 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Impact of Occupational Personas on Domain-Specific QA
May 30, 2025Recent studies on personas have improved the way Large Language Models (LLMs) interact with users. However, the effect of personas on domain-specific question-answering (QA) tasks remains a subject of debate. This study analyzes whether personas enhance specialized QA performance by introducing two types of persona: Profession-Based Personas (PBPs) (e.g., scientist), which directly relate to domain expertise, and Occupational Personality-Based Personas (OPBPs) (e.g., scientific person), which reflect cognitive tendencies rather than explicit expertise. Through empirical evaluations across multiple scientific domains, we demonstrate that while PBPs can slightly improve accuracy, OPBPs often degrade performance, even when semantically related to the task. Our findings suggest that persona relevance alone does not guarantee effective knowledge utilization and that they may impose cognitive constraints that hinder optimal knowledge application. Future research can explore how nuanced distinctions in persona representations guide LLMs, potentially contributing to reasoning and knowledge retrieval that more closely mirror human social conceptualization.
LLMs Are Globally Multilingual Yet Locally Monolingual: Exploring Knowledge Transfer via Language and Thought Theory
May 30, 2025Multilingual large language models (LLMs) open up new possibilities for leveraging information across languages, but their factual knowledge recall remains inconsistent depending on the input language. While previous studies have attempted to address this issue through English-based prompting and evaluation, we explore non-English to English transfer via Language and Thought Theory. This perspective allows us to examine language-thought binding in LLMs and uncover why factual knowledge often fails to transfer effectively. We propose the Language-to-Thought (L2T) prompting strategy, which analyzes the relationship between input language, internal cognitive processes, and knowledge. Experimental results challenge the assumption that English-based approaches consistently outperform other languages and offer a novel insight that aligning the model's internal thought with the knowledge required for the task is critical for successful cross-lingual transfer. Furthermore, we show that applying L2T during training can alleviate LLMs' reliance on the input language and facilitate cross-linguistic knowledge integration without translation-based learning. Code and datasets will be available.
Causal Reasoning in Large Language Models: A Knowledge Graph Approach
Oct 15, 2024



Large language models (LLMs) typically improve performance by either retrieving semantically similar information, or enhancing reasoning abilities through structured prompts like chain-of-thought. While both strategies are considered crucial, it remains unclear which has a greater impact on model performance or whether a combination of both is necessary. This paper answers this question by proposing a knowledge graph (KG)-based random-walk reasoning approach that leverages causal relationships. We conduct experiments on the commonsense question answering task that is based on a KG. The KG inherently provides both relevant information, such as related entity keywords, and a reasoning structure through the connections between nodes. Experimental results show that the proposed KG-based random-walk reasoning method improves the reasoning ability and performance of LLMs. Interestingly, incorporating three seemingly irrelevant sentences into the query using KG-based random-walk reasoning enhances LLM performance, contrary to conventional wisdom. These findings suggest that integrating causal structures into prompts can significantly improve reasoning capabilities, providing new insights into the role of causality in optimizing LLM performance.
Factual Error Correction for Abstractive Summaries Using Entity Retrieval
Apr 18, 2022
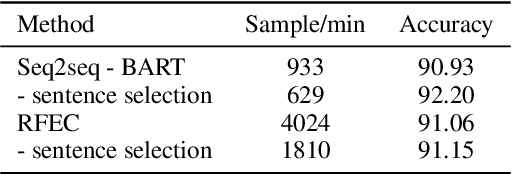
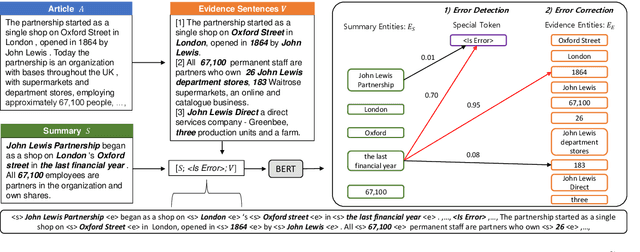
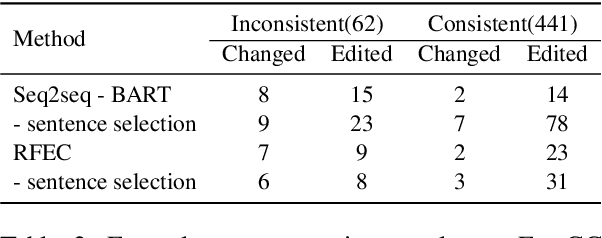
Despite the recent advancements in abstractive summarization systems leveraged from large-scale datasets and pre-trained language models, the factual correctness of the summary is still insufficient. One line of trials to mitigate this problem is to include a post-editing process that can detect and correct factual errors in the summary. In building such a post-editing system, it is strongly required that 1) the process has a high success rate and interpretability and 2) has a fast running time. Previous approaches focus on regeneration of the summary using the autoregressive models, which lack interpretability and require high computing resources. In this paper, we propose an efficient factual error correction system RFEC based on entities retrieval post-editing process. RFEC first retrieves the evidence sentences from the original document by comparing the sentences with the target summary. This approach greatly reduces the length of text for a system to analyze. Next, RFEC detects the entity-level errors in the summaries by considering the evidence sentences and substitutes the wrong entities with the accurate entities from the evidence sentences. Experimental results show that our proposed error correction system shows more competitive performance than baseline methods in correcting the factual errors with a much faster speed.
CrossAug: A Contrastive Data Augmentation Method for Debiasing Fact Verification Models
Sep 30, 2021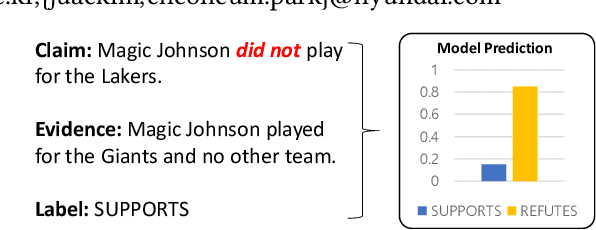
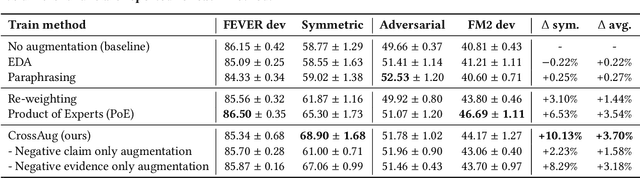
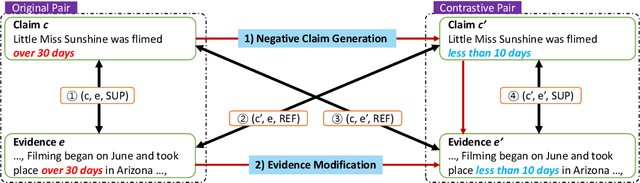
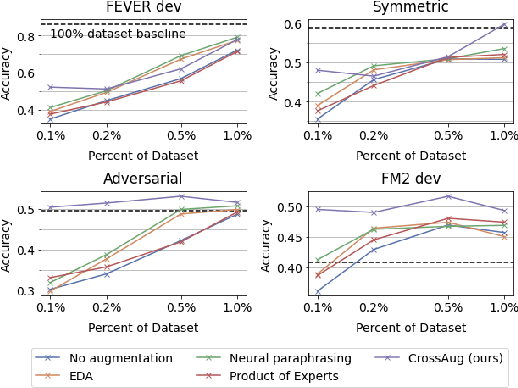
Fact verification datasets are typically constructed using crowdsourcing techniques due to the lack of text sources with veracity labels. However, the crowdsourcing process often produces undesired biases in data that cause models to learn spurious patterns. In this paper, we propose CrossAug, a contrastive data augmentation method for debiasing fact verification models. Specifically, we employ a two-stage augmentation pipeline to generate new claims and evidences from existing samples. The generated samples are then paired cross-wise with the original pair, forming contrastive samples that facilitate the model to rely less on spurious patterns and learn more robust representations. Experimental results show that our method outperforms the previous state-of-the-art debiasing technique by 3.6% on the debiased extension of the FEVER dataset, with a total performance boost of 10.13% from the baseline. Furthermore, we evaluate our approach in data-scarce settings, where models can be more susceptible to biases due to the lack of training data. Experimental results demonstrate that our approach is also effective at debiasing in these low-resource conditions, exceeding the baseline performance on the Symmetric dataset with just 1% of the original data.
ThisIsCompetition at SemEval-2019 Task 9: BERT is unstable for out-of-domain samples
Apr 06, 2019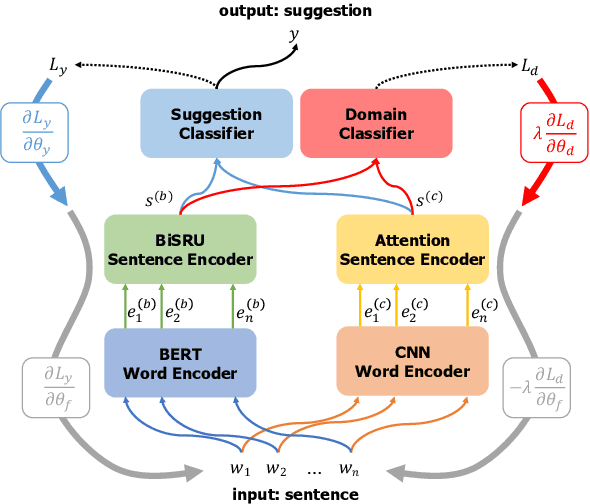
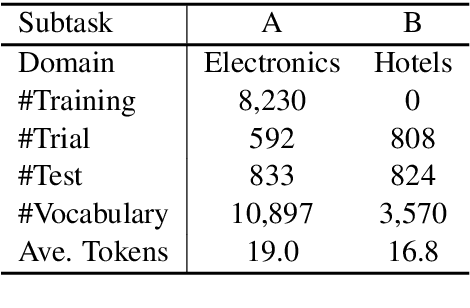
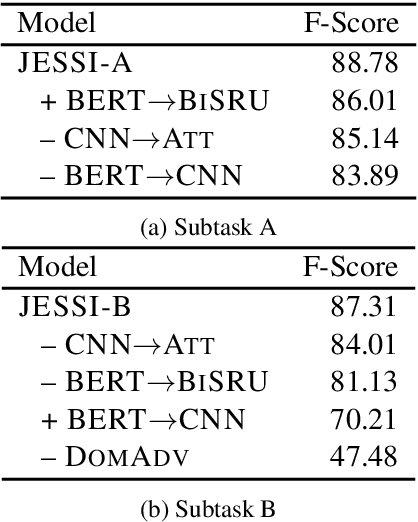
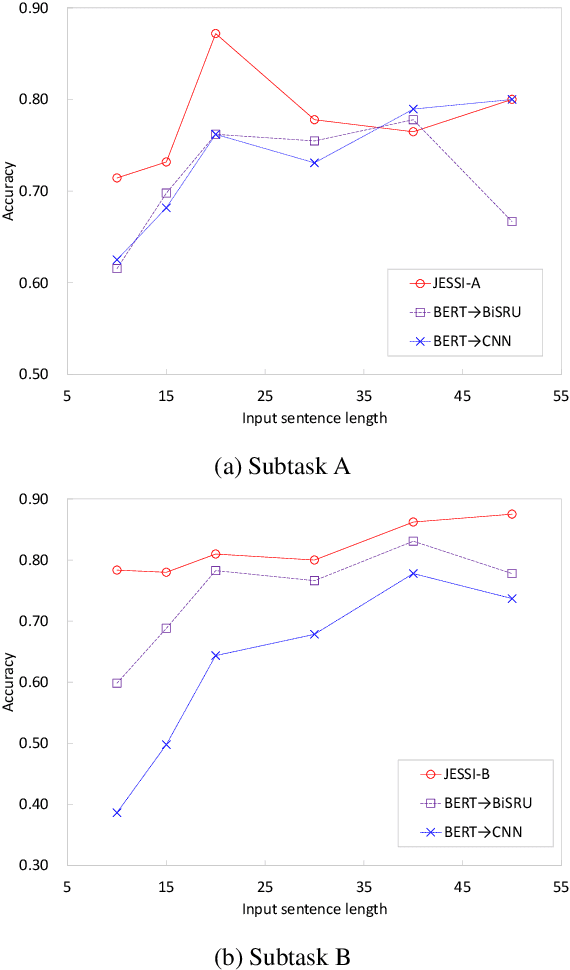
This paper describes our system, Joint Encoders for Stable Suggestion Inference (JESSI), for the SemEval 2019 Task 9: Suggestion Mining from Online Reviews and Forums. JESSI is a combination of two sentence encoders: (a) one using multiple pre-trained word embeddings learned from log-bilinear regression (GloVe) and translation (CoVe) models, and (b) one on top of word encodings from a pre-trained deep bidirectional transformer (BERT). We include a domain adversarial training module when training for out-of-domain samples. Our experiments show that while BERT performs exceptionally well for in-domain samples, several runs of the model show that it is unstable for out-of-domain samples. The problem is mitigated tremendously by (1) combining BERT with a non-BERT encoder, and (2) using an RNN-based classifier on top of BERT. Our final models obtained second place with 77.78\% F-Score on Subtask A (i.e. in-domain) and achieved an F-Score of 79.59\% on Subtask B (i.e. out-of-domain), even without using any additional external data.