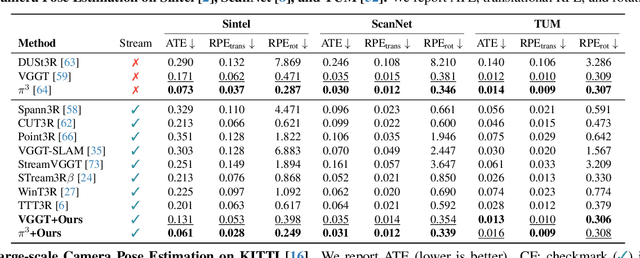
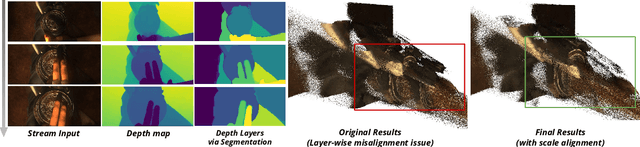
Recent feed-forward reconstruction models like VGGT and $π^3$ achieve impressive reconstruction quality but cannot process streaming videos due to quadratic memory complexity, limiting their practical deployment. While existing streaming methods address this through learned memory mechanisms or causal attention, they require extensive retraining and may not fully leverage the strong geometric priors of state-of-the-art offline models. We propose LASER, a training-free framework that converts an offline reconstruction model into a streaming system by aligning predictions across consecutive temporal windows. We observe that simple similarity transformation ($\mathrm{Sim}(3)$) alignment fails due to layer depth misalignment: monocular scale ambiguity causes relative depth scales of different scene layers to vary inconsistently between windows. To address this, we introduce layer-wise scale alignment, which segments depth predictions into discrete layers, computes per-layer scale factors, and propagates them across both adjacent windows and timestamps. Extensive experiments show that LASER achieves state-of-the-art performance on camera pose estimation and point map reconstruction %quality with offline models while operating at 14 FPS with 6 GB peak memory on a RTX A6000 GPU, enabling practical deployment for kilometer-scale streaming videos. Project website: $\href{https://neu-vi.github.io/LASER/}{\texttt{https://neu-vi.github.io/LASER/}}$
Struct2D: A Perception-Guided Framework for Spatial Reasoning in Large Multimodal Models
Jun 04, 2025Unlocking spatial reasoning in Large Multimodal Models (LMMs) is crucial for enabling intelligent interaction with 3D environments. While prior efforts often rely on explicit 3D inputs or specialized model architectures, we ask: can LMMs reason about 3D space using only structured 2D representations derived from perception? We introduce Struct2D, a perception-guided prompting framework that combines bird's-eye-view (BEV) images with object marks and object-centric metadata, optionally incorporating egocentric keyframes when needed. Using Struct2D, we conduct an in-depth zero-shot analysis of closed-source LMMs (e.g., GPT-o3) and find that they exhibit surprisingly strong spatial reasoning abilities when provided with structured 2D inputs, effectively handling tasks such as relative direction estimation and route planning. Building on these insights, we construct Struct2D-Set, a large-scale instruction tuning dataset with 200K fine-grained QA pairs across eight spatial reasoning categories, generated automatically from 3D indoor scenes. We fine-tune an open-source LMM (Qwen2.5VL) on Struct2D-Set, achieving competitive performance on multiple benchmarks, including 3D question answering, dense captioning, and object grounding. Our approach demonstrates that structured 2D inputs can effectively bridge perception and language reasoning in LMMs-without requiring explicit 3D representations as input. We will release both our code and dataset to support future research.
Absolute Coordinates Make Motion Generation Easy
May 26, 2025State-of-the-art text-to-motion generation models rely on the kinematic-aware, local-relative motion representation popularized by HumanML3D, which encodes motion relative to the pelvis and to the previous frame with built-in redundancy. While this design simplifies training for earlier generation models, it introduces critical limitations for diffusion models and hinders applicability to downstream tasks. In this work, we revisit the motion representation and propose a radically simplified and long-abandoned alternative for text-to-motion generation: absolute joint coordinates in global space. Through systematic analysis of design choices, we show that this formulation achieves significantly higher motion fidelity, improved text alignment, and strong scalability, even with a simple Transformer backbone and no auxiliary kinematic-aware losses. Moreover, our formulation naturally supports downstream tasks such as text-driven motion control and temporal/spatial editing without additional task-specific reengineering and costly classifier guidance generation from control signals. Finally, we demonstrate promising generalization to directly generate SMPL-H mesh vertices in motion from text, laying a strong foundation for future research and motion-related applications.
Sketch2Anim: Towards Transferring Sketch Storyboards into 3D Animation
Apr 27, 2025



Storyboarding is widely used for creating 3D animations. Animators use the 2D sketches in storyboards as references to craft the desired 3D animations through a trial-and-error process. The traditional approach requires exceptional expertise and is both labor-intensive and time-consuming. Consequently, there is a high demand for automated methods that can directly translate 2D storyboard sketches into 3D animations. This task is under-explored to date and inspired by the significant advancements of motion diffusion models, we propose to address it from the perspective of conditional motion synthesis. We thus present Sketch2Anim, composed of two key modules for sketch constraint understanding and motion generation. Specifically, due to the large domain gap between the 2D sketch and 3D motion, instead of directly conditioning on 2D inputs, we design a 3D conditional motion generator that simultaneously leverages 3D keyposes, joint trajectories, and action words, to achieve precise and fine-grained motion control. Then, we invent a neural mapper dedicated to aligning user-provided 2D sketches with their corresponding 3D keyposes and trajectories in a shared embedding space, enabling, for the first time, direct 2D control of motion generation. Our approach successfully transfers storyboards into high-quality 3D motions and inherently supports direct 3D animation editing, thanks to the flexibility of our multi-conditional motion generator. Comprehensive experiments and evaluations, and a user perceptual study demonstrate the effectiveness of our approach.
SV4D 2.0: Enhancing Spatio-Temporal Consistency in Multi-View Video Diffusion for High-Quality 4D Generation
Mar 21, 2025



We present Stable Video 4D 2.0 (SV4D 2.0), a multi-view video diffusion model for dynamic 3D asset generation. Compared to its predecessor SV4D, SV4D 2.0 is more robust to occlusions and large motion, generalizes better to real-world videos, and produces higher-quality outputs in terms of detail sharpness and spatio-temporal consistency. We achieve this by introducing key improvements in multiple aspects: 1) network architecture: eliminating the dependency of reference multi-views and designing blending mechanism for 3D and frame attention, 2) data: enhancing quality and quantity of training data, 3) training strategy: adopting progressive 3D-4D training for better generalization, and 4) 4D optimization: handling 3D inconsistency and large motion via 2-stage refinement and progressive frame sampling. Extensive experiments demonstrate significant performance gain by SV4D 2.0 both visually and quantitatively, achieving better detail (-14\% LPIPS) and 4D consistency (-44\% FV4D) in novel-view video synthesis and 4D optimization (-12\% LPIPS and -24\% FV4D) compared to SV4D.
Rethinking Diffusion for Text-Driven Human Motion Generation
Nov 25, 2024



Since 2023, Vector Quantization (VQ)-based discrete generation methods have rapidly dominated human motion generation, primarily surpassing diffusion-based continuous generation methods in standard performance metrics. However, VQ-based methods have inherent limitations. Representing continuous motion data as limited discrete tokens leads to inevitable information loss, reduces the diversity of generated motions, and restricts their ability to function effectively as motion priors or generation guidance. In contrast, the continuous space generation nature of diffusion-based methods makes them well-suited to address these limitations and with even potential for model scalability. In this work, we systematically investigate why current VQ-based methods perform well and explore the limitations of existing diffusion-based methods from the perspective of motion data representation and distribution. Drawing on these insights, we preserve the inherent strengths of a diffusion-based human motion generation model and gradually optimize it with inspiration from VQ-based approaches. Our approach introduces a human motion diffusion model enabled to perform bidirectional masked autoregression, optimized with a reformed data representation and distribution. Additionally, we also propose more robust evaluation methods to fairly assess different-based methods. Extensive experiments on benchmark human motion generation datasets demonstrate that our method excels previous methods and achieves state-of-the-art performances.
SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency
Jul 24, 2024We present Stable Video 4D (SV4D), a latent video diffusion model for multi-frame and multi-view consistent dynamic 3D content generation. Unlike previous methods that rely on separately trained generative models for video generation and novel view synthesis, we design a unified diffusion model to generate novel view videos of dynamic 3D objects. Specifically, given a monocular reference video, SV4D generates novel views for each video frame that are temporally consistent. We then use the generated novel view videos to optimize an implicit 4D representation (dynamic NeRF) efficiently, without the need for cumbersome SDS-based optimization used in most prior works. To train our unified novel view video generation model, we curated a dynamic 3D object dataset from the existing Objaverse dataset. Extensive experimental results on multiple datasets and user studies demonstrate SV4D's state-of-the-art performance on novel-view video synthesis as well as 4D generation compared to prior works.
SMooDi: Stylized Motion Diffusion Model
Jul 17, 2024



We introduce a novel Stylized Motion Diffusion model, dubbed SMooDi, to generate stylized motion driven by content texts and style motion sequences. Unlike existing methods that either generate motion of various content or transfer style from one sequence to another, SMooDi can rapidly generate motion across a broad range of content and diverse styles. To this end, we tailor a pre-trained text-to-motion model for stylization. Specifically, we propose style guidance to ensure that the generated motion closely matches the reference style, alongside a lightweight style adaptor that directs the motion towards the desired style while ensuring realism. Experiments across various applications demonstrate that our proposed framework outperforms existing methods in stylized motion generation.
SynFog: A Photo-realistic Synthetic Fog Dataset based on End-to-end Imaging Simulation for Advancing Real-World Defogging in Autonomous Driving
Mar 25, 2024



To advance research in learning-based defogging algorithms, various synthetic fog datasets have been developed. However, existing datasets created using the Atmospheric Scattering Model (ASM) or real-time rendering engines often struggle to produce photo-realistic foggy images that accurately mimic the actual imaging process. This limitation hinders the effective generalization of models from synthetic to real data. In this paper, we introduce an end-to-end simulation pipeline designed to generate photo-realistic foggy images. This pipeline comprehensively considers the entire physically-based foggy scene imaging process, closely aligning with real-world image capture methods. Based on this pipeline, we present a new synthetic fog dataset named SynFog, which features both sky light and active lighting conditions, as well as three levels of fog density. Experimental results demonstrate that models trained on SynFog exhibit superior performance in visual perception and detection accuracy compared to others when applied to real-world foggy images.
HOI-Diff: Text-Driven Synthesis of 3D Human-Object Interactions using Diffusion Models
Dec 11, 2023



We address the problem of generating realistic 3D human-object interactions (HOIs) driven by textual prompts. Instead of a single model, our key insight is to take a modular design and decompose the complex task into simpler sub-tasks. We first develop a dual-branch diffusion model (HOI-DM) to generate both human and object motions conditioning on the input text, and encourage coherent motions by a cross-attention communication module between the human and object motion generation branches. We also develop an affordance prediction diffusion model (APDM) to predict the contacting area between the human and object during the interactions driven by the textual prompt. The APDM is independent of the results by the HOI-DM and thus can correct potential errors by the latter. Moreover, it stochastically generates the contacting points to diversify the generated motions. Finally, we incorporate the estimated contacting points into the classifier-guidance to achieve accurate and close contact between humans and objects. To train and evaluate our approach, we annotate BEHAVE dataset with text descriptions. Experimental results demonstrate that our approach is able to produce realistic HOIs with various interactions and different types of objects.