 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritizing Image-Related Tokens Enhances Vision-Language Pre-Training
May 13, 2025



In standard large vision-language models (LVLMs) pre-training, the model typically maximizes the joint probability of the caption conditioned on the image via next-token prediction (NTP); however, since only a small subset of caption tokens directly relates to the visual content, this naive NTP unintentionally fits the model to noise and increases the risk of hallucination. We present PRIOR, a simple vision-language pre-training approach that addresses this issue by prioritizing image-related tokens through differential weighting in the NTP loss, drawing from the importance sampling framework. PRIOR introduces a reference model-a text-only large language model (LLM) trained on the captions without image inputs, to weight each token based on its probability for LVLMs training. Intuitively, tokens that are directly related to the visual inputs are harder to predict without the image and thus receive lower probabilities from the text-only reference LLM. During training, we implement a token-specific re-weighting term based on the importance scores to adjust each token's loss. We implement PRIOR in two distinct settings: LVLMs with visual encoders and LVLMs without visual encoders. We observe 19% and 8% average relative improvement, respectively, on several vision-language benchmarks compared to NTP. In addition, PRIOR exhibits superior scaling properties, as demonstrated by significantly higher scaling coefficients, indicating greater potential for performance gains compared to NTP given increasing compute and data.
HuB: Learning Extreme Humanoid Balance
May 12, 2025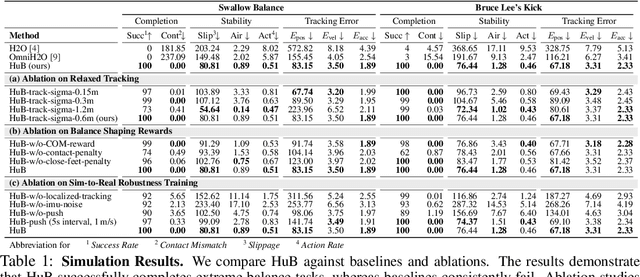
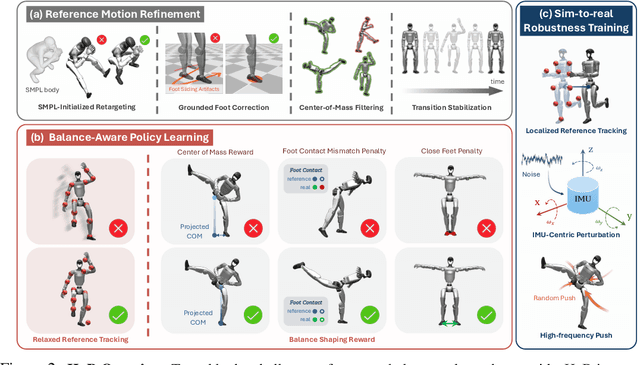
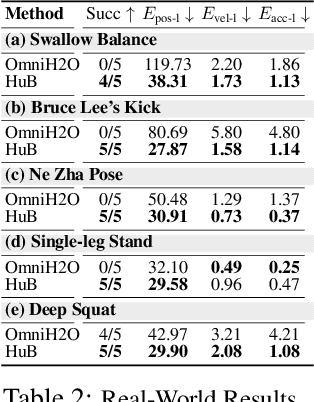
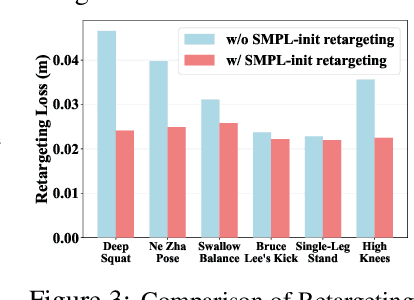
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io
DeepSORT-Driven Visual Tracking Approach for Gesture Recognition in Interactive Systems
May 11, 2025Based on the DeepSORT algorithm, this study explores the application of visual tracking technology in intelligent human-computer interaction, especially in the field of gesture recognition and tracking. With the rapid development of artificial intelligence and deep learning technology, visual-based interaction has gradually replaced traditional input devices and become an important way for intelligent systems to interact with users. The DeepSORT algorithm can achieve accurate target tracking in dynamic environments by combining Kalman filters and deep learning feature extraction methods. It is especially suitable for complex scenes with multi-target tracking and fast movements. This study experimentally verifies the superior performance of DeepSORT in gesture recognition and tracking. It can accurately capture and track the user's gesture trajectory and is superior to traditional tracking methods in terms of real-time and accuracy. In addition, this study also combines gesture recognition experiments to evaluate the recognition ability and feedback response of the DeepSORT algorithm under different gestures (such as sliding, clicking, and zooming). The experimental results show that DeepSORT can not only effectively deal with target occlusion and motion blur but also can stably track in a multi-target environment, achieving a smooth user interaction experience. Finally, this paper looks forward to the future development direction of intelligent human-computer interaction systems based on visual tracking and proposes future research focuses such as algorithm optimization, data fusion, and multimodal interaction in order to promote a more intelligent and personalized interactive experience. Keywords-DeepSORT, visual tracking, gesture recognition, human-computer interaction
RM-R1: Reward Modeling as Reasoning
May 05, 2025Reward modeling is essential for aligning large language models (LLMs) with human preferences, especially through reinforcement learning from human feedback (RLHF). To provide accurate reward signals, a reward model (RM) should stimulate deep thinking and conduct interpretable reasoning before assigning a score or a judgment. However, existing RMs either produce opaque scalar scores or directly generate the prediction of a preferred answer, making them struggle to integrate natural language critiques, thus lacking interpretability. Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RM's interpretability and performance. In this work, we introduce a new class of generative reward models -- Reasoning Reward Models (ReasRMs) -- which formulate reward modeling as a reasoning task. We propose a reasoning-oriented training pipeline and train a family of ReasRMs, RM-R1. The training consists of two key stages: (1) distillation of high-quality reasoning chains and (2) reinforcement learning with verifiable rewards. RM-R1 improves LLM rollouts by self-generating reasoning traces or chat-specific rubrics and evaluating candidate responses against them. Empirically, our models achieve state-of-the-art or near state-of-the-art performance of generative RMs across multiple comprehensive reward model benchmarks, outperforming much larger open-weight models (e.g., Llama3.1-405B) and proprietary ones (e.g., GPT-4o) by up to 13.8%. Beyond final performance, we perform thorough empirical analysis to understand the key ingredients of successful ReasRM training. To facilitate future research, we release six ReasRM models along with code and data at https://github.com/RM-R1-UIUC/RM-R1.
Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL
May 05, 2025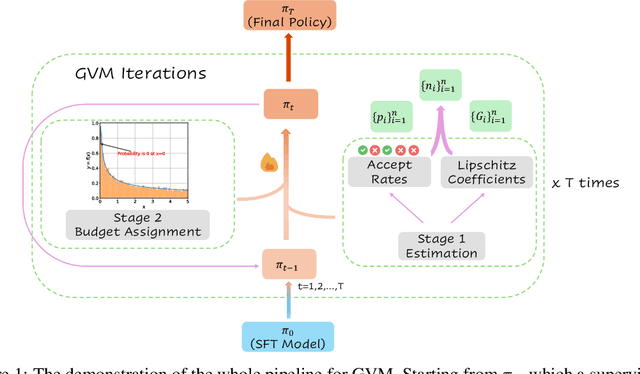
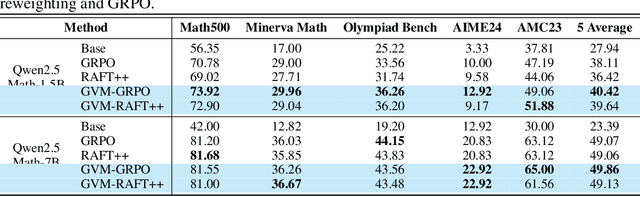
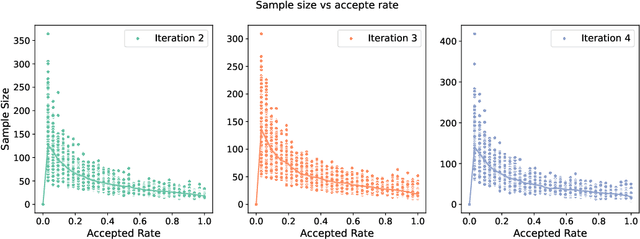
Chain-of-thought (CoT) reasoning in large language models (LLMs) can be formalized as a latent variable problem, where the model needs to generate intermediate reasoning steps. While prior approaches such as iterative reward-ranked fine-tuning (RAFT) have relied on such formulations, they typically apply uniform inference budgets across prompts, which fails to account for variability in difficulty and convergence behavior. This work identifies the main bottleneck in CoT training as inefficient stochastic gradient estimation due to static sampling strategies. We propose GVM-RAFT, a prompt-specific Dynamic Sample Allocation Strategy designed to minimize stochastic gradient variance under a computational budget constraint. The method dynamically allocates computational resources by monitoring prompt acceptance rates and stochastic gradient norms, ensuring that the resulting gradient variance is minimized. Our theoretical analysis shows that the proposed dynamic sampling strategy leads to accelerated convergence guarantees under suitable conditions. Experiments on mathematical reasoning show that GVM-RAFT achieves a 2-4x speedup and considerable accuracy improvements over vanilla RAFT. The proposed dynamic sampling strategy is general and can be incorporated into other reinforcement learning algorithms, such as GRPO, leading to similar improvements in convergence and test accuracy. Our code is available at https://github.com/RLHFlow/GVM.
Multi-Step Consistency Models: Fast Generation with Theoretical Guarantees
May 02, 2025Consistency models have recently emerged as a compelling alternative to traditional SDE based diffusion models, offering a significant acceleration in generation by producing high quality samples in very few steps. Despite their empirical success, a proper theoretic justification for their speed up is still lacking. In this work, we provide the analysis which bridges this gap, showing that given a consistency model which can map the input at a given time to arbitrary timestamps along the reverse trajectory, one can achieve KL divergence of order $ O(\varepsilon^2) $ using only $ O\left(\log\left(\frac{d}{\varepsilon}\right)\right) $ iterations with constant step size, where d is the data dimension. Additionally, under minimal assumptions on the data distribution an increasingly common setting in recent diffusion model analyses we show that a similar KL convergence guarantee can be obtained, with the number of steps scaling as $ O\left(d \log\left(\frac{d}{\varepsilon}\right)\right) $. Going further, we also provide a theoretical analysis for estimation of such consistency models, concluding that accurate learning is feasible using small discretization steps, both in smooth and non smooth settings. Notably, our results for the non smooth case yield best in class convergence rates compared to existing SDE or ODE based analyses under minimal assumptions.
MIMIC-\RNum{4}-Ext-22MCTS: A 22 Millions-Event Temporal Clinical Time-Series Dataset with Relative Timestamp for Risk Prediction
May 01, 2025



Clinical risk prediction based on machine learning algorithms plays a vital role in modern healthcare. A crucial component in developing a reliable prediction model is collecting high-quality time series clinical events. In this work, we release such a dataset that consists of 22,588,586 Clinical Time Series events, which we term MIMIC-\RNum{4}-Ext-22MCTS. Our source data are discharge summaries selected from the well-known yet unstructured MIMIC-IV-Note \cite{Johnson2023-pg}. We then extract clinical events as short text span from the discharge summaries, along with the timestamps of these events as temporal information. The general-purpose MIMIC-IV-Note pose specific challenges for our work: it turns out that the discharge summaries are too lengthy for typical natural language models to process, and the clinical events of interest often are not accompanied with explicit timestamps. Therefore, we propose a new framework that works as follows: 1) we break each discharge summary into manageably small text chunks; 2) we apply contextual BM25 and contextual semantic search to retrieve chunks that have a high potential of containing clinical events; and 3) we carefully design prompts to teach the recently released Llama-3.1-8B \cite{touvron2023llama} model to identify or infer temporal information of the chunks. We show that the obtained dataset is so informative and transparent that standard models fine-tuned on our dataset are achieving significant improvements in healthcare applications. In particular, the BERT model fine-tuned based on our dataset achieves 10\% improvement in accuracy on medical question answering task, and 3\% improvement in clinical trial matching task compared with the classic BERT. The GPT-2 model, fine-tuned on our dataset, produces more clinically reliable results for clinical questions.
Capturing Conditional Dependence via Auto-regressive Diffusion Models
Apr 30, 2025Diffusion models have demonstrated appealing performance in both image and video generation. However, many works discover that they struggle to capture important, high-level relationships that are present in the real world. For example, they fail to learn physical laws from data, and even fail to understand that the objects in the world exist in a stable fashion. This is due to the fact that important conditional dependence structures are not adequately captured in the vanilla diffusion models. In this work, we initiate an in-depth study on strengthening the diffusion model to capture the conditional dependence structures in the data. In particular, we examine the efficacy of the auto-regressive (AR) diffusion models for such purpose and develop the first theoretical results on the sampling error of AR diffusion models under (possibly) the mildest data assumption. Our theoretical findings indicate that, compared with typical diffusion models, the AR variant produces samples with a reduced gap in approximating the data conditional distribution. On the other hand, the overall inference time of the AR-diffusion models is only moderately larger than that for the vanilla diffusion models, making them still practical for large scale applications. We also provide empirical results showing that when there is clear conditional dependence structure in the data, the AR diffusion models captures such structure, whereas vanilla DDPM fails to do so. On the other hand, when there is no obvious conditional dependence across patches of the data, AR diffusion does not outperform DDPM.
STCL:Curriculum learning Strategies for deep learning image steganography models
Apr 24, 2025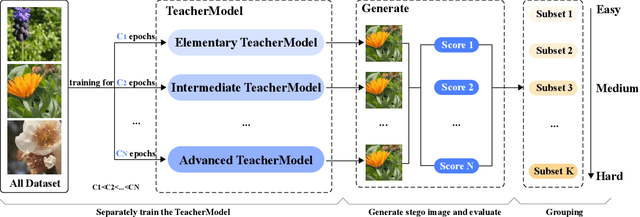
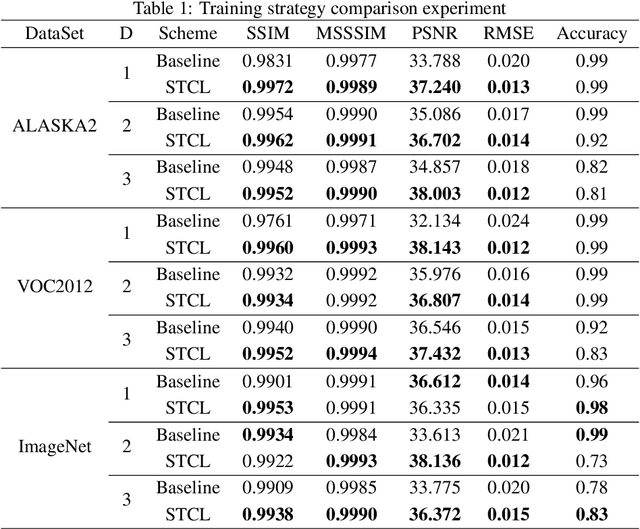


Aiming at the problems of poor quality of steganographic images and slow network convergence of image steganography models based on deep learning, this paper proposes a Steganography Curriculum Learning training strategy (STCL) for deep learning image steganography models. So that only easy images are selected for training when the model has poor fitting ability at the initial stage, and gradually expand to more difficult images, the strategy includes a difficulty evaluation strategy based on the teacher model and an knee point-based training scheduling strategy. Firstly, multiple teacher models are trained, and the consistency of the quality of steganographic images under multiple teacher models is used as the difficulty score to construct the training subsets from easy to difficult. Secondly, a training control strategy based on knee points is proposed to reduce the possibility of overfitting on small training sets and accelerate the training process. Experimental results on three large public datasets, ALASKA2, VOC2012 and ImageNet, show that the proposed image steganography scheme is able to improve the model performance under multiple algorithmic frameworks, which not only has a high PSNR, SSIM score, and decoding accuracy, but also the steganographic images generated by the model under the training of the STCL strategy have a low steganography analysis scores. You can find our code at \href{https://github.com/chaos-boops/STCL}{https://github.com/chaos-boops/STCL}.
MMHCL: Multi-Modal Hypergraph Contrastive Learning for Recommendation
Apr 23, 2025The burgeoning presence of multimodal content-sharing platforms propels the development of personalized recommender systems. Previous works usually suffer from data sparsity and cold-start problems, and may fail to adequately explore semantic user-product associations from multimodal data. To address these issues, we propose a novel Multi-Modal Hypergraph Contrastive Learning (MMHCL) framework for user recommendation. For a comprehensive information exploration from user-product relations, we construct two hypergraphs, i.e. a user-to-user (u2u) hypergraph and an item-to-item (i2i) hypergraph, to mine shared preferences among users and intricate multimodal semantic resemblance among items, respectively. This process yields denser second-order semantics that are fused with first-order user-item interaction as complementary to alleviate the data sparsity issue. Then, we design a contrastive feature enhancement paradigm by applying synergistic contrastive learning. By maximizing/minimizing the mutual information between second-order (e.g. shared preference pattern for users) and first-order (information of selected items for users) embeddings of the same/different users and items, the feature distinguishability can be effectively enhanced. Compared with using sparse primary user-item interaction only, our MMHCL obtains denser second-order hypergraphs and excavates more abundant shared attributes to explore the user-product associations, which to a certain extent alleviates the problems of data sparsity and cold-start. Extensive experiments have comprehensively demonstrated the effectiveness of our method. Our code is publicly available at: https://github.com/Xu107/MMHCL.