 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA System for Imitation Learning of Contact-Rich Bimanual Manipulation Policies
Aug 01, 2022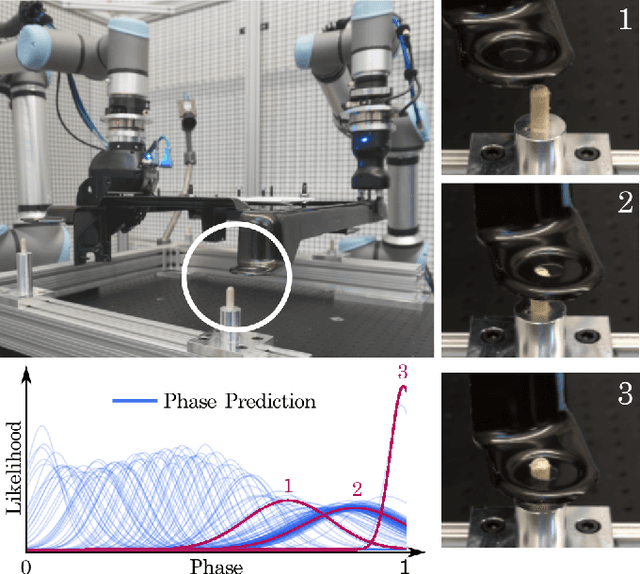
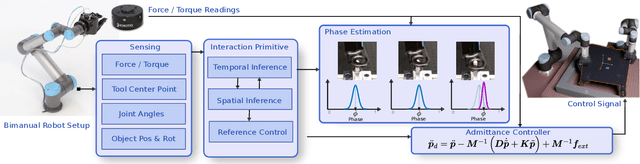

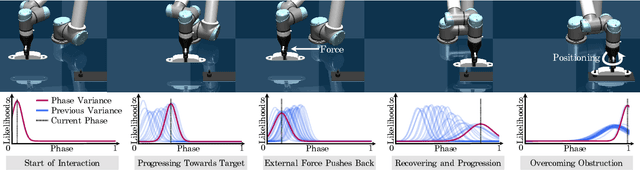
In this paper, we discuss a framework for teaching bimanual manipulation tasks by imitation. To this end, we present a system and algorithms for learning compliant and contact-rich robot behavior from human demonstrations. The presented system combines insights from admittance control and machine learning to extract control policies that can (a) recover from and adapt to a variety of disturbances in time and space, while also (b) effectively leveraging physical contact with the environment. We demonstrate the effectiveness of our approach using a real-world insertion task involving multiple simultaneous contacts between a manipulated object and insertion pegs. We also investigate efficient means of collecting training data for such bimanual settings. To this end, we conduct a human-subject study and analyze the effort and mental demand as reported by the users. Our experiments show that, while harder to provide, the additional force/torque information available in teleoperated demonstrations is crucial for phase estimation and task success. Ultimately, force/torque data substantially improves manipulation robustness, resulting in a 90% success rate in a multipoint insertion task. Code and videos can be found at https://bimanualmanipulation.com/
Detection and Physical Interaction with Deformable Linear Objects
May 17, 2022

Deformable linear objects (e.g., cables, ropes, and threads) commonly appear in our everyday lives. However, perception of these objects and the study of physical interaction with them is still a growing area. There have already been successful methods to model and track deformable linear objects. However, the number of methods that can automatically extract the initial conditions in non-trivial situations for these methods has been limited, and they have been introduced to the community only recently. On the other hand, while physical interaction with these objects has been done with ground manipulators, there have not been any studies on physical interaction and manipulation of the deformable linear object with aerial robots. This workshop describes our recent work on detecting deformable linear objects, which uses the segmentation output of the existing methods to provide the initialization required by the tracking methods automatically. It works with crossings and can fill the gaps and occlusions in the segmentation and output the model desirable for physical interaction and simulation. Then we present our work on using the method for tasks such as routing and manipulation with the ground and aerial robots. We discuss our feasibility analysis on extending the physical interaction with these objects to aerial manipulation applications.
Symbolic State Estimation with Predicates for Contact-Rich Manipulation Tasks
Mar 04, 2022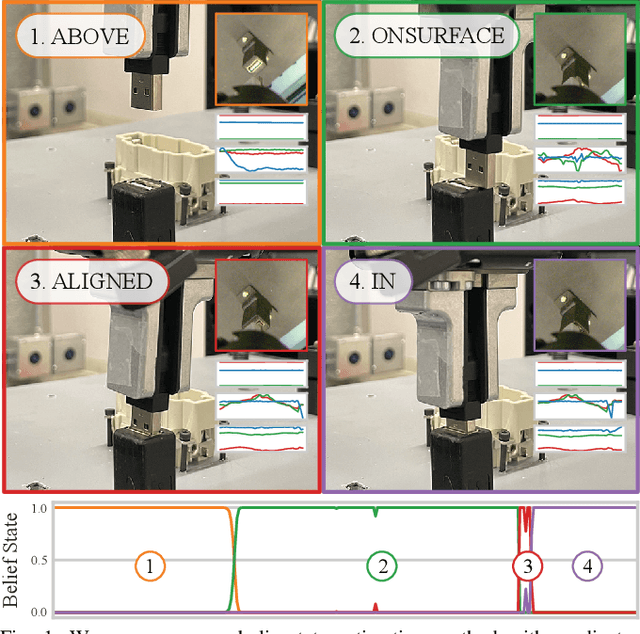

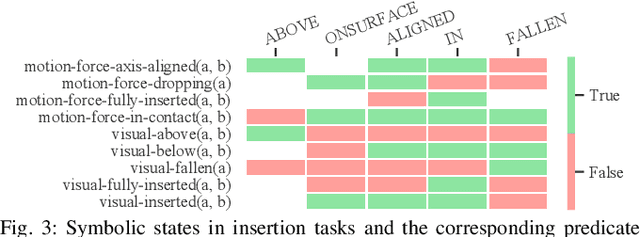
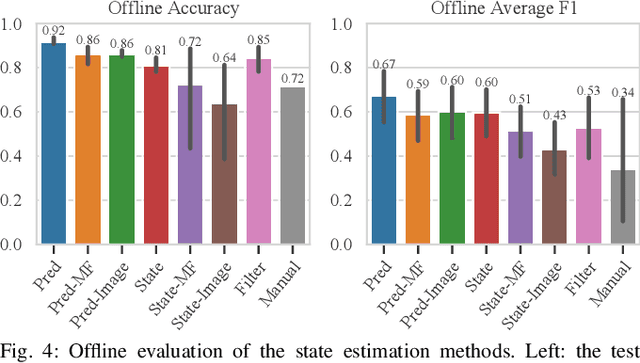
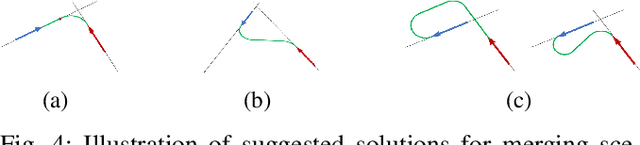
Manipulation tasks often require a robot to adjust its sensorimotor skills based on the state it finds itself in. Taking peg-in-hole as an example: once the peg is aligned with the hole, the robot should push the peg downwards. While high level execution frameworks such as state machines and behavior trees are commonly used to formalize such decision-making problems, these frameworks require a mechanism to detect the high-level symbolic state. Handcrafting heuristics to identify symbolic states can be brittle, and using data-driven methods can produce noisy predictions, particularly when working with limited datasets, as is common in real-world robotic scenarios. This paper proposes a Bayesian state estimation method to predict symbolic states with predicate classifiers. This method requires little training data and allows fusing noisy observations from multiple sensor modalities. We evaluate our framework on a set of real-world peg-in-hole and connector-socket insertion tasks, demonstrating its ability to classify symbolic states and to generalize to unseen tasks, outperforming baseline methods. We also demonstrate the ability of our method to improve the robustness of manipulation policies on a real robot.
Efficient Spatial Representation and Routing of Deformable One-Dimensional Objects for Manipulation
Feb 13, 2022



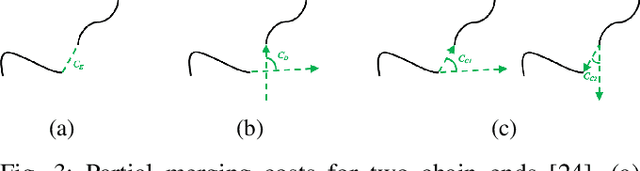
With the field of rigid-body robotics having matured in the last fifty years, routing, planning, and manipulation of deformable objects have emerged in recent years as a more untouched research area in many fields ranging from surgical robotics to industrial assembly and construction. Routing approaches for deformable objects which rely on learned implicit spatial representations (e.g., Learning-from-Demonstration methods) make them vulnerable to changes in the environment and the specific setup. On the other hand, algorithms that entirely separate the spatial representation of the deformable object from the routing and manipulation, often using a representation approach independent of planning, result in slow planning in high dimensional space. This paper proposes a novel approach to spatial representation combined with route planning that allows efficient routing of deformable one-dimensional objects (e.g., wires, cables, ropes, threads). The spatial representation is based on the geometrical decomposition of the space into convex subspaces, which allows an efficient coding of the configuration. Having such a configuration, the routing problem can be solved using a dynamic programming matching method with a quadratic time and space complexity. The proposed method couples the routing and efficient configuration for improved planning time. Our tests and experiments show the method correctly computing the next manipulation action in sub-millisecond time and accomplishing various routing and manipulation tasks.
You Only Demonstrate Once: Category-Level Manipulation from Single Visual Demonstration
Jan 30, 2022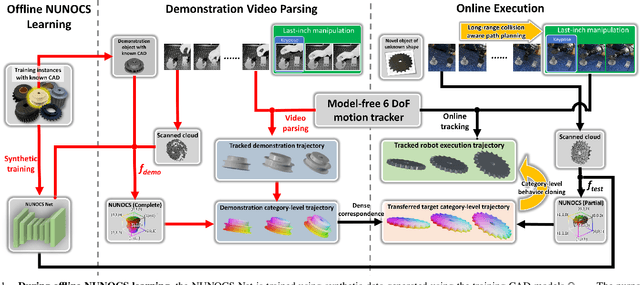
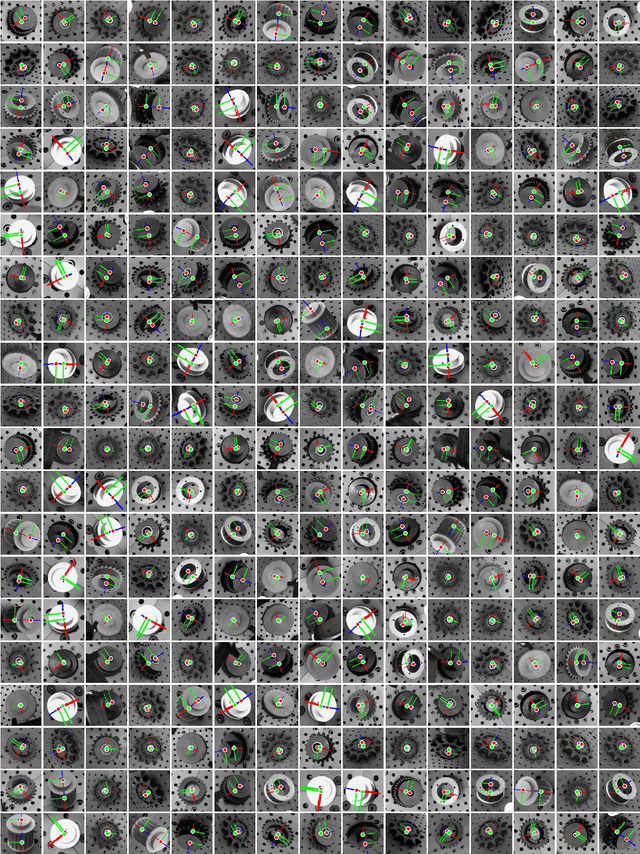


Promising results have been achieved recently in category-level manipulation that generalizes across object instances. Nevertheless, it often requires expensive real-world data collection and manual specification of semantic keypoints for each object category and task. Additionally, coarse keypoint predictions and ignoring intermediate action sequences hinder adoption in complex manipulation tasks beyond pick-and-place. This work proposes a novel, category-level manipulation framework that leverages an object-centric, category-level representation and model-free 6 DoF motion tracking. The canonical object representation is learned solely in simulation and then used to parse a category-level, task trajectory from a single demonstration video. The demonstration is reprojected to a target trajectory tailored to a novel object via the canonical representation. During execution, the manipulation horizon is decomposed into long-range, collision-free motion and last-inch manipulation. For the latter part, a category-level behavior cloning (CatBC) method leverages motion tracking to perform closed-loop control. CatBC follows the target trajectory, projected from the demonstration and anchored to a dynamically selected category-level coordinate frame. The frame is automatically selected along the manipulation horizon by a local attention mechanism. This framework allows to teach different manipulation strategies by solely providing a single demonstration, without complicated manual programming. Extensive experiments demonstrate its efficacy in a range of challenging industrial tasks in high-precision assembly, which involve learning complex, long-horizon policies. The process exhibits robustness against uncertainty due to dynamics as well as generalization across object instances and scene configurations.
Deformable One-Dimensional Object Detection for Routing and Manipulation
Jan 18, 2022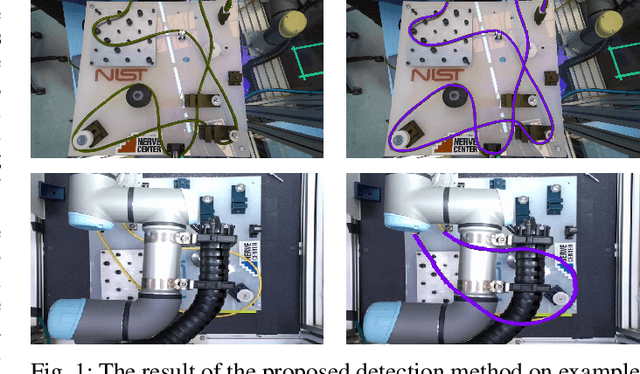
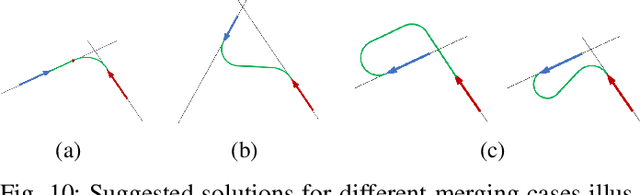
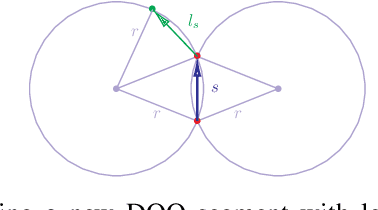

Many methods exist to model and track deformable one-dimensional objects (e.g., cables, ropes, and threads) across a stream of video frames. However, these methods depend on the existence of some initial conditions. To the best of our knowledge, the topic of detection methods that can extract those initial conditions in non-trivial situations has hardly been addressed. The lack of detection methods limits the use of the tracking methods in real-world applications and is a bottleneck for fully autonomous applications that work with these objects. This paper proposes an approach for detecting deformable one-dimensional objects which can handle crossings and occlusions. It can be used for tasks such as routing and manipulation and automatically provides the initialization required by the tracking methods. Our algorithm takes an image containing a deformable object and outputs a chain of fixed-length cylindrical segments connected with passive spherical joints. The chain follows the natural behavior of the deformable object and fills the gaps and occlusions in the original image. Our tests and experiments have shown that the method can correctly detect deformable one-dimensional objects in various complex conditions.
Wish you were here: Hindsight Goal Selection for long-horizon dexterous manipulation
Dec 02, 2021
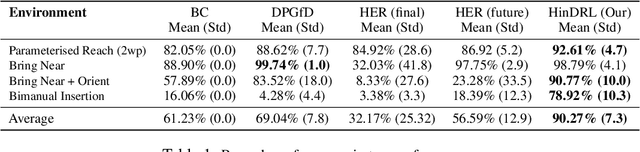
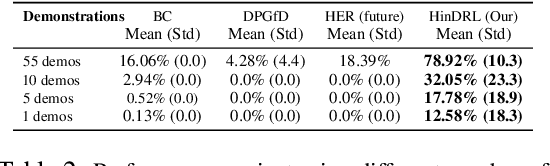

Complex sequential tasks in continuous-control settings often require agents to successfully traverse a set of "narrow passages" in their state space. Solving such tasks with a sparse reward in a sample-efficient manner poses a challenge to modern reinforcement learning (RL) due to the associated long-horizon nature of the problem and the lack of sufficient positive signal during learning. Various tools have been applied to address this challenge. When available, large sets of demonstrations can guide agent exploration. Hindsight relabelling on the other hand does not require additional sources of information. However, existing strategies explore based on task-agnostic goal distributions, which can render the solution of long-horizon tasks impractical. In this work, we extend hindsight relabelling mechanisms to guide exploration along task-specific distributions implied by a small set of successful demonstrations. We evaluate the approach on four complex, single and dual arm, robotics manipulation tasks against strong suitable baselines. The method requires far fewer demonstrations to solve all tasks and achieves a significantly higher overall performance as task complexity increases. Finally, we investigate the robustness of the proposed solution with respect to the quality of input representations and the number of demonstrations.
From Machine Learning to Robotics: Challenges and Opportunities for Embodied Intelligence
Oct 28, 2021
Machine learning has long since become a keystone technology, accelerating science and applications in a broad range of domains. Consequently, the notion of applying learning methods to a particular problem set has become an established and valuable modus operandi to advance a particular field. In this article we argue that such an approach does not straightforwardly extended to robotics -- or to embodied intelligence more generally: systems which engage in a purposeful exchange of energy and information with a physical environment. In particular, the purview of embodied intelligent agents extends significantly beyond the typical considerations of main-stream machine learning approaches, which typically (i) do not consider operation under conditions significantly different from those encountered during training; (ii) do not consider the often substantial, long-lasting and potentially safety-critical nature of interactions during learning and deployment; (iii) do not require ready adaptation to novel tasks while at the same time (iv) effectively and efficiently curating and extending their models of the world through targeted and deliberate actions. In reality, therefore, these limitations result in learning-based systems which suffer from many of the same operational shortcomings as more traditional, engineering-based approaches when deployed on a robot outside a well defined, and often narrow operating envelope. Contrary to viewing embodied intelligence as another application domain for machine learning, here we argue that it is in fact a key driver for the advancement of machine learning technology. In this article our goal is to highlight challenges and opportunities that are specific to embodied intelligence and to propose research directions which may significantly advance the state-of-the-art in robot learning.
Offline Meta-Reinforcement Learning for Industrial Insertion
Oct 12, 2021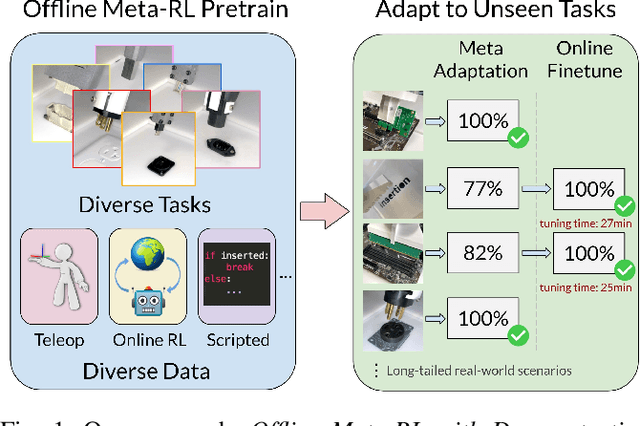
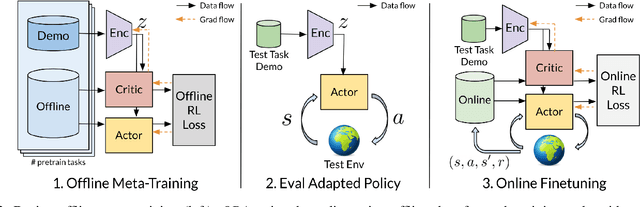


Reinforcement learning (RL) can in principle make it possible for robots to automatically adapt to new tasks, but in practice current RL methods require a very large number of trials to accomplish this. In this paper, we tackle rapid adaptation to new tasks through the framework of meta-learning, which utilizes past tasks to learn to adapt, with a specific focus on industrial insertion tasks. We address two specific challenges by applying meta-learning in this setting. First, conventional meta-RL algorithms require lengthy online meta-training phases. We show that this can be replaced with appropriately chosen offline data, resulting in an offline meta-RL method that only requires demonstrations and trials from each of the prior tasks, without the need to run costly meta-RL procedures online. Second, meta-RL methods can fail to generalize to new tasks that are too different from those seen at meta-training time, which poses a particular challenge in industrial applications, where high success rates are critical. We address this by combining contextual meta-learning with direct online finetuning: if the new task is similar to those seen in the prior data, then the contextual meta-learner adapts immediately, and if it is too different, it gradually adapts through finetuning. We show that our approach is able to quickly adapt to a variety of different insertion tasks, learning how to perform them with a success rate of 100% using only a fraction of the samples needed for learning the tasks from scratch. Experiment videos and details are available at https://sites.google.com/view/offline-metarl-insertion.
CaTGrasp: Learning Category-Level Task-Relevant Grasping in Clutter from Simulation
Sep 19, 2021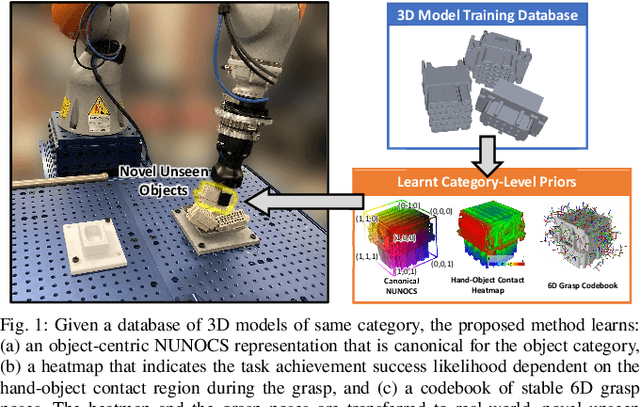
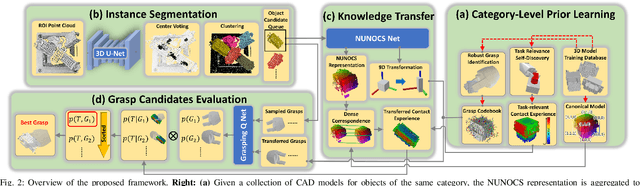
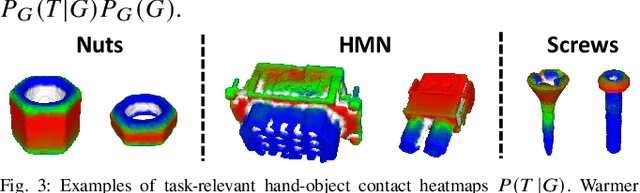
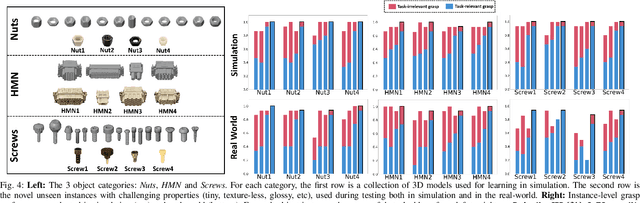
Task-relevant grasping is critical for industrial assembly, where downstream manipulation tasks constrain the set of valid grasps. Learning how to perform this task, however, is challenging, since task-relevant grasp labels are hard to define and annotate. There is also yet no consensus on proper representations for modeling or off-the-shelf tools for performing task-relevant grasps. This work proposes a framework to learn task-relevant grasping for industrial objects without the need of time-consuming real-world data collection or manual annotation. To achieve this, the entire framework is trained solely in simulation, including supervised training with synthetic label generation and self-supervised, hand-object interaction. In the context of this framework, this paper proposes a novel, object-centric canonical representation at the category level, which allows establishing dense correspondence across object instances and transferring task-relevant grasps to novel instances. Extensive experiments on task-relevant grasping of densely-cluttered industrial objects are conducted in both simulation and real-world setups, demonstrating the effectiveness of the proposed framework. Code and data will be released upon acceptance at https://sites.google.com/view/catgrasp.