 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Narrow Unlearning to Emergent Misalignment: Causes, Consequences, and Containment in LLMs
Nov 18, 2025



Recent work has shown that fine-tuning on insecure code data can trigger an emergent misalignment (EMA) phenomenon, where models generate malicious responses even to prompts unrelated to the original insecure code-writing task. Such cross-domain generalization of harmful behavior underscores the need for a deeper understanding of the algorithms, tasks, and datasets that induce emergent misalignment. In this work, we extend this study by demonstrating that emergent misalignment can also arise from narrow refusal unlearning in specific domains. We perform refusal unlearning on Cybersecurity and Safety concept, and evaluate EMA by monitoring refusal scores across seven responsible AI (RAI) domains, Cybersecurity, Safety, Toxicity, Bias, Sensitive Content, Medical/Legal, and Privacy. Our work shows that narrow domain unlearning can yield compliance responses for the targeted concept, however, it may also propagate EMA to unrelated domains. Among the two intervened concepts, Cybersecurity and Safety, we find that the safety concept can have larger EMA impact, i.e, causing lower refusal scores, across other unrelated domains such as bias. We observe this effect consistently across two model families, Mistral-7b-0.3v, and Qwen-7b-2.5. Further, we show that refusal unlearning augmented with cross-entropy loss function on a small set of retain data from the affected domains can largely, if not fully, restore alignment across the impacted domains while having lower refusal rate on the concept we perform unlearning on. To investigate the underlying causes of EMA, we analyze concept entanglements at the representation level via concept vectors. Our analysis reveals that concepts with higher representation similarity in earlier layers are more susceptible to EMA after intervention when the refusal stream is altered through targeted refusal unlearning.
Beyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025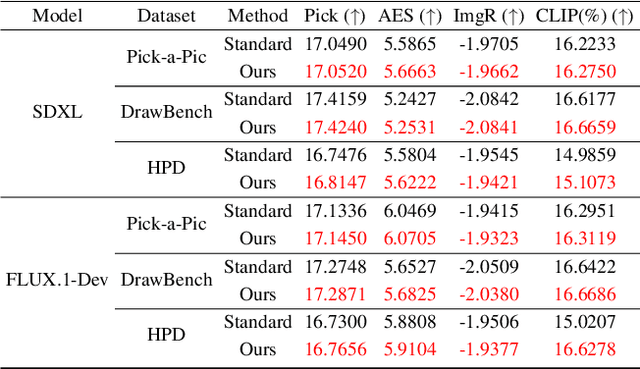
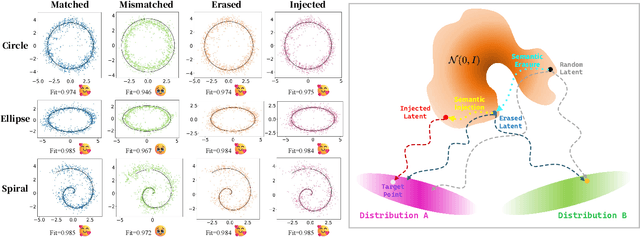


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
Whole-Body Control With Terrain Estimation of A 6-DoF Wheeled Bipedal Robot
Nov 09, 2025



Wheeled bipedal robots have garnered increasing attention in exploration and inspection. However, most research simplifies calculations by ignoring leg dynamics, thereby restricting the robot's full motion potential. Additionally, robots face challenges when traversing uneven terrain. To address the aforementioned issue, we develop a complete dynamics model and design a whole-body control framework with terrain estimation for a novel 6 degrees of freedom wheeled bipedal robot. This model incorporates the closed-loop dynamics of the robot and a ground contact model based on the estimated ground normal vector. We use a LiDAR inertial odometry framework and improved Principal Component Analysis for terrain estimation. Task controllers, including PD control law and LQR, are employed for pose control and centroidal dynamics-based balance control, respectively. Furthermore, a hierarchical optimization approach is used to solve the whole-body control problem. We validate the performance of the terrain estimation algorithm and demonstrate the algorithm's robustness and ability to traverse uneven terrain through both simulation and real-world experiments.
MapSAM2: Adapting SAM2 for Automatic Segmentation of Historical Map Images and Time Series
Oct 31, 2025



Historical maps are unique and valuable archives that document geographic features across different time periods. However, automated analysis of historical map images remains a significant challenge due to their wide stylistic variability and the scarcity of annotated training data. Constructing linked spatio-temporal datasets from historical map time series is even more time-consuming and labor-intensive, as it requires synthesizing information from multiple maps. Such datasets are essential for applications such as dating buildings, analyzing the development of road networks and settlements, studying environmental changes etc. We present MapSAM2, a unified framework for automatically segmenting both historical map images and time series. Built on a visual foundation model, MapSAM2 adapts to diverse segmentation tasks with few-shot fine-tuning. Our key innovation is to treat both historical map images and time series as videos. For images, we process a set of tiles as a video, enabling the memory attention mechanism to incorporate contextual cues from similar tiles, leading to improved geometric accuracy, particularly for areal features. For time series, we introduce the annotated Siegfried Building Time Series Dataset and, to reduce annotation costs, propose generating pseudo time series from single-year maps by simulating common temporal transformations. Experimental results show that MapSAM2 learns temporal associations effectively and can accurately segment and link buildings in time series under limited supervision or using pseudo videos. We will release both our dataset and code to support future research.
Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence
Oct 23, 2025Most video reasoning models only generate textual reasoning traces without indicating when and where key evidence appears. Recent models such as OpenAI-o3 have sparked wide interest in evidence-centered reasoning for images, yet extending this ability to videos is more challenging, as it requires joint temporal tracking and spatial localization across dynamic scenes. We introduce Open-o3 Video, a non-agent framework that integrates explicit spatio-temporal evidence into video reasoning, and carefully collect training data and design training strategies to address the aforementioned challenges. The model highlights key timestamps, objects, and bounding boxes alongside its answers, allowing reasoning to be grounded in concrete visual observations. To enable this functionality, we first curate and build two high-quality datasets, STGR-CoT-30k for SFT and STGR-RL-36k for RL, with carefully constructed temporal and spatial annotations, since most existing datasets offer either temporal spans for videos or spatial boxes on images, lacking unified spatio-temporal supervision and reasoning traces. Then, we adopt a cold-start reinforcement learning strategy with multiple specially designed rewards that jointly encourage answer accuracy, temporal alignment, and spatial precision. On V-STAR benchmark, Open-o3 Video achieves state-of-the-art performance, raising mAM by 14.4% and mLGM by 24.2% on the Qwen2.5-VL baseline. Consistent improvements are also observed on a broad range of video understanding benchmarks, including VideoMME, WorldSense, VideoMMMU, and TVGBench. Beyond accuracy, the reasoning traces produced by Open-o3 Video also provide valuable signals for test-time scaling, enabling confidence-aware verification and improving answer reliability.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Native Hybrid Attention for Efficient Sequence Modeling
Oct 08, 2025



Transformers excel at sequence modeling but face quadratic complexity, while linear attention offers improved efficiency but often compromises recall accuracy over long contexts. In this work, we introduce Native Hybrid Attention (NHA), a novel hybrid architecture of linear and full attention that integrates both intra \& inter-layer hybridization into a unified layer design. NHA maintains long-term context in key-value slots updated by a linear RNN, and augments them with short-term tokens from a sliding window. A single \texttt{softmax attention} operation is then applied over all keys and values, enabling per-token and per-head context-dependent weighting without requiring additional fusion parameters. The inter-layer behavior is controlled through a single hyperparameter, the sliding window size, which allows smooth adjustment between purely linear and full attention while keeping all layers structurally uniform. Experimental results show that NHA surpasses Transformers and other hybrid baselines on recall-intensive and commonsense reasoning tasks. Furthermore, pretrained LLMs can be structurally hybridized with NHA, achieving competitive accuracy while delivering significant efficiency gains. Code is available at https://github.com/JusenD/NHA.
HTMformer: Hybrid Time and Multivariate Transformer for Time Series Forecasting
Oct 08, 2025



Transformer-based methods have achieved impressive results in time series forecasting. However, existing Transformers still exhibit limitations in sequence modeling as they tend to overemphasize temporal dependencies. This incurs additional computational overhead without yielding corresponding performance gains. We find that the performance of Transformers is highly dependent on the embedding method used to learn effective representations. To address this issue, we extract multivariate features to augment the effective information captured in the embedding layer, yielding multidimensional embeddings that convey richer and more meaningful sequence representations. These representations enable Transformer-based forecasters to better understand the series. Specifically, we introduce Hybrid Temporal and Multivariate Embeddings (HTME). The HTME extractor integrates a lightweight temporal feature extraction module with a carefully designed multivariate feature extraction module to provide complementary features, thereby achieving a balance between model complexity and performance. By combining HTME with the Transformer architecture, we present HTMformer, leveraging the enhanced feature extraction capability of the HTME extractor to build a lightweight forecaster. Experiments conducted on eight real-world datasets demonstrate that our approach outperforms existing baselines in both accuracy and efficiency.
AutoCodeBench: Large Language Models are Automatic Code Benchmark Generators
Aug 12, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains, with code generation emerging as a key area of focus. While numerous benchmarks have been proposed to evaluate their code generation abilities, these benchmarks face several critical limitations. First, they often rely on manual annotations, which are time-consuming and difficult to scale across different programming languages and problem complexities. Second, most existing benchmarks focus primarily on Python, while the few multilingual benchmarks suffer from limited difficulty and uneven language distribution. To address these challenges, we propose AutoCodeGen, an automated method for generating high-difficulty multilingual code generation datasets without manual annotations. AutoCodeGen ensures the correctness and completeness of test cases by generating test inputs with LLMs and obtaining test outputs through a multilingual sandbox, while achieving high data quality through reverse-order problem generation and multiple filtering steps. Using this novel method, we introduce AutoCodeBench, a large-scale code generation benchmark comprising 3,920 problems evenly distributed across 20 programming languages. It is specifically designed to evaluate LLMs on challenging, diverse, and practical multilingual tasks. We evaluate over 30 leading open-source and proprietary LLMs on AutoCodeBench and its simplified version AutoCodeBench-Lite. The results show that even the most advanced LLMs struggle with the complexity, diversity, and multilingual nature of these tasks. Besides, we introduce AutoCodeBench-Complete, specifically designed for base models to assess their few-shot code generation capabilities. We hope the AutoCodeBench series will serve as a valuable resource and inspire the community to focus on more challenging and practical multilingual code generation scenarios.