 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactual Error Correction for Abstractive Summaries Using Entity Retrieval
Apr 18, 2022
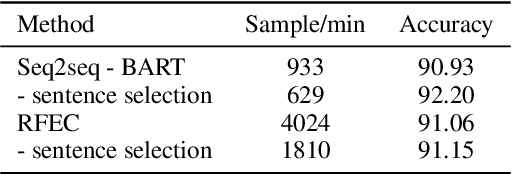
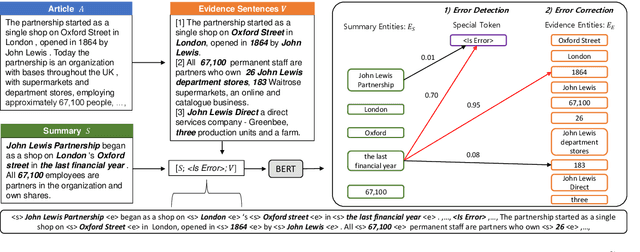
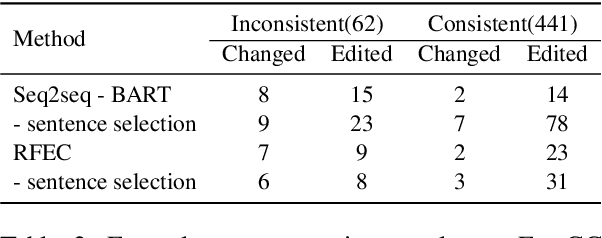
Despite the recent advancements in abstractive summarization systems leveraged from large-scale datasets and pre-trained language models, the factual correctness of the summary is still insufficient. One line of trials to mitigate this problem is to include a post-editing process that can detect and correct factual errors in the summary. In building such a post-editing system, it is strongly required that 1) the process has a high success rate and interpretability and 2) has a fast running time. Previous approaches focus on regeneration of the summary using the autoregressive models, which lack interpretability and require high computing resources. In this paper, we propose an efficient factual error correction system RFEC based on entities retrieval post-editing process. RFEC first retrieves the evidence sentences from the original document by comparing the sentences with the target summary. This approach greatly reduces the length of text for a system to analyze. Next, RFEC detects the entity-level errors in the summaries by considering the evidence sentences and substitutes the wrong entities with the accurate entities from the evidence sentences. Experimental results show that our proposed error correction system shows more competitive performance than baseline methods in correcting the factual errors with a much faster speed.
MHMS: Multimodal Hierarchical Multimedia Summarization
Apr 07, 2022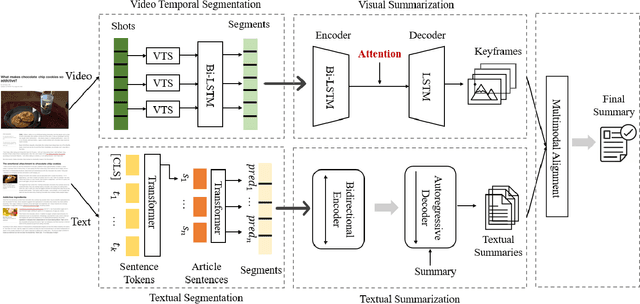
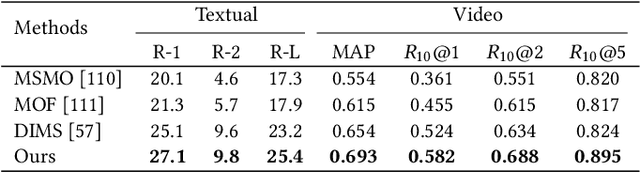
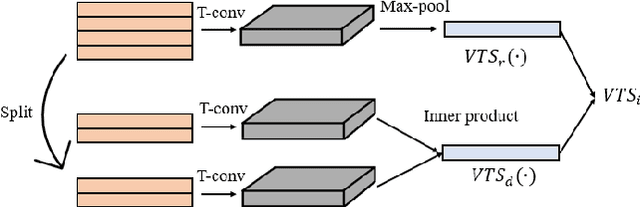

Multimedia summarization with multimodal output can play an essential role in real-world applications, i.e., automatically generating cover images and titles for news articles or providing introductions to online videos. In this work, we propose a multimodal hierarchical multimedia summarization (MHMS) framework by interacting visual and language domains to generate both video and textual summaries. Our MHMS method contains video and textual segmentation and summarization module, respectively. It formulates a cross-domain alignment objective with optimal transport distance which leverages cross-domain interaction to generate the representative keyframe and textual summary. We evaluated MHMS on three recent multimodal datasets and demonstrated the effectiveness of our method in producing high-quality multimodal summaries.
CAISE: Conversational Agent for Image Search and Editing
Feb 24, 2022
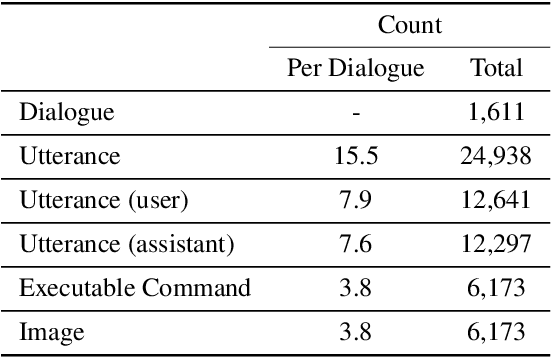

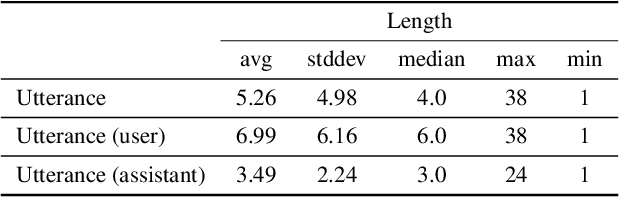
Demand for image editing has been increasing as users' desire for expression is also increasing. However, for most users, image editing tools are not easy to use since the tools require certain expertise in photo effects and have complex interfaces. Hence, users might need someone to help edit their images, but having a personal dedicated human assistant for every user is impossible to scale. For that reason, an automated assistant system for image editing is desirable. Additionally, users want more image sources for diverse image editing works, and integrating an image search functionality into the editing tool is a potential remedy for this demand. Thus, we propose a dataset of an automated Conversational Agent for Image Search and Editing (CAISE). To our knowledge, this is the first dataset that provides conversational image search and editing annotations, where the agent holds a grounded conversation with users and helps them to search and edit images according to their requests. To build such a system, we first collect image search and editing conversations between pairs of annotators. The assistant-annotators are equipped with a customized image search and editing tool to address the requests from the user-annotators. The functions that the assistant-annotators conduct with the tool are recorded as executable commands, allowing the trained system to be useful for real-world application execution. We also introduce a generator-extractor baseline model for this task, which can adaptively select the source of the next token (i.e., from the vocabulary or from textual/visual contexts) for the executable command. This serves as a strong starting point while still leaving a large human-machine performance gap for useful future work. Our code and dataset are publicly available at: https://github.com/hyounghk/CAISE
Double Trouble: How to not explain a text classifier's decisions using counterfactuals synthesized by masked language models?
Oct 22, 2021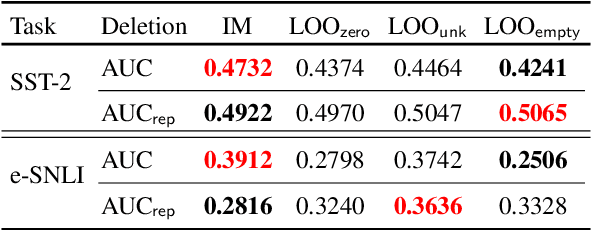
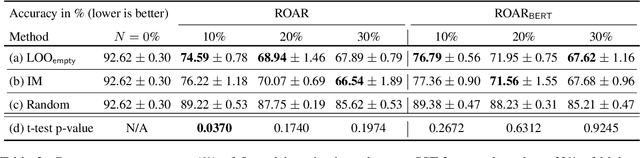

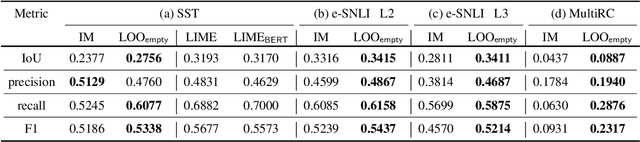
Explaining how important each input feature is to a classifier's decision is critical in high-stake applications. An underlying principle behind dozens of explanation methods is to take the prediction difference between before-and-after an input feature (here, a token) is removed as its attribution - the individual treatment effect in causal inference. A recent method called Input Marginalization (IM) (Kim et al., 2020) uses BERT to replace a token - i.e. simulating the do(.) operator - yielding more plausible counterfactuals. However, our rigorous evaluation using five metrics and on three datasets found IM explanations to be consistently more biased, less accurate, and less plausible than those derived from simply deleting a word.
Few-Shot Intent Detection via Contrastive Pre-Training and Fine-Tuning
Sep 13, 2021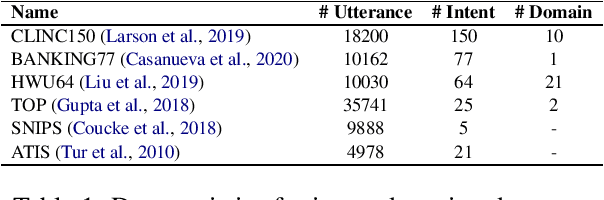
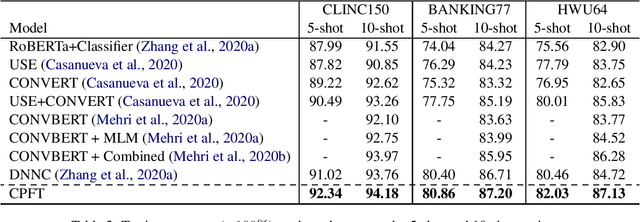

In this work, we focus on a more challenging few-shot intent detection scenario where many intents are fine-grained and semantically similar. We present a simple yet effective few-shot intent detection schema via contrastive pre-training and fine-tuning. Specifically, we first conduct self-supervised contrastive pre-training on collected intent datasets, which implicitly learns to discriminate semantically similar utterances without using any labels. We then perform few-shot intent detection together with supervised contrastive learning, which explicitly pulls utterances from the same intent closer and pushes utterances across different intents farther. Experimental results show that our proposed method achieves state-of-the-art performance on three challenging intent detection datasets under 5-shot and 10-shot settings.
StreamHover: Livestream Transcript Summarization and Annotation
Sep 11, 2021
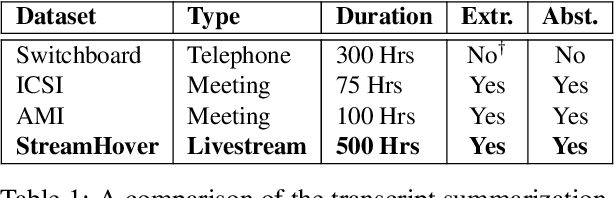

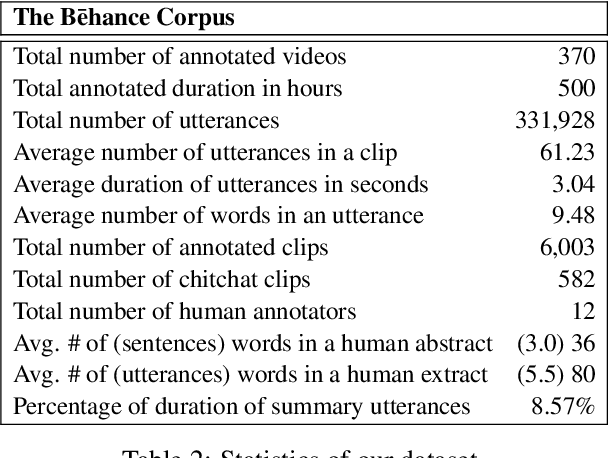
With the explosive growth of livestream broadcasting, there is an urgent need for new summarization technology that enables us to create a preview of streamed content and tap into this wealth of knowledge. However, the problem is nontrivial due to the informal nature of spoken language. Further, there has been a shortage of annotated datasets that are necessary for transcript summarization. In this paper, we present StreamHover, a framework for annotating and summarizing livestream transcripts. With a total of over 500 hours of videos annotated with both extractive and abstractive summaries, our benchmark dataset is significantly larger than currently existing annotated corpora. We explore a neural extractive summarization model that leverages vector-quantized variational autoencoder to learn latent vector representations of spoken utterances and identify salient utterances from the transcripts to form summaries. We show that our model generalizes better and improves performance over strong baselines. The results of this study provide an avenue for future research to improve summarization solutions for efficient browsing of livestreams.
End-to-end Neural Coreference Resolution Revisited: A Simple yet Effective Baseline
Jul 13, 2021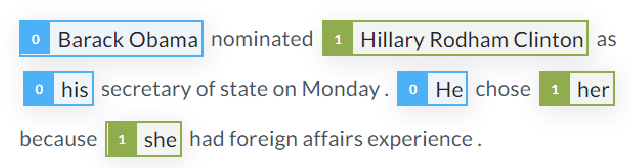

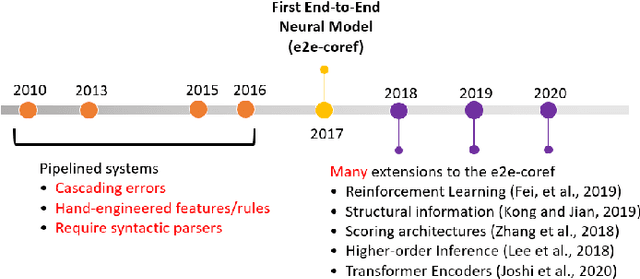

Since the first end-to-end neural coreference resolution model was introduced, many extensions to the model have been proposed, ranging from using higher-order inference to directly optimizing evaluation metrics using reinforcement learning. Despite improving the coreference resolution performance by a large margin, these extensions add a lot of extra complexity to the original model. Motivated by this observation and the recent advances in pre-trained Transformer language models, we propose a simple yet effective baseline for coreference resolution. Our model is a simplified version of the original neural coreference resolution model, however, it achieves impressive performance, outperforming all recent extended works on the public English OntoNotes benchmark. Our work provides evidence for the necessity of carefully justifying the complexity of existing or newly proposed models, as introducing a conceptual or practical simplification to an existing model can still yield competitive results.
UMIC: An Unreferenced Metric for Image Captioning via Contrastive Learning
Jun 26, 2021
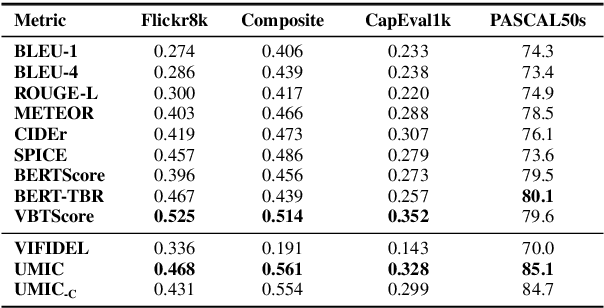
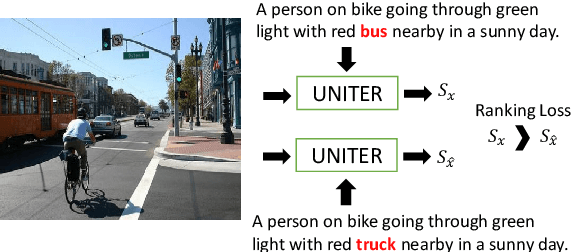

Despite the success of various text generation metrics such as BERTScore, it is still difficult to evaluate the image captions without enough reference captions due to the diversity of the descriptions. In this paper, we introduce a new metric UMIC, an Unreferenced Metric for Image Captioning which does not require reference captions to evaluate image captions. Based on Vision-and-Language BERT, we train UMIC to discriminate negative captions via contrastive learning. Also, we observe critical problems of the previous benchmark dataset (i.e., human annotations) on image captioning metric, and introduce a new collection of human annotations on the generated captions. We validate UMIC on four datasets, including our new dataset, and show that UMIC has a higher correlation than all previous metrics that require multiple references. We release the benchmark dataset and pre-trained models to compute the UMIC.
Learning by Planning: Language-Guided Global Image Editing
Jun 24, 2021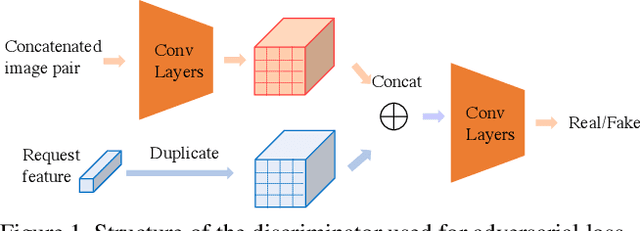
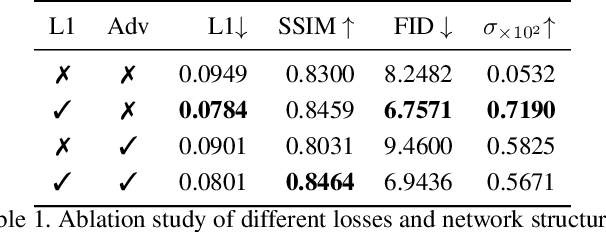
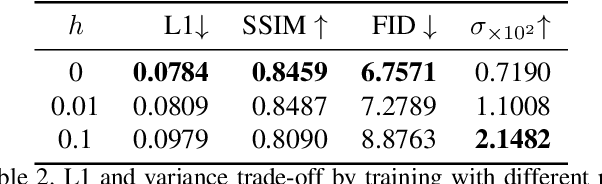

Recently, language-guided global image editing draws increasing attention with growing application potentials. However, previous GAN-based methods are not only confined to domain-specific, low-resolution data but also lacking in interpretability. To overcome the collective difficulties, we develop a text-to-operation model to map the vague editing language request into a series of editing operations, e.g., change contrast, brightness, and saturation. Each operation is interpretable and differentiable. Furthermore, the only supervision in the task is the target image, which is insufficient for a stable training of sequential decisions. Hence, we propose a novel operation planning algorithm to generate possible editing sequences from the target image as pseudo ground truth. Comparison experiments on the newly collected MA5k-Req dataset and GIER dataset show the advantages of our methods. Code is available at https://jshi31.github.io/T2ONet.
X-METRA-ADA: Cross-lingual Meta-Transfer Learning Adaptation to Natural Language Understanding and Question Answering
Apr 20, 2021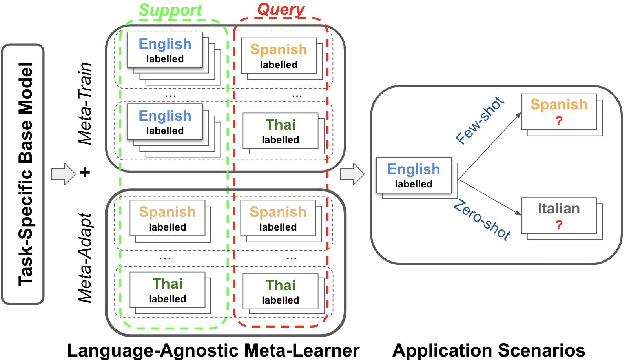
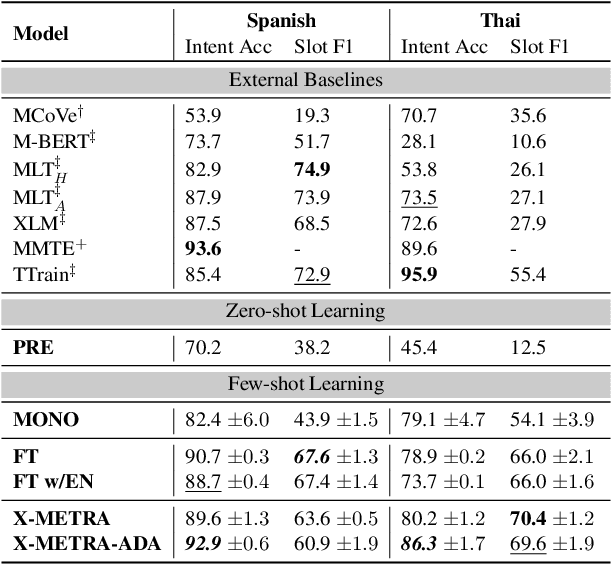
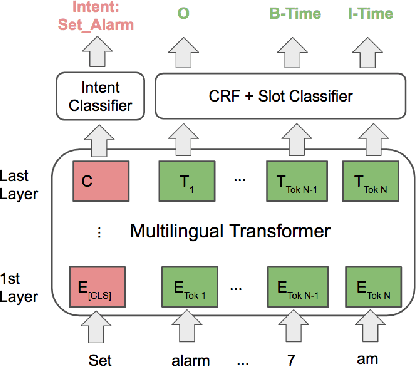
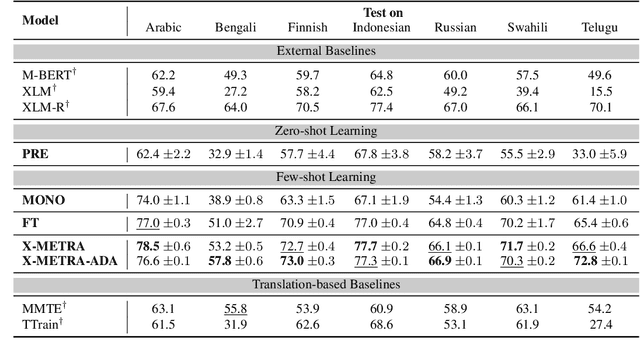
Multilingual models, such as M-BERT and XLM-R, have gained increasing popularity, due to their zero-shot cross-lingual transfer learning capabilities. However, their generalization ability is still inconsistent for typologically diverse languages and across different benchmarks. Recently, meta-learning has garnered attention as a promising technique for enhancing transfer learning under low-resource scenarios: particularly for cross-lingual transfer in Natural Language Understanding (NLU). In this work, we propose X-METRA-ADA, a cross-lingual MEta-TRAnsfer learning ADAptation approach for NLU. Our approach adapts MAML, an optimization-based meta-learning approach, to learn to adapt to new languages. We extensively evaluate our framework on two challenging cross-lingual NLU tasks: multilingual task-oriented dialog and typologically diverse question answering. We show that our approach outperforms naive fine-tuning, reaching competitive performance on both tasks for most languages. Our analysis reveals that X-METRA-ADA can leverage limited data for faster adaptation.