 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestructuring Vector Quantization with the Rotation Trick
Oct 08, 2024



Vector Quantized Variational AutoEncoders (VQ-VAEs) are designed to compress a continuous input to a discrete latent space and reconstruct it with minimal distortion. They operate by maintaining a set of vectors -- often referred to as the codebook -- and quantizing each encoder output to the nearest vector in the codebook. However, as vector quantization is non-differentiable, the gradient to the encoder flows around the vector quantization layer rather than through it in a straight-through approximation. This approximation may be undesirable as all information from the vector quantization operation is lost. In this work, we propose a way to propagate gradients through the vector quantization layer of VQ-VAEs. We smoothly transform each encoder output into its corresponding codebook vector via a rotation and rescaling linear transformation that is treated as a constant during backpropagation. As a result, the relative magnitude and angle between encoder output and codebook vector becomes encoded into the gradient as it propagates through the vector quantization layer and back to the encoder. Across 11 different VQ-VAE training paradigms, we find this restructuring improves reconstruction metrics, codebook utilization, and quantization error. Our code is available at https://github.com/cfifty/rotation_trick.
Context-Aware Meta-Learning
Oct 17, 2023



Large Language Models like ChatGPT demonstrate a remarkable capacity to learn new concepts during inference without any fine-tuning. However, visual models trained to detect new objects during inference have been unable to replicate this ability, and instead either perform poorly or require meta-training and/or fine-tuning on similar objects. In this work, we propose a meta-learning algorithm that emulates Large Language Models by learning new visual concepts during inference without fine-tuning. Our approach leverages a frozen pre-trained feature extractor, and analogous to in-context learning, recasts meta-learning as sequence modeling over datapoints with known labels and a test datapoint with an unknown label. On 8 out of 11 meta-learning benchmarks, our approach -- without meta-training or fine-tuning -- exceeds or matches the state-of-the-art algorithm, P>M>F, which is meta-trained on these benchmarks.
In-Context Learning for Few-Shot Molecular Property Prediction
Oct 13, 2023



In-context learning has become an important approach for few-shot learning in Large Language Models because of its ability to rapidly adapt to new tasks without fine-tuning model parameters. However, it is restricted to applications in natural language and inapplicable to other domains. In this paper, we adapt the concepts underpinning in-context learning to develop a new algorithm for few-shot molecular property prediction. Our approach learns to predict molecular properties from a context of (molecule, property measurement) pairs and rapidly adapts to new properties without fine-tuning. On the FS-Mol and BACE molecular property prediction benchmarks, we find this method surpasses the performance of recent meta-learning algorithms at small support sizes and is competitive with the best methods at large support sizes.
Harnessing Simulation for Molecular Embeddings
Feb 04, 2023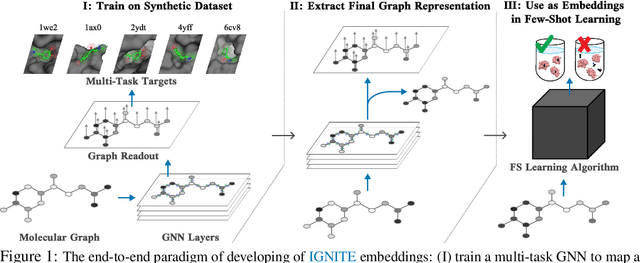

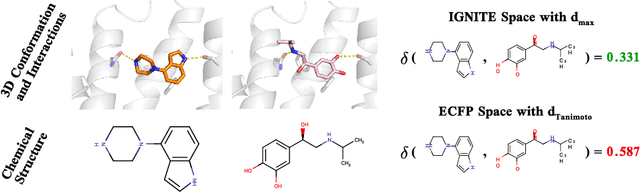
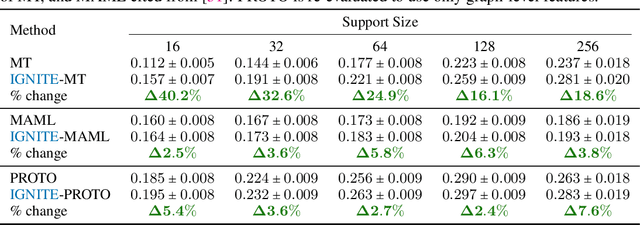
While deep learning has unlocked advances in computational biology once thought to be decades away, extending deep learning techniques to the molecular domain has proven challenging, as labeled data is scarce and the benefit from self-supervised learning can be negligible in many cases. In this work, we explore a different approach. Inspired by methods in deep reinforcement learning and robotics, we explore harnessing physics-based molecular simulation to develop molecular embeddings. By fitting a Graph Neural Network to simulation data, molecules that display similar interactions with biological targets under simulation develop similar representations in the embedding space. These embeddings can then be used to initialize the feature space of down-stream models trained on real-world data to encode information learned during simulation into a molecular prediction task. Our experimental findings indicate this approach improves the performance of existing deep learning models on real-world molecular prediction tasks by as much as 38% with minimal modification to the downstream model and no hyperparameter tuning.
Layerwise Bregman Representation Learning with Applications to Knowledge Distillation
Sep 15, 2022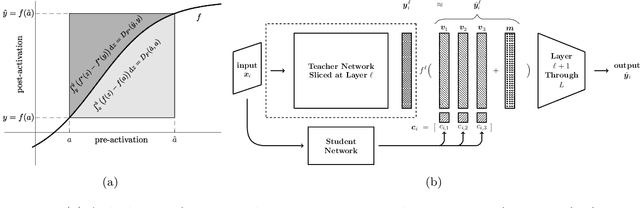
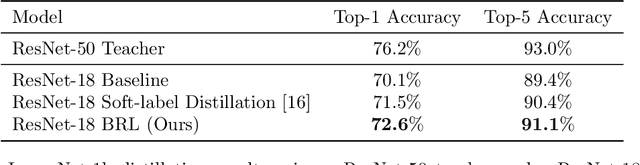
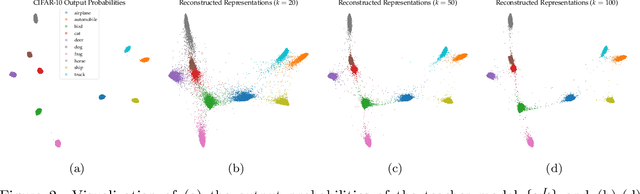
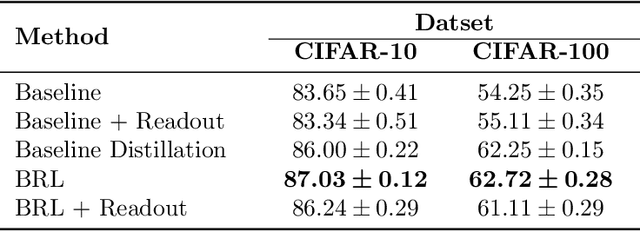
In this work, we propose a novel approach for layerwise representation learning of a trained neural network. In particular, we form a Bregman divergence based on the layer's transfer function and construct an extension of the original Bregman PCA formulation by incorporating a mean vector and normalizing the principal directions with respect to the geometry of the local convex function around the mean. This generalization allows exporting the learned representation as a fixed layer with a non-linearity. As an application to knowledge distillation, we cast the learning problem for the student network as predicting the compression coefficients of the teacher's representations, which are passed as the input to the imported layer. Our empirical findings indicate that our approach is substantially more effective for transferring information between networks than typical teacher-student training using the teacher's penultimate layer representations and soft labels.
N-Grammer: Augmenting Transformers with latent n-grams
Jul 13, 2022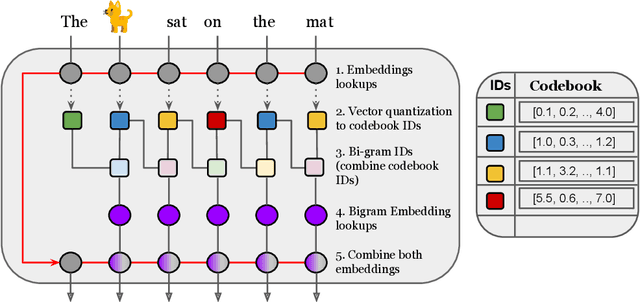
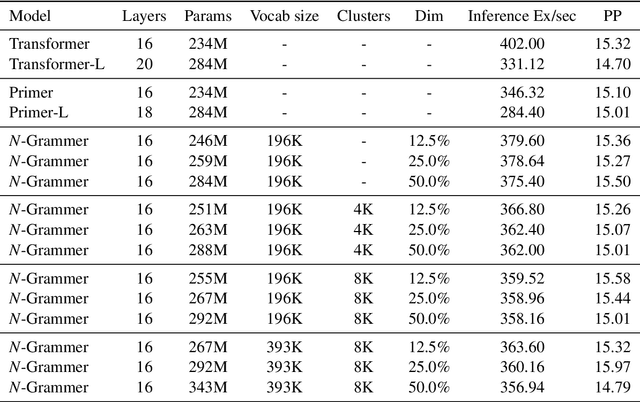

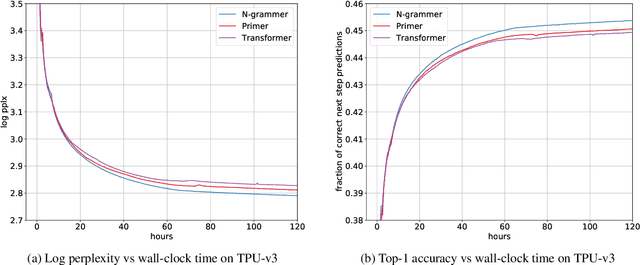
Transformer models have recently emerged as one of the foundational models in natural language processing, and as a byproduct, there is significant recent interest and investment in scaling these models. However, the training and inference costs of these large Transformer language models are prohibitive, thus necessitating more research in identifying more efficient variants. In this work, we propose a simple yet effective modification to the Transformer architecture inspired by the literature in statistical language modeling, by augmenting the model with n-grams that are constructed from a discrete latent representation of the text sequence. We evaluate our model, the N-Grammer on language modeling on the C4 data-set as well as text classification on the SuperGLUE data-set, and find that it outperforms several strong baselines such as the Transformer and the Primer. We open-source our model for reproducibility purposes in Jax.
Step-size Adaptation Using Exponentiated Gradient Updates
Jan 31, 2022

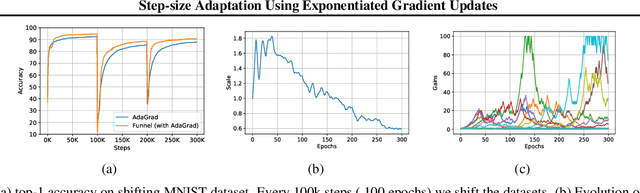
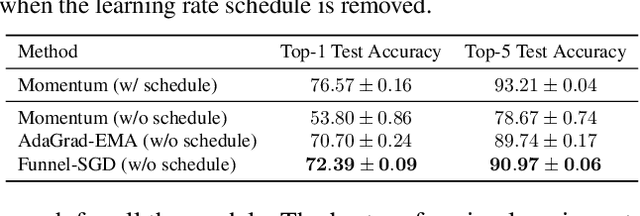
Optimizers like Adam and AdaGrad have been very successful in training large-scale neural networks. Yet, the performance of these methods is heavily dependent on a carefully tuned learning rate schedule. We show that in many large-scale applications, augmenting a given optimizer with an adaptive tuning method of the step-size greatly improves the performance. More precisely, we maintain a global step-size scale for the update as well as a gain factor for each coordinate. We adjust the global scale based on the alignment of the average gradient and the current gradient vectors. A similar approach is used for updating the local gain factors. This type of step-size scale tuning has been done before with gradient descent updates. In this paper, we update the step-size scale and the gain variables with exponentiated gradient updates instead. Experimentally, we show that our approach can achieve compelling accuracy on standard models without using any specially tuned learning rate schedule. We also show the effectiveness of our approach for quickly adapting to distribution shifts in the data during training.
Co-training Transformer with Videos and Images Improves Action Recognition
Dec 14, 2021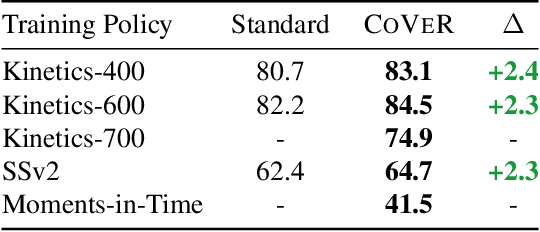
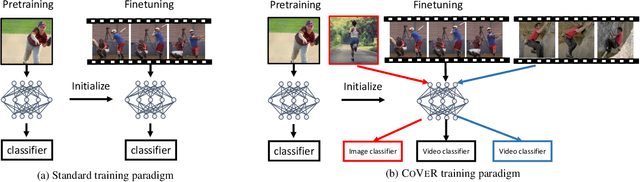

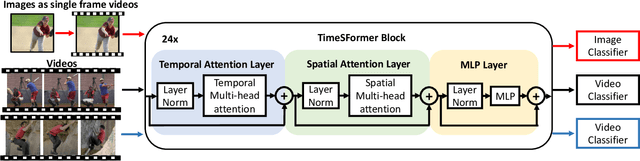
In learning action recognition, models are typically pre-trained on object recognition with images, such as ImageNet, and later fine-tuned on target action recognition with videos. This approach has achieved good empirical performance especially with recent transformer-based video architectures. While recently many works aim to design more advanced transformer architectures for action recognition, less effort has been made on how to train video transformers. In this work, we explore several training paradigms and present two findings. First, video transformers benefit from joint training on diverse video datasets and label spaces (e.g., Kinetics is appearance-focused while SomethingSomething is motion-focused). Second, by further co-training with images (as single-frame videos), the video transformers learn even better video representations. We term this approach as Co-training Videos and Images for Action Recognition (CoVeR). In particular, when pretrained on ImageNet-21K based on the TimeSFormer architecture, CoVeR improves Kinetics-400 Top-1 Accuracy by 2.4%, Kinetics-600 by 2.3%, and SomethingSomething-v2 by 2.3%. When pretrained on larger-scale image datasets following previous state-of-the-art, CoVeR achieves best results on Kinetics-400 (87.2%), Kinetics-600 (87.9%), Kinetics-700 (79.8%), SomethingSomething-v2 (70.9%), and Moments-in-Time (46.1%), with a simple spatio-temporal video transformer.
Efficiently Identifying Task Groupings for Multi-Task Learning
Sep 10, 2021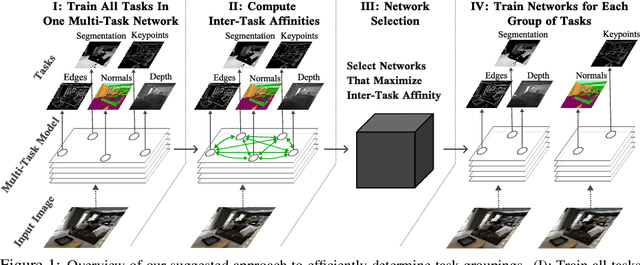
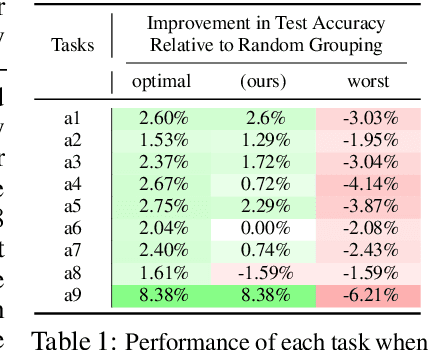
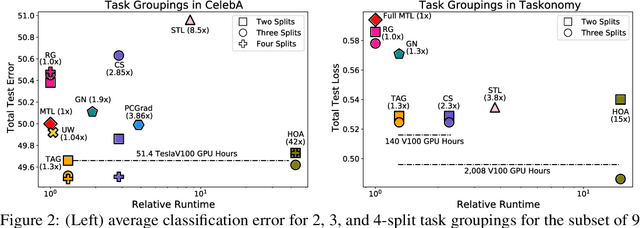
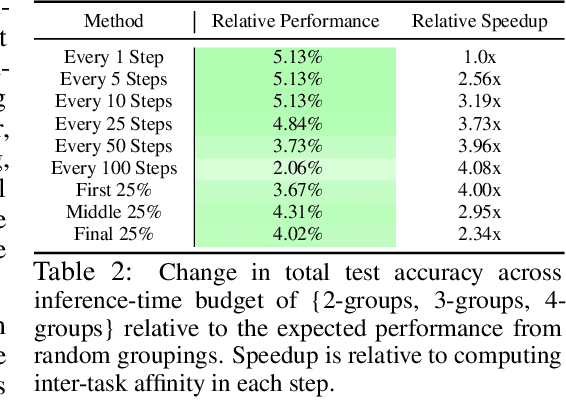
Multi-task learning can leverage information learned by one task to benefit the training of other tasks. Despite this capacity, naively training all tasks together in one model often degrades performance, and exhaustively searching through combinations of task groupings can be prohibitively expensive. As a result, efficiently identifying the tasks that would benefit from co-training remains a challenging design question without a clear solution. In this paper, we suggest an approach to select which tasks should train together in multi-task learning models. Our method determines task groupings in a single training run by co-training all tasks together and quantifying the effect to which one task's gradient would affect another task's loss. On the large-scale Taskonomy computer vision dataset, we find this method can decrease test loss by 10.0\% compared to simply training all tasks together while operating 11.6 times faster than a state-of-the-art task grouping method.
Measuring and Harnessing Transference in Multi-Task Learning
Oct 29, 2020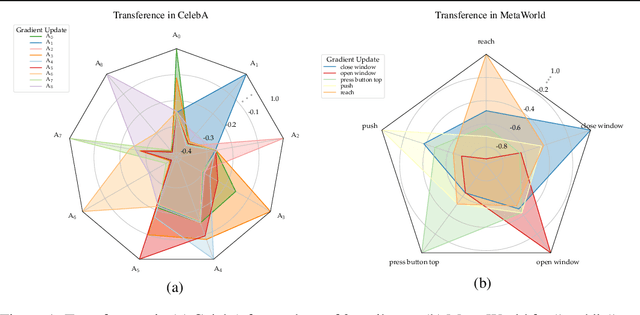
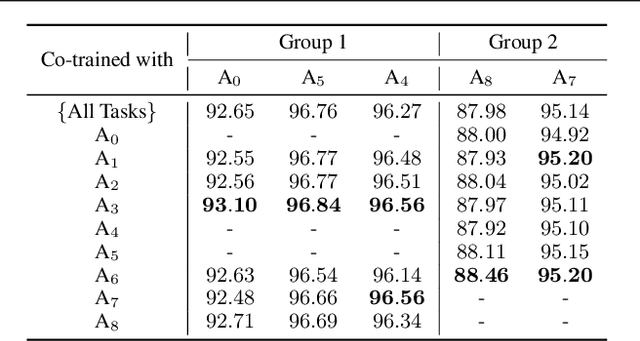

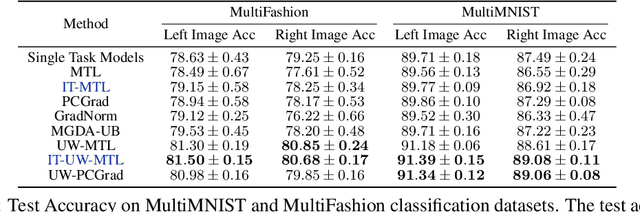
Multi-task learning can leverage information learned by one task to benefit the training of other tasks. Despite this capacity, na\"ive formulations often degrade performance and in particular, identifying the tasks that would benefit from co-training remains a challenging design question. In this paper, we analyze the dynamics of information transfer, or transference, across tasks throughout training. Specifically, we develop a similarity measure that can quantify transference among tasks and use this quantity to both better understand the optimization dynamics of multi-task learning as well as improve overall learning performance. In the latter case, we propose two methods to leverage our transference metric. The first operates at a macro-level by selecting which tasks should train together while the second functions at a micro-level by determining how to combine task gradients at each training step. We find these methods can lead to significant improvement over prior work on three supervised multi-task learning benchmarks and one multi-task reinforcement learning paradigm.