 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLM-E: An Embodied Multimodal Language Model
Mar 06, 2023



Large language models excel at a wide range of complex tasks. However, enabling general inference in the real world, e.g., for robotics problems, raises the challenge of grounding. We propose embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to our embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings. We train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks including sequential robotic manipulation planning, visual question answering, and captioning. Our evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains. Our largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.
Offline Imitation Learning with Suboptimal Demonstrations via Relaxed Distribution Matching
Mar 05, 2023



Offline imitation learning (IL) promises the ability to learn performant policies from pre-collected demonstrations without interactions with the environment. However, imitating behaviors fully offline typically requires numerous expert data. To tackle this issue, we study the setting where we have limited expert data and supplementary suboptimal data. In this case, a well-known issue is the distribution shift between the learned policy and the behavior policy that collects the offline data. Prior works mitigate this issue by regularizing the KL divergence between the stationary state-action distributions of the learned policy and the behavior policy. We argue that such constraints based on exact distribution matching can be overly conservative and hamper policy learning, especially when the imperfect offline data is highly suboptimal. To resolve this issue, we present RelaxDICE, which employs an asymmetrically-relaxed f-divergence for explicit support regularization. Specifically, instead of driving the learned policy to exactly match the behavior policy, we impose little penalty whenever the density ratio between their stationary state-action distributions is upper bounded by a constant. Note that such formulation leads to a nested min-max optimization problem, which causes instability in practice. RelaxDICE addresses this challenge by supporting a closed-form solution for the inner maximization problem. Extensive empirical study shows that our method significantly outperforms the best prior offline IL method in six standard continuous control environments with over 30% performance gain on average, across 22 settings where the imperfect dataset is highly suboptimal.
Scaling Robot Learning with Semantically Imagined Experience
Feb 22, 2023



Recent advances in robot learning have shown promise in enabling robots to perform a variety of manipulation tasks and generalize to novel scenarios. One of the key contributing factors to this progress is the scale of robot data used to train the models. To obtain large-scale datasets, prior approaches have relied on either demonstrations requiring high human involvement or engineering-heavy autonomous data collection schemes, both of which are challenging to scale. To mitigate this issue, we propose an alternative route and leverage text-to-image foundation models widely used in computer vision and natural language processing to obtain meaningful data for robot learning without requiring additional robot data. We term our method Robot Learning with Semantically Imagened Experience (ROSIE). Specifically, we make use of the state of the art text-to-image diffusion models and perform aggressive data augmentation on top of our existing robotic manipulation datasets via inpainting various unseen objects for manipulation, backgrounds, and distractors with text guidance. Through extensive real-world experiments, we show that manipulation policies trained on data augmented this way are able to solve completely unseen tasks with new objects and can behave more robustly w.r.t. novel distractors. In addition, we find that we can improve the robustness and generalization of high-level robot learning tasks such as success detection through training with the diffusion-based data augmentation. The project's website and videos can be found at diffusion-rosie.github.io
RT-1: Robotics Transformer for Real-World Control at Scale
Dec 13, 2022



By transferring knowledge from large, diverse, task-agnostic datasets, modern machine learning models can solve specific downstream tasks either zero-shot or with small task-specific datasets to a high level of performance. While this capability has been demonstrated in other fields such as computer vision, natural language processing or speech recognition, it remains to be shown in robotics, where the generalization capabilities of the models are particularly critical due to the difficulty of collecting real-world robotic data. We argue that one of the keys to the success of such general robotic models lies with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the diverse, robotic data. In this paper, we present a model class, dubbed Robotics Transformer, that exhibits promising scalable model properties. We verify our conclusions in a study of different model classes and their ability to generalize as a function of the data size, model size, and data diversity based on a large-scale data collection on real robots performing real-world tasks. The project's website and videos can be found at robotics-transformer.github.io
Offline Reinforcement Learning at Multiple Frequencies
Jul 26, 2022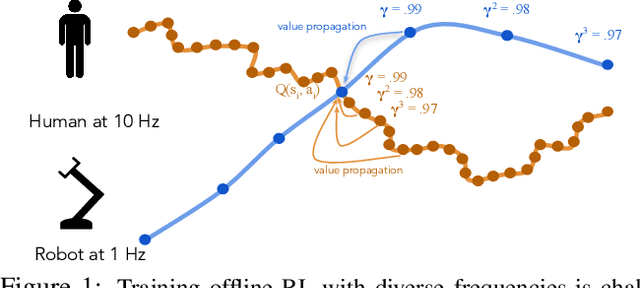
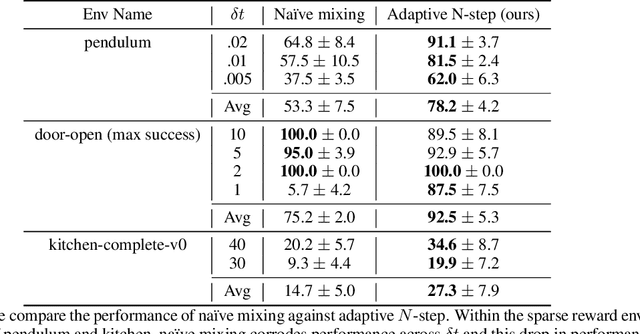

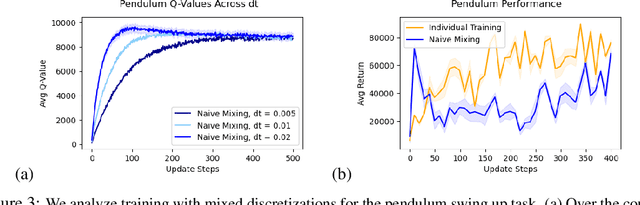
Leveraging many sources of offline robot data requires grappling with the heterogeneity of such data. In this paper, we focus on one particular aspect of heterogeneity: learning from offline data collected at different control frequencies. Across labs, the discretization of controllers, sampling rates of sensors, and demands of a task of interest may differ, giving rise to a mixture of frequencies in an aggregated dataset. We study how well offline reinforcement learning (RL) algorithms can accommodate data with a mixture of frequencies during training. We observe that the $Q$-value propagates at different rates for different discretizations, leading to a number of learning challenges for off-the-shelf offline RL. We present a simple yet effective solution that enforces consistency in the rate of $Q$-value updates to stabilize learning. By scaling the value of $N$ in $N$-step returns with the discretization size, we effectively balance $Q$-value propagation, leading to more stable convergence. On three simulated robotic control problems, we empirically find that this simple approach outperforms na\"ive mixing by 50% on average.
Latent-Variable Advantage-Weighted Policy Optimization for Offline RL
Mar 16, 2022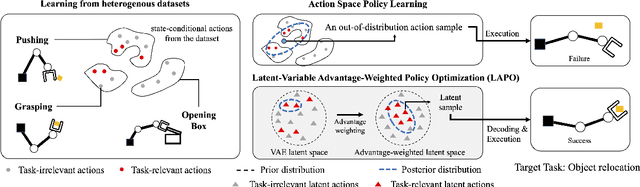
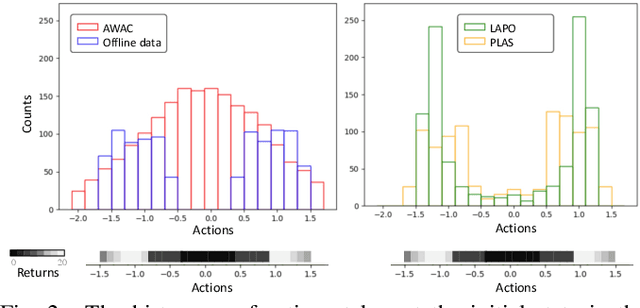

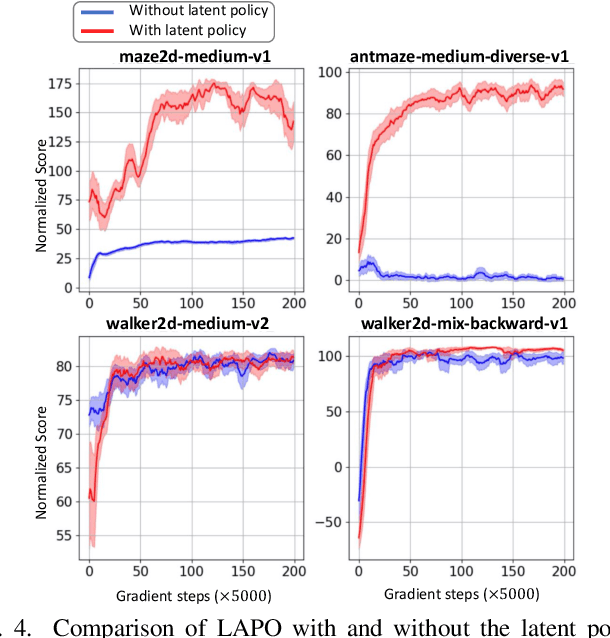
Offline reinforcement learning methods hold the promise of learning policies from pre-collected datasets without the need to query the environment for new transitions. This setting is particularly well-suited for continuous control robotic applications for which online data collection based on trial-and-error is costly and potentially unsafe. In practice, offline datasets are often heterogeneous, i.e., collected in a variety of scenarios, such as data from several human demonstrators or from policies that act with different purposes. Unfortunately, such datasets can exacerbate the distribution shift between the behavior policy underlying the data and the optimal policy to be learned, leading to poor performance. To address this challenge, we propose to leverage latent-variable policies that can represent a broader class of policy distributions, leading to better adherence to the training data distribution while maximizing reward via a policy over the latent variable. As we empirically show on a range of simulated locomotion, navigation, and manipulation tasks, our method referred to as latent-variable advantage-weighted policy optimization (LAPO), improves the average performance of the next best-performing offline reinforcement learning methods by 49% on heterogeneous datasets, and by 8% on datasets with narrow and biased distributions.
How to Leverage Unlabeled Data in Offline Reinforcement Learning
Feb 03, 2022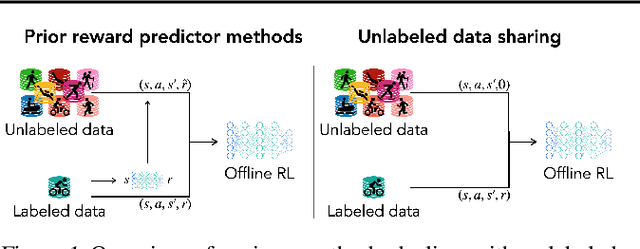
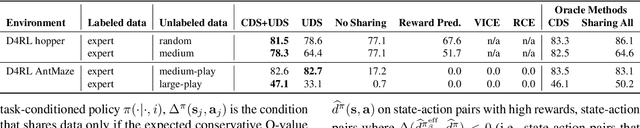


Offline reinforcement learning (RL) can learn control policies from static datasets but, like standard RL methods, it requires reward annotations for every transition. In many cases, labeling large datasets with rewards may be costly, especially if those rewards must be provided by human labelers, while collecting diverse unlabeled data might be comparatively inexpensive. How can we best leverage such unlabeled data in offline RL? One natural solution is to learn a reward function from the labeled data and use it to label the unlabeled data. In this paper, we find that, perhaps surprisingly, a much simpler method that simply applies zero rewards to unlabeled data leads to effective data sharing both in theory and in practice, without learning any reward model at all. While this approach might seem strange (and incorrect) at first, we provide extensive theoretical and empirical analysis that illustrates how it trades off reward bias, sample complexity and distributional shift, often leading to good results. We characterize conditions under which this simple strategy is effective, and further show that extending it with a simple reweighting approach can further alleviate the bias introduced by using incorrect reward labels. Our empirical evaluation confirms these findings in simulated robotic locomotion, navigation, and manipulation settings.
Conservative Data Sharing for Multi-Task Offline Reinforcement Learning
Sep 16, 2021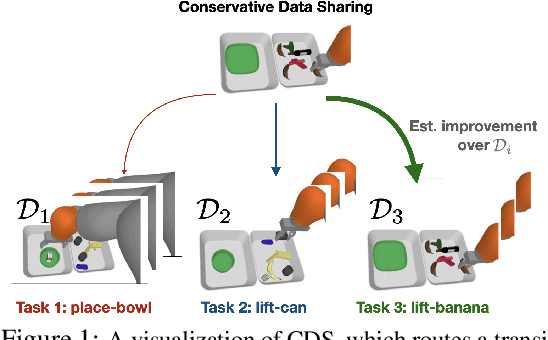
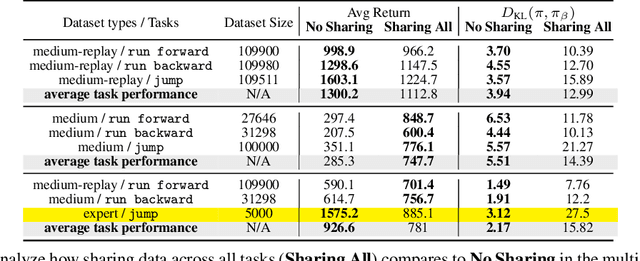
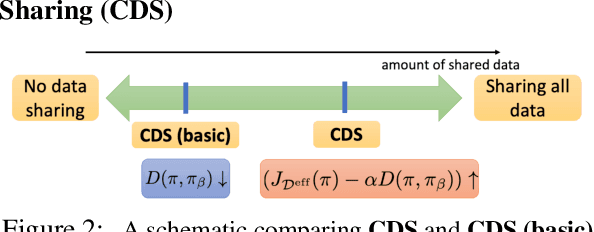

Offline reinforcement learning (RL) algorithms have shown promising results in domains where abundant pre-collected data is available. However, prior methods focus on solving individual problems from scratch with an offline dataset without considering how an offline RL agent can acquire multiple skills. We argue that a natural use case of offline RL is in settings where we can pool large amounts of data collected in various scenarios for solving different tasks, and utilize all of this data to learn behaviors for all the tasks more effectively rather than training each one in isolation. However, sharing data across all tasks in multi-task offline RL performs surprisingly poorly in practice. Thorough empirical analysis, we find that sharing data can actually exacerbate the distributional shift between the learned policy and the dataset, which in turn can lead to divergence of the learned policy and poor performance. To address this challenge, we develop a simple technique for data-sharing in multi-task offline RL that routes data based on the improvement over the task-specific data. We call this approach conservative data sharing (CDS), and it can be applied with multiple single-task offline RL methods. On a range of challenging multi-task locomotion, navigation, and vision-based robotic manipulation problems, CDS achieves the best or comparable performance compared to prior offline multi-task RL methods and previous data sharing approaches.
Efficiently Identifying Task Groupings for Multi-Task Learning
Sep 10, 2021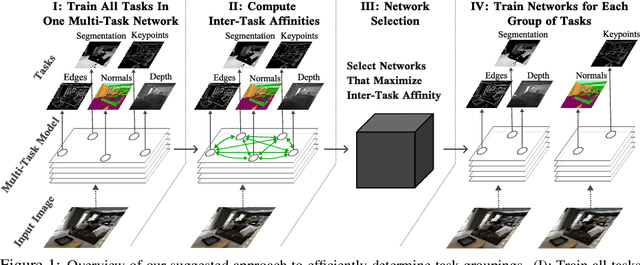
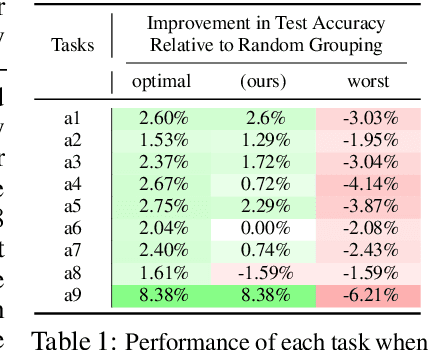
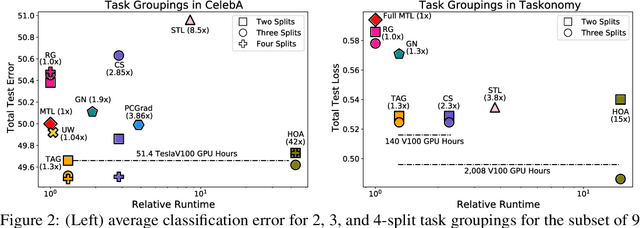
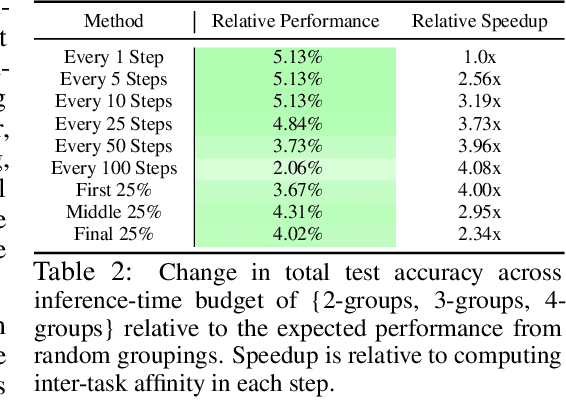
Multi-task learning can leverage information learned by one task to benefit the training of other tasks. Despite this capacity, naively training all tasks together in one model often degrades performance, and exhaustively searching through combinations of task groupings can be prohibitively expensive. As a result, efficiently identifying the tasks that would benefit from co-training remains a challenging design question without a clear solution. In this paper, we suggest an approach to select which tasks should train together in multi-task learning models. Our method determines task groupings in a single training run by co-training all tasks together and quantifying the effect to which one task's gradient would affect another task's loss. On the large-scale Taskonomy computer vision dataset, we find this method can decrease test loss by 10.0\% compared to simply training all tasks together while operating 11.6 times faster than a state-of-the-art task grouping method.
Visual Adversarial Imitation Learning using Variational Models
Jul 16, 2021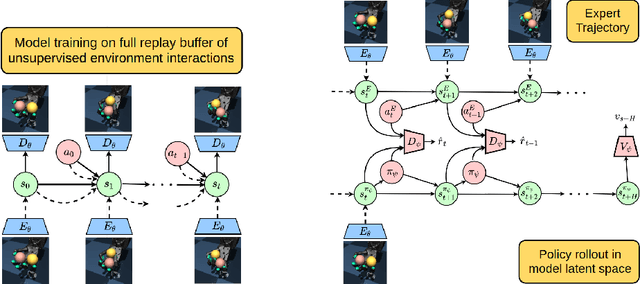
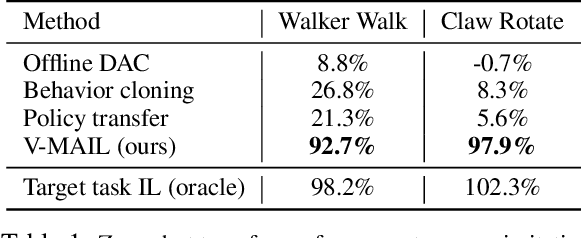


Reward function specification, which requires considerable human effort and iteration, remains a major impediment for learning behaviors through deep reinforcement learning. In contrast, providing visual demonstrations of desired behaviors often presents an easier and more natural way to teach agents. We consider a setting where an agent is provided a fixed dataset of visual demonstrations illustrating how to perform a task, and must learn to solve the task using the provided demonstrations and unsupervised environment interactions. This setting presents a number of challenges including representation learning for visual observations, sample complexity due to high dimensional spaces, and learning instability due to the lack of a fixed reward or learning signal. Towards addressing these challenges, we develop a variational model-based adversarial imitation learning (V-MAIL) algorithm. The model-based approach provides a strong signal for representation learning, enables sample efficiency, and improves the stability of adversarial training by enabling on-policy learning. Through experiments involving several vision-based locomotion and manipulation tasks, we find that V-MAIL learns successful visuomotor policies in a sample-efficient manner, has better stability compared to prior work, and also achieves higher asymptotic performance. We further find that by transferring the learned models, V-MAIL can learn new tasks from visual demonstrations without any additional environment interactions. All results including videos can be found online at \url{https://sites.google.com/view/variational-mail}.