 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Long-Term Temporal Dependencies in Photovoltaic Power Output Prediction Through Multi-Horizon Forecasting
May 18, 2026The rapid global expansion of solar photovoltaic (PV) capacity-reaching a record 597 GW in 2024-highlights the urgent need for robust forecasting models to mitigate the grid instability caused by the intermittent nature of solar irradiance. While deep learning-based direct forecasting using ground-based sky images (GSI) has emerged as a dominant approach, existing literature is often constrained by single-architecture evaluations and an exclusive focus on single-horizon (point) prediction. This paper proposes a transition from traditional single-horizon estimation toward a multi-horizon forecasting framework, leading to an architecture-independent improvement in accuracy. We hypothesize and demonstrate experimentally that joint optimization over a sequence of future values allows deep neural networks to better capture latent inter-step temporal dependencies by avoiding precocious convergence of the network in terms of both weight gradients and filter diversity. Leveraging this architecture-independent improvement that integrates sequential sky imagery with historical PV generation data, we evaluate the models' abilities to predict power output across multiple discrete future time steps simultaneously. Our methodology is validated through a comparative analysis across diverse deep learning architectures. The results demonstrate that this multi-horizon approach significantly enhances predictive accuracy and robustness across the entire forecast horizon while maintaining computational parsimony. By achieving superior performance with negligible overhead compared to single-horizon models, this work provides a scalable and efficient solution to improve the resilience of modern power grids.
INTERPOS: Interaction Rhythm Guided Positional Morphing for Mobile App Recommender Systems
Jun 14, 2025The mobile app market has expanded exponentially, offering millions of apps with diverse functionalities, yet research in mobile app recommendation remains limited. Traditional sequential recommender systems utilize the order of items in users' historical interactions to predict the next item for the users. Position embeddings, well-established in transformer-based architectures for natural language processing tasks, effectively distinguish token positions in sequences. In sequential recommendation systems, position embeddings can capture the order of items in a user's historical interaction sequence. Nevertheless, this ordering does not consider the time elapsed between two interactions of the same user (e.g., 1 day, 1 week, 1 month), referred to as "user rhythm". In mobile app recommendation datasets, the time between consecutive user interactions is notably longer compared to other domains like movies, posing significant challenges for sequential recommender systems. To address this phenomenon in the mobile app domain, we introduce INTERPOS, an Interaction Rhythm Guided Positional Morphing strategy for autoregressive mobile app recommender systems. INTERPOS incorporates rhythm-guided position embeddings, providing a more comprehensive representation that considers both the sequential order of interactions and the temporal gaps between them. This approach enables a deep understanding of users' rhythms at a fine-grained level, capturing the intricacies of their interaction patterns over time. We propose three strategies to incorporate the morphed positional embeddings in two transformer-based sequential recommendation system architectures. Our extensive evaluations show that INTERPOS outperforms state-of-the-art models using 7 mobile app recommendation datasets on NDCG@K and HIT@K metrics. The source code of INTERPOS is available at https://github.com/dlgrad/INTERPOS.
* 10 pages, 8 tables, 3 figures
STRUX: An LLM for Decision-Making with Structured Explanations
Oct 16, 2024Countless decisions shape our daily lives, and it is paramount to understand the how and why behind these choices. In this paper, we introduce a new LLM decision-making framework called STRUX, which enhances LLM decision-making by providing structured explanations. These include favorable and adverse facts related to the decision, along with their respective strengths. STRUX begins by distilling lengthy information into a concise table of key facts. It then employs a series of self-reflection steps to determine which of these facts are pivotal, categorizing them as either favorable or adverse in relation to a specific decision. Lastly, we fine-tune an LLM to identify and prioritize these key facts to optimize decision-making. STRUX has been evaluated on the challenging task of forecasting stock investment decisions based on earnings call transcripts and demonstrated superior performance against strong baselines. It enhances decision transparency by allowing users to understand the impact of different factors, representing a meaningful step towards practical decision-making with LLMs.
DeFine: Enhancing LLM Decision-Making with Factor Profiles and Analogical Reasoning
Oct 02, 2024



LLMs are ideal for decision-making due to their ability to reason over long contexts and identify critical factors. However, challenges arise when processing transcripts of spoken speech describing complex scenarios. These transcripts often contain ungrammatical or incomplete sentences, repetitions, hedging, and vagueness. For example, during a company's earnings call, an executive might project a positive revenue outlook to reassure investors, despite significant uncertainty regarding future earnings. It is crucial for LLMs to incorporate this uncertainty systematically when making decisions. In this paper, we introduce DeFine, a new framework that constructs probabilistic factor profiles from complex scenarios. DeFine then integrates these profiles with analogical reasoning, leveraging insights from similar past experiences to guide LLMs in making critical decisions in novel situations. Our framework separates the tasks of quantifying uncertainty in complex scenarios and incorporating it into LLM decision-making. This approach is particularly useful in fields such as medical consultations, negotiations, and political debates, where making decisions under uncertainty is vital.
When Reasoning Meets Information Aggregation: A Case Study with Sports Narratives
Jun 17, 2024



Reasoning is most powerful when an LLM accurately aggregates relevant information. We examine the critical role of information aggregation in reasoning by requiring the LLM to analyze sports narratives. To succeed at this task, an LLM must infer points from actions, identify related entities, attribute points accurately to players and teams, and compile key statistics to draw conclusions. We conduct comprehensive experiments with real NBA basketball data and present SportsGen, a new method to synthesize game narratives. By synthesizing data, we can rigorously evaluate LLMs' reasoning capabilities under complex scenarios with varying narrative lengths and density of information. Our findings show that most models, including GPT-4o, often fail to accurately aggregate basketball scores due to frequent scoring patterns. Open-source models like Llama-3 further suffer from significant score hallucinations. Finally, the effectiveness of reasoning is influenced by narrative complexity, information density, and domain-specific terms, highlighting the challenges in analytical reasoning tasks.
Can Large Language Models do Analytical Reasoning?
Mar 06, 2024

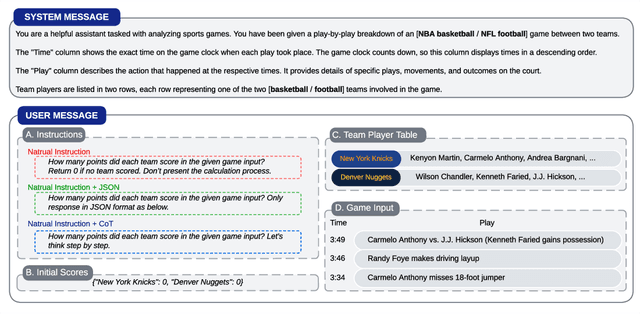
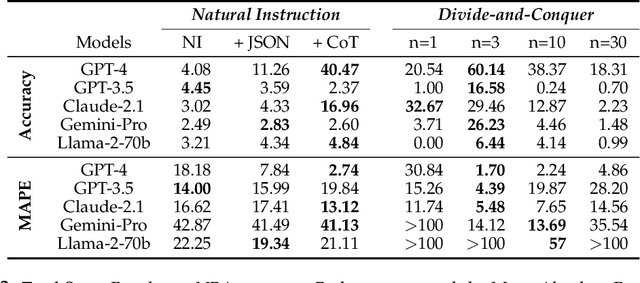
This paper explores the cutting-edge Large Language Model with analytical reasoning on sports. Our analytical reasoning embodies the tasks of letting large language models count how many points each team scores in a quarter in the NBA and NFL games. Our major discoveries are in two folds. Firstly, we find among all the models we employed, GPT-4 stands out in effectiveness, followed by Claude-2.1, with GPT-3.5, Gemini-Pro, and Llama-2-70b lagging behind. Specifically, we compare three different prompting techniques and a divide-and-conquer approach, we find that the latter was the most effective. Our divide-and-conquer approach breaks down play-by-play data into smaller, more manageable segments, solves each piece individually, and then aggregates them together. Besides the divide-and-conquer approach, we also explore the Chain of Thought (CoT) strategy, which markedly improves outcomes for certain models, notably GPT-4 and Claude-2.1, with their accuracy rates increasing significantly. However, the CoT strategy has negligible or even detrimental effects on the performance of other models like GPT-3.5 and Gemini-Pro. Secondly, to our surprise, we observe that most models, including GPT-4, struggle to accurately count the total scores for NBA quarters despite showing strong performance in counting NFL quarter scores. This leads us to further investigate the factors that impact the complexity of analytical reasoning tasks with extensive experiments, through which we conclude that task complexity depends on the length of context, the information density, and the presence of related information. Our research provides valuable insights into the complexity of analytical reasoning tasks and potential directions for developing future large language models.
SportsMetrics: Blending Text and Numerical Data to Understand Information Fusion in LLMs
Feb 15, 2024Large language models hold significant potential for integrating various data types, such as text documents and database records, for advanced analytics. However, blending text and numerical data presents substantial challenges. LLMs need to process and cross-reference entities and numbers, handle data inconsistencies and redundancies, and develop planning capabilities such as building a working memory for managing complex data queries. In this paper, we introduce four novel tasks centered around sports data analytics to evaluate the numerical reasoning and information fusion capabilities of LLMs. These tasks involve providing LLMs with detailed, play-by-play sports game descriptions, then challenging them with adversarial scenarios such as new game rules, longer durations, scrambled narratives, and analyzing key statistics in game summaries. We conduct extensive experiments on NBA and NFL games to assess the performance of LLMs on these tasks. Our benchmark, SportsMetrics, introduces a new mechanism for assessing LLMs' numerical reasoning and fusion skills.
LPFormer: LiDAR Pose Estimation Transformer with Multi-Task Network
Jun 21, 2023



In this technical report, we present the 1st place solution for the 2023 Waymo Open Dataset Pose Estimation challenge. Due to the difficulty of acquiring large-scale 3D human keypoint annotation, previous methods have commonly relied on 2D image features and 2D sequential annotations for 3D human pose estimation. In contrast, our proposed method, named LPFormer, uses only LiDAR as its input along with its corresponding 3D annotations. LPFormer consists of two stages: the first stage detects the human bounding box and extracts multi-level feature representations, while the second stage employs a transformer-based network to regress the human keypoints using these features. Experimental results on the Waymo Open Dataset demonstrate the top performance, and improvements even compared to previous multi-modal solutions.
MeetingBank: A Benchmark Dataset for Meeting Summarization
May 27, 2023As the number of recorded meetings increases, it becomes increasingly important to utilize summarization technology to create useful summaries of these recordings. However, there is a crucial lack of annotated meeting corpora for developing this technology, as it can be hard to collect meetings, especially when the topics discussed are confidential. Furthermore, meeting summaries written by experienced writers are scarce, making it hard for abstractive summarizers to produce sensible output without a reliable reference. This lack of annotated corpora has hindered the development of meeting summarization technology. In this paper, we present MeetingBank, a new benchmark dataset of city council meetings over the past decade. MeetingBank is unique among other meeting corpora due to its divide-and-conquer approach, which involves dividing professionally written meeting minutes into shorter passages and aligning them with specific segments of the meeting. This breaks down the process of summarizing a lengthy meeting into smaller, more manageable tasks. The dataset provides a new testbed of various meeting summarization systems and also allows the public to gain insight into how council decisions are made. We make the collection, including meeting video links, transcripts, reference summaries, agenda, and other metadata, publicly available to facilitate the development of better meeting summarization techniques. Our dataset can be accessed at: https://meetingbank.github.io
Analyzing Influential Factors in Human Preference Judgments via GPT-4
May 24, 2023Pairwise human judgments are pivotal in guiding large language models (LLMs) to generate outputs that align with human preferences. They are also often used in summarization evaluation, complementing existing automatic metrics. Despite their significance, however, there has been limited research probing these pairwise human judgments. The collective impact and respective weights of factors such as informativeness, coherence, fluency, and factual consistency remain elusive. The impact of hidden factors on the final judgment is also unclear. In this paper, we conduct an in-depth examination of a dataset of pairwise human judgments released by OpenAI. Utilizing the Bradley-Terry-Luce model, we identify key factors that could potentially influence human judgments. Our research uncovers the inherent preferences embedded in human judgments and suggests strategies to boost sample efficiency. Finally, we provide insights on the construction of balanced datasets for human judgment evaluations, a crucial step in shaping the behaviors of future LLMs.