 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning with Sequence-Conditioned Transporter Networks
Sep 15, 2021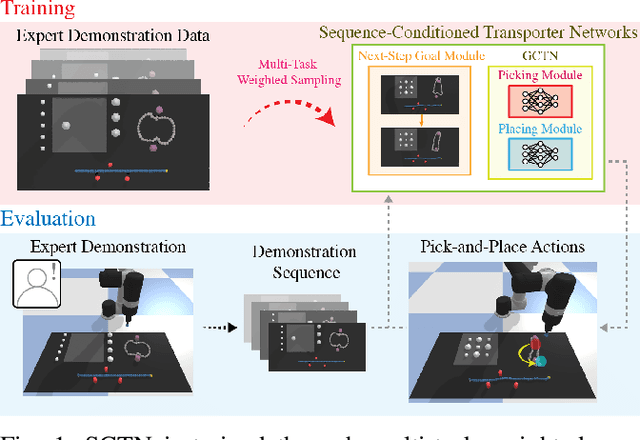
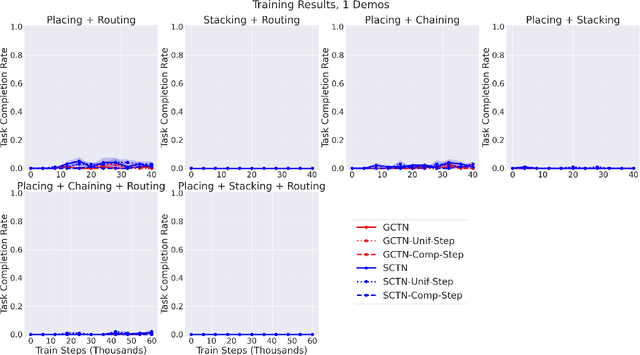
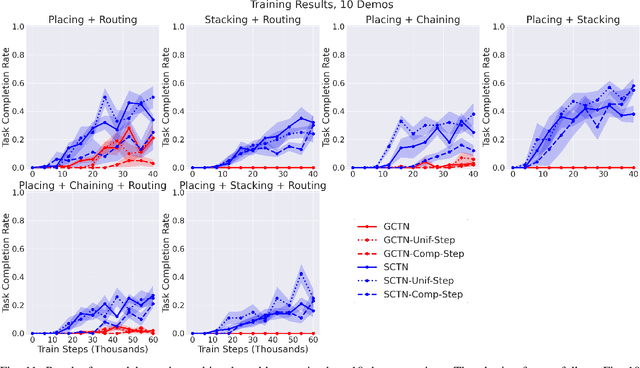
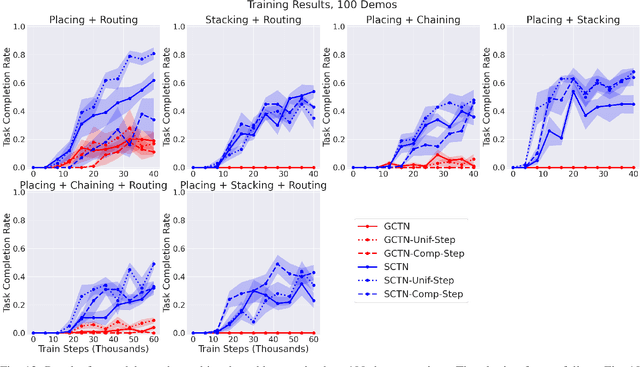
Enabling robots to solve multiple manipulation tasks has a wide range of industrial applications. While learning-based approaches enjoy flexibility and generalizability, scaling these approaches to solve such compositional tasks remains a challenge. In this work, we aim to solve multi-task learning through the lens of sequence-conditioning and weighted sampling. First, we propose a new suite of benchmark specifically aimed at compositional tasks, MultiRavens, which allows defining custom task combinations through task modules that are inspired by industrial tasks and exemplify the difficulties in vision-based learning and planning methods. Second, we propose a vision-based end-to-end system architecture, Sequence-Conditioned Transporter Networks, which augments Goal-Conditioned Transporter Networks with sequence-conditioning and weighted sampling and can efficiently learn to solve multi-task long horizon problems. Our analysis suggests that not only the new framework significantly improves pick-and-place performance on novel 10 multi-task benchmark problems, but also the multi-task learning with weighted sampling can vastly improve learning and agent performances on individual tasks.
A Robustness Analysis of Inverse Optimal Control of Bipedal Walking
Apr 25, 2021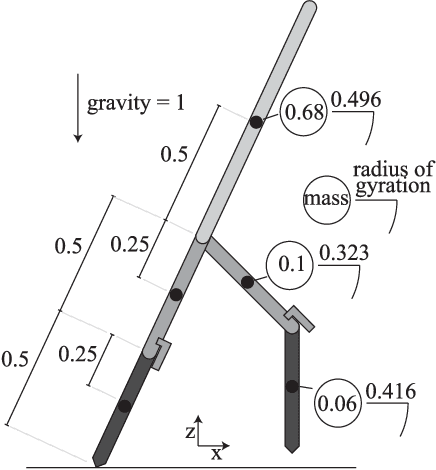
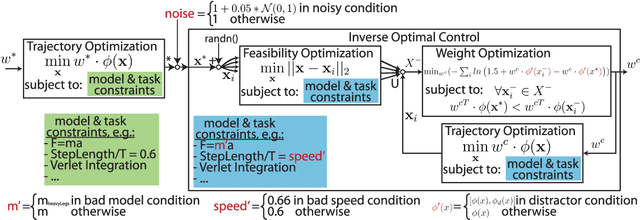
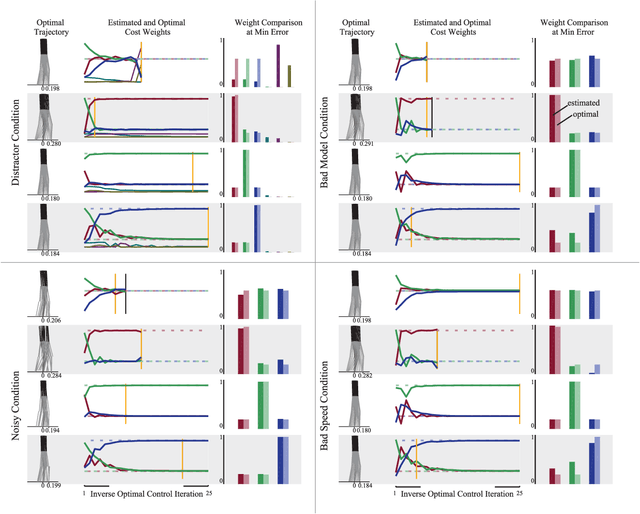

Cost functions have the potential to provide compact and understandable generalizations of motion. The goal of Inverse Optimal Control (IOC) is to analyze an observed behavior which is assumed to be optimal with respect to an unknown cost function, and infer this cost function. Here we develop a method for characterizing cost functions of legged locomotion, with the goal of representing complex humanoid behavior with simple models. To test this methodology we simulate walking gaits of a simple 5 link planar walking model which optimize known cost functions, and assess the ability of our IOC method to recover them. In particular, the IOC method uses an iterative trajectory optimization process to infer cost function weightings consistent with those used to generate a single demonstrated optimal trial. We also explore sensitivity of the IOC to sensor noise in the observed trajectory, imperfect knowledge of the model or task, as well as uncertainty in the components of the cost function used. With appropriate modeling, these methods may help infer cost functions from human data, yielding a compact and generalizable representation of human-like motion for use in humanoid robot controllers, as well as providing a new tool for experimentally exploring human preferences.
Robust Multi-Modal Policies for Industrial Assembly via Reinforcement Learning and Demonstrations: A Large-Scale Study
Mar 23, 2021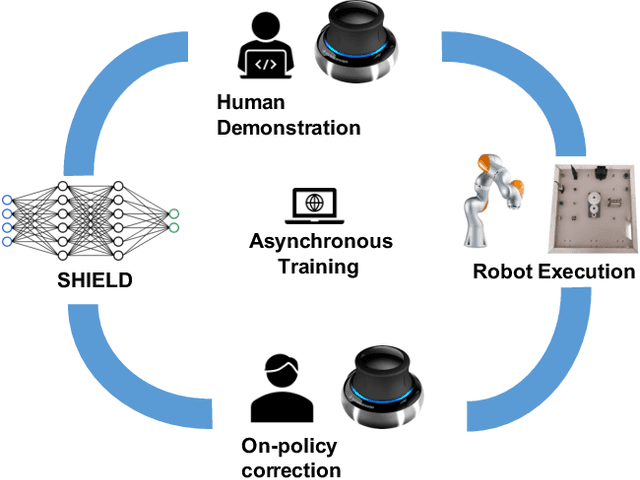


Over the past several years there has been a considerable research investment into learning-based approaches to industrial assembly, but despite significant progress these techniques have yet to be adopted by industry. We argue that it is the prohibitively large design space for Deep Reinforcement Learning (DRL), rather than algorithmic limitations per se, that are truly responsible for this lack of adoption. Pushing these techniques into the industrial mainstream requires an industry-oriented paradigm which differs significantly from the academic mindset. In this paper we define criteria for industry-oriented DRL, and perform a thorough comparison according to these criteria of one family of learning approaches, DRL from demonstration, against a professional industrial integrator on the recently established NIST assembly benchmark. We explain the design choices, representing several years of investigation, which enabled our DRL system to consistently outperform the integrator baseline in terms of both speed and reliability. Finally, we conclude with a competition between our DRL system and a human on a challenge task of insertion into a randomly moving target. This study suggests that DRL is capable of outperforming not only established engineered approaches, but the human motor system as well, and that there remains significant room for improvement. Videos can be found on our project website: https://sites.google.com/view/shield-nist.
Benchmarking Off-The-Shelf Solutions to Robotic Assembly Tasks
Mar 08, 2021

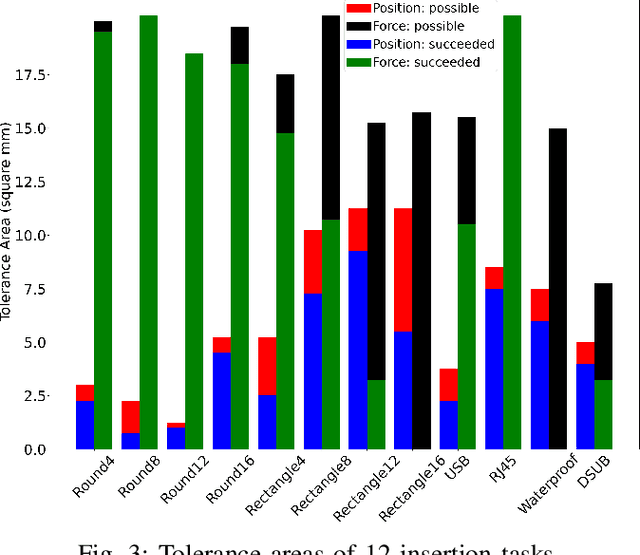

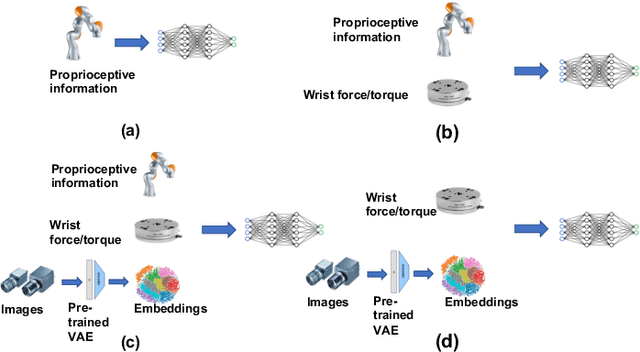
In recent years, many learning based approaches have been studied to realize robotic manipulation and assembly tasks, often including vision and force/tactile feedback. However, it remains frequently unclear what is the baseline state-of-the-art performance and what are the bottleneck problems. In this work, we evaluate some off-the-shelf (OTS) industrial solutions on a recently introduced benchmark, the National Institute of Standards and Technology (NIST) Assembly Task Boards. A set of assembly tasks are introduced and baseline methods are provided to understand their intrinsic difficulty. Multiple sensor-based robotic solutions are then evaluated, including hybrid force/motion control and 2D/3D pattern matching algorithms. An end-to-end integrated solution that accomplishes the tasks is also provided. The results and findings throughout the study reveal a few noticeable factors that impede the adoptions of the OTS solutions: expertise dependent, limited applicability, lack of interoperability, no scene awareness or error recovery mechanisms, and high cost. This paper also provides a first attempt of an objective benchmark performance on the NIST Assembly Task Boards as a reference comparison for future works on this problem.
Learning Dense Rewards for Contact-Rich Manipulation Tasks
Nov 17, 2020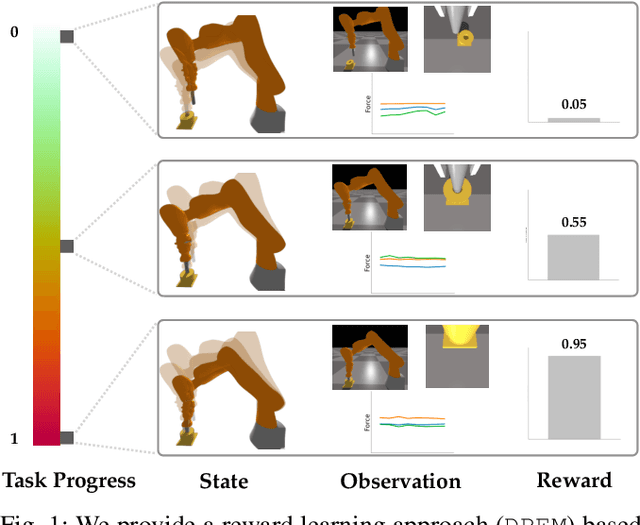
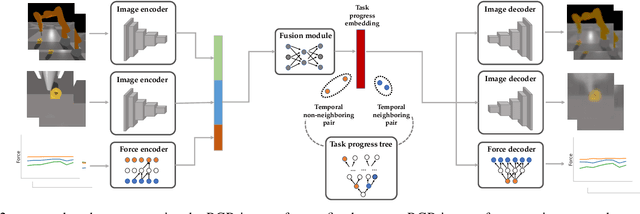
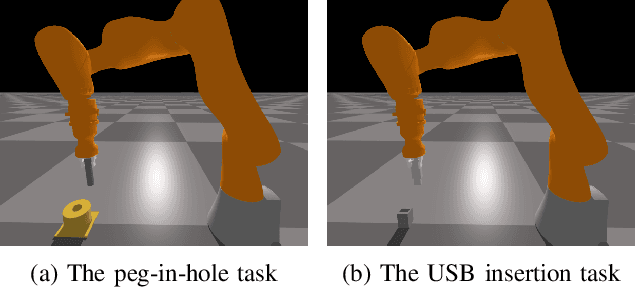
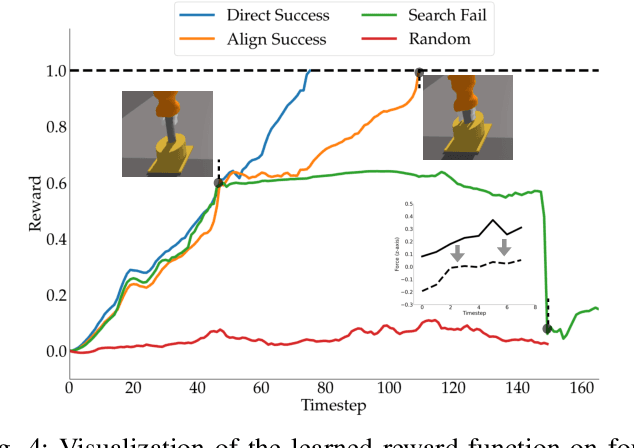
Rewards play a crucial role in reinforcement learning. To arrive at the desired policy, the design of a suitable reward function often requires significant domain expertise as well as trial-and-error. Here, we aim to minimize the effort involved in designing reward functions for contact-rich manipulation tasks. In particular, we provide an approach capable of extracting dense reward functions algorithmically from robots' high-dimensional observations, such as images and tactile feedback. In contrast to state-of-the-art high-dimensional reward learning methodologies, our approach does not leverage adversarial training, and is thus less prone to the associated training instabilities. Instead, our approach learns rewards by estimating task progress in a self-supervised manner. We demonstrate the effectiveness and efficiency of our approach on two contact-rich manipulation tasks, namely, peg-in-hole and USB insertion. The experimental results indicate that the policies trained with the learned reward function achieves better performance and faster convergence compared to the baselines.
Residual Learning from Demonstration
Aug 18, 2020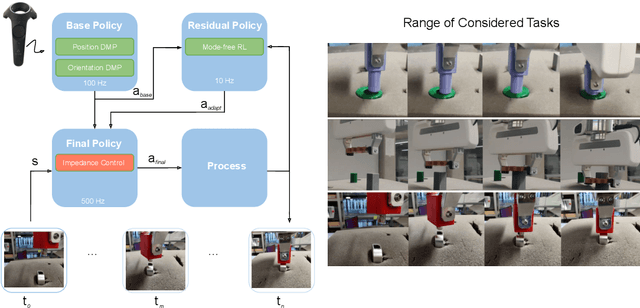
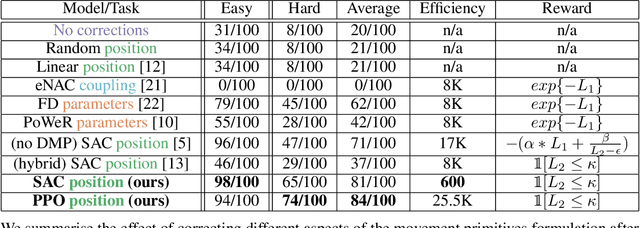
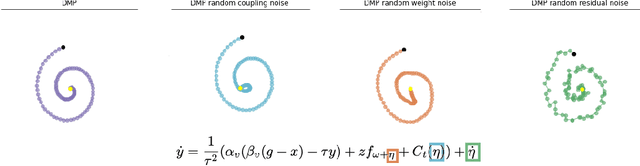
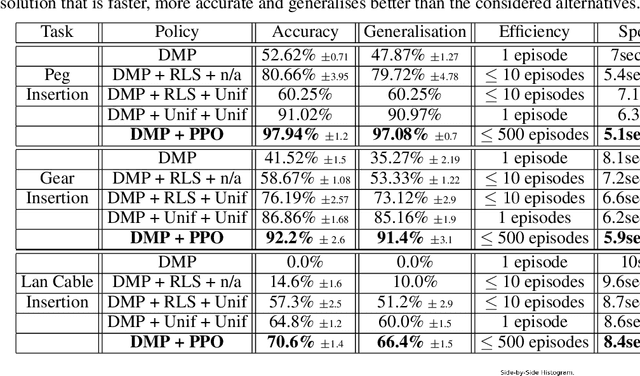
Contacts and friction are inherent to nearly all robotic manipulation tasks. Through the motor skill of insertion, we study how robots can learn to cope when these attributes play a salient role. In this work we propose residual learning from demonstration (rLfD), a framework that combines dynamic movement primitives (DMP) that rely on behavioural cloning with a reinforcement learning (RL) based residual correction policy. The proposed solution is applied directly in task space and operates on the full pose of the robot. We show that rLfD outperforms alternatives and improves the generalisation abilities of DMPs. We evaluate this approach by training an agent to successfully perform both simulated and real world insertions of pegs, gears and plugs into respective sockets.
An Interior Point Method Solving Motion Planning Problems with Narrow Passages
Jul 09, 2020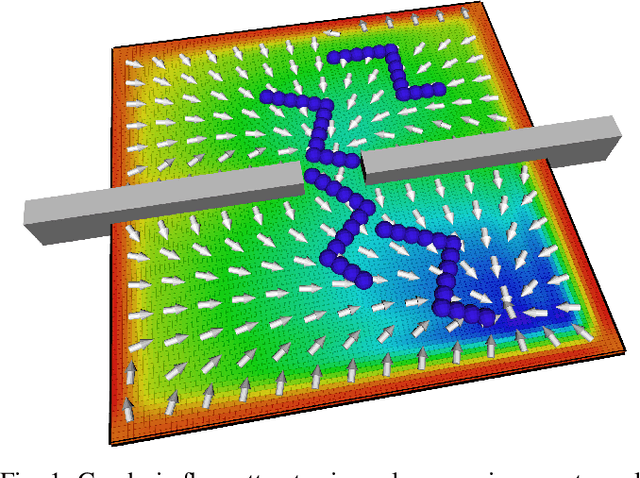
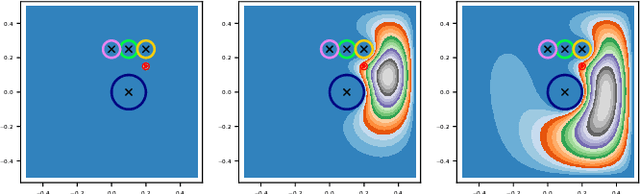


Algorithmic solutions for the motion planning problem have been investigated for five decades. Since the development of A* in 1969 many approaches have been investigated, traditionally classified as either grid decomposition, potential fields or sampling-based. In this work, we focus on using numerical optimization, which is understudied for solving motion planning problems. This lack of interest in the favor of sampling-based methods is largely due to the non-convexity introduced by narrow passages. We address this shortcoming by grounding the motion planning problem in differential geometry. We demonstrate through a series of experiments on 3 Dofs and 6 Dofs narrow passage problems, how modeling explicitly the underlying Riemannian manifold leads to an efficient interior-point non-linear programming solution.
Supervised Learning and Reinforcement Learning of Feedback Models for Reactive Behaviors: Tactile Feedback Testbed
Jun 29, 2020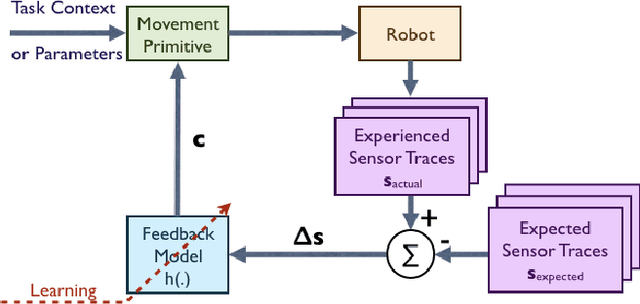
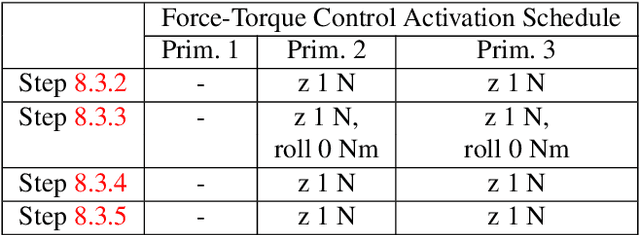

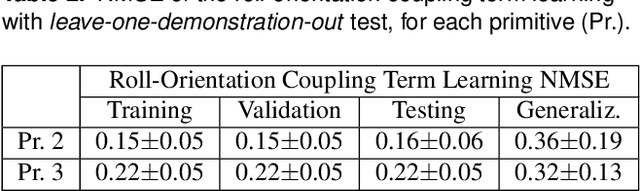
Robots need to be able to adapt to unexpected changes in the environment such that they can autonomously succeed in their tasks. However, hand-designing feedback models for adaptation is tedious, if at all possible, making data-driven methods a promising alternative. In this paper we introduce a full framework for learning feedback models for reactive motion planning. Our pipeline starts by segmenting demonstrations of a complete task into motion primitives via a semi-automated segmentation algorithm. Then, given additional demonstrations of successful adaptation behaviors, we learn initial feedback models through learning from demonstrations. In the final phase, a sample-efficient reinforcement learning algorithm fine-tunes these feedback models for novel task settings through few real system interactions. We evaluate our approach on a real anthropomorphic robot in learning a tactile feedback task.
A New Age of Computing and the Brain
Apr 27, 2020
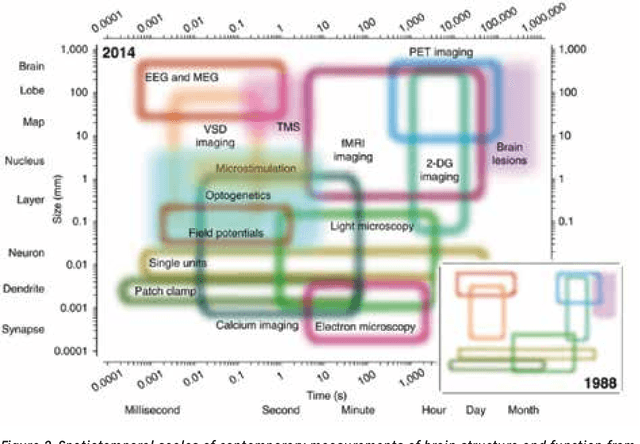
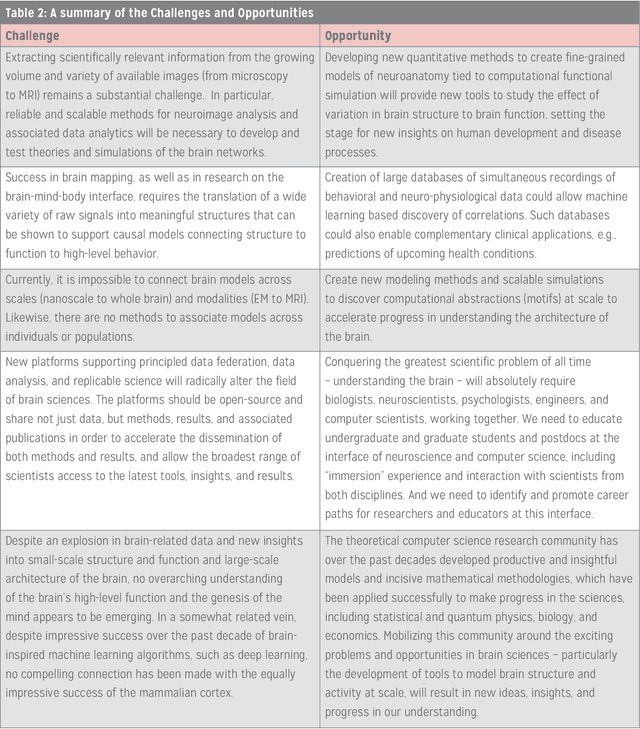
The history of computer science and brain sciences are intertwined. In his unfinished manuscript "The Computer and the Brain," von Neumann debates whether or not the brain can be thought of as a computing machine and identifies some of the similarities and differences between natural and artificial computation. Turing, in his 1950 article in Mind, argues that computing devices could ultimately emulate intelligence, leading to his proposed Turing test. Herbert Simon predicted in 1957 that most psychological theories would take the form of a computer program. In 1976, David Marr proposed that the function of the visual system could be abstracted and studied at computational and algorithmic levels that did not depend on the underlying physical substrate. In December 2014, a two-day workshop supported by the Computing Community Consortium (CCC) and the National Science Foundation's Computer and Information Science and Engineering Directorate (NSF CISE) was convened in Washington, DC, with the goal of bringing together computer scientists and brain researchers to explore these new opportunities and connections, and develop a new, modern dialogue between the two research communities. Specifically, our objectives were: 1. To articulate a conceptual framework for research at the interface of brain sciences and computing and to identify key problems in this interface, presented in a way that will attract both CISE and brain researchers into this space. 2. To inform and excite researchers within the CISE research community about brain research opportunities and to identify and explain strategic roles they can play in advancing this initiative. 3. To develop new connections, conversations and collaborations between brain sciences and CISE researchers that will lead to highly relevant and competitive proposals, high-impact research, and influential publications.
Scaling simulation-to-real transfer by learning composable robot skills
Nov 13, 2018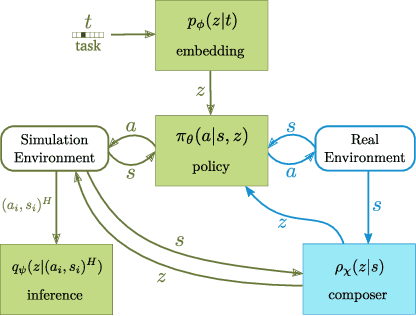
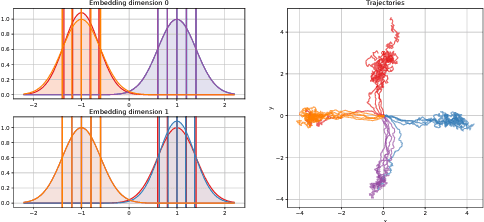

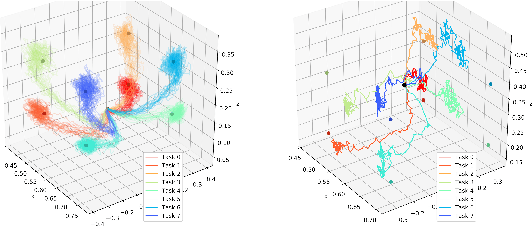
We present a novel solution to the problem of simulation-to-real transfer, which builds on recent advances in robot skill decomposition. Rather than focusing on minimizing the simulation-reality gap, we learn a set of diverse policies that are parameterized in a way that makes them easily reusable. This diversity and parameterization of low-level skills allows us to find a transferable policy that is able to use combinations and variations of different skills to solve more complex, high-level tasks. In particular, we first use simulation to jointly learn a policy for a set of low-level skills, and a "skill embedding" parameterization which can be used to compose them. Later, we learn high-level policies which actuate the low-level policies via this skill embedding parameterization. The high-level policies encode how and when to reuse the low-level skills together to achieve specific high-level tasks. Importantly, our method learns to control a real robot in joint-space to achieve these high-level tasks with little or no on-robot time, despite the fact that the low-level policies may not be perfectly transferable from simulation to real, and that the low-level skills were not trained on any examples of high-level tasks. We illustrate the principles of our method using informative simulation experiments. We then verify its usefulness for real robotics problems by learning, transferring, and composing free-space and contact motion skills on a Sawyer robot using only joint-space control. We experiment with several techniques for composing pre-learned skills, and find that our method allows us to use both learning-based approaches and efficient search-based planning to achieve high-level tasks using only pre-learned skills.