 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState and Trajectory Estimation of Tensegrity Robots via Factor Graphs and Chebyshev Polynomials
Apr 09, 2026Tensegrity robots offer compliance and adaptability, but their nonlinear, and underconstrained dynamics make state estimation challenging. Reliable continuous-time estimation of all rigid links is crucial for closed-loop control, system identification, and machine learning; however, conventional methods often fall short. This paper proposes a two-stage approach for robust state or trajectory estimation (i.e., filtering or smoothing) of a cable-driven tensegrity robot. For online state estimation, this work introduces a factor-graph-based method, which fuses measurements from an RGB-D camera with on-board cable length sensors. To the best of the authors' knowledge, this is the first application of factor graphs in this domain. Factor graphs are a natural choice, as they exploit the robot's structural properties and provide effective sensor fusion solutions capable of handling nonlinearities in practice. Both the Mahalanobis distance-based clustering algorithm, used to handle noise, and the Chebyshev polynomial method, used to estimate the most probable velocities and intermediate states, are shown to perform well on simulated and real-world data, compared to an ICP-based algorithm. Results show that the approach provides high fidelity, continuous-time state and trajectory estimates for complex tensegrity robot motions.
CableRobotGraphSim: A Graph Neural Network for Modeling Partially Observable Cable-Driven Robot Dynamics
Feb 24, 2026General-purpose simulators have accelerated the development of robots. Traditional simulators based on first-principles, however, typically require full-state observability or depend on parameter search for system identification. This work presents \texttt{CableRobotGraphSim}, a novel Graph Neural Network (GNN) model for cable-driven robots that aims to address shortcomings of prior simulation solutions. By representing cable-driven robots as graphs, with the rigid-bodies as nodes and the cables and contacts as edges, this model can quickly and accurately match the properties of other simulation models and real robots, while ingesting only partially observable inputs. Accompanying the GNN model is a sim-and-real co-training procedure that promotes generalization and robustness to noisy real data. This model is further integrated with a Model Predictive Path Integral (MPPI) controller for closed-loop navigation, which showcases the model's speed and accuracy.
Robust Out-of-Order Retrieval for Grid-Based Storage at Maximum Capacity
Jan 27, 2026This paper proposes a framework for improving the operational efficiency of automated storage systems under uncertainty. It considers a 2D grid-based storage for uniform-sized loads (e.g., containers, pallets, or totes), which are moved by a robot (or other manipulator) along a collision-free path in the grid. The loads are labeled (i.e., unique) and must be stored in a given sequence, and later be retrieved in a different sequence -- an operational pattern that arises in logistics applications, such as last-mile distribution centers and shipyards. The objective is to minimize the load relocations to ensure efficient retrieval. A previous result guarantees a zero-relocation solution for known storage and retrieval sequences, even for storage at full capacity, provided that the side of the grid through which loads are stored/retrieved is at least 3 cells wide. However, in practice, the retrieval sequence can change after the storage phase. To address such uncertainty, this work investigates \emph{$k$-bounded perturbations} during retrieval, under which any two loads may depart out of order if they are originally at most $k$ positions apart. We prove that a $Θ(k)$ grid width is necessary and sufficient for eliminating relocations at maximum capacity. We also provide an efficient solver for computing a storage arrangement that is robust to such perturbations. To address the higher-uncertainty case where perturbations exceed $k$, a strategy is introduced to effectively minimize relocations. Extensive experiments show that, for $k$ up to half the grid width, the proposed storage-retrieval framework essentially eliminates relocations. For $k$ values up to the full grid width, relocations are reduced by $50\%+$.
Fully Packed and Ready to Go: High-Density, Rearrangement-Free, Grid-Based Storage and Retrieval
May 28, 2025Grid-based storage systems with uniformly shaped loads (e.g., containers, pallets, totes) are commonplace in logistics, industrial, and transportation domains. A key performance metric for such systems is the maximization of space utilization, which requires some loads to be placed behind or below others, preventing direct access to them. Consequently, dense storage settings bring up the challenge of determining how to place loads while minimizing costly rearrangement efforts necessary during retrieval. This paper considers the setting involving an inbound phase, during which loads arrive, followed by an outbound phase, during which loads depart. The setting is prevalent in distribution centers, automated parking garages, and container ports. In both phases, minimizing the number of rearrangement actions results in more optimal (e.g., fast, energy-efficient, etc.) operations. In contrast to previous work focusing on stack-based systems, this effort examines the case where loads can be freely moved along the grid, e.g., by a mobile robot, expanding the range of possible motions. We establish that for a range of scenarios, such as having limited prior knowledge of the loads' arrival sequences or grids with a narrow opening, a (best possible) rearrangement-free solution always exists, including when the loads fill the grid to its capacity. In particular, when the sequences are fully known, we establish an intriguing characterization showing that rearrangement can always be avoided if and only if the open side of the grid (used to access the storage) is at least 3 cells wide. We further discuss useful practical implications of our solutions.
Developing Modular Grasping and Manipulation Pipeline Infrastructure to Streamline Performance Benchmarking
Apr 09, 2025The robot manipulation ecosystem currently faces issues with integrating open-source components and reproducing results. This limits the ability of the community to benchmark and compare the performance of different solutions to one another in an effective manner, instead relying on largely holistic evaluations. As part of the COMPARE Ecosystem project, we are developing modular grasping and manipulation pipeline infrastructure in order to streamline performance benchmarking. The infrastructure will be used towards the establishment of standards and guidelines for modularity and improved open-source development and benchmarking. This paper provides a high-level overview of the architecture of the pipeline infrastructure, experiments conducted to exercise it during development, and future work to expand its modularity.
Impact-resistant, autonomous robots inspired by tensegrity architecture
Jan 25, 2025



Future robots will navigate perilous, remote environments with resilience and autonomy. Researchers have proposed building robots with compliant bodies to enhance robustness, but this approach often sacrifices the autonomous capabilities expected of rigid robots. Inspired by tensegrity architecture, we introduce a tensegrity robot -- a hybrid robot made from rigid struts and elastic tendons -- that demonstrates the advantages of compliance and the autonomy necessary for task performance. This robot boasts impact resistance and autonomy in a field environment and additional advances in the state of the art, including surviving harsh impacts from drops (at least 5.7 m), accurately reconstructing its shape and orientation using on-board sensors, achieving high locomotion speeds (18 bar lengths per minute), and climbing the steepest incline of any tensegrity robot (28 degrees). We characterize the robot's locomotion on unstructured terrain, showcase its autonomous capabilities in navigation tasks, and demonstrate its robustness by rolling it off a cliff.
Learning Differentiable Tensegrity Dynamics using Graph Neural Networks
Oct 16, 2024



Tensegrity robots are composed of rigid struts and flexible cables. They constitute an emerging class of hybrid rigid-soft robotic systems and are promising systems for a wide array of applications, ranging from locomotion to assembly. They are difficult to control and model accurately, however, due to their compliance and high number of degrees of freedom. To address this issue, prior work has introduced a differentiable physics engine designed for tensegrity robots based on first principles. In contrast, this work proposes the use of graph neural networks to model contact dynamics over a graph representation of tensegrity robots, which leverages their natural graph-like cable connectivity between end caps of rigid rods. This learned simulator can accurately model 3-bar and 6-bar tensegrity robot dynamics in simulation-to-simulation experiments where MuJoCo is used as the ground truth. It can also achieve higher accuracy than the previous differentiable engine for a real 3-bar tensegrity robot, for which the robot state is only partially observable. When compared against direct applications of recent mesh-based graph neural network simulators, the proposed approach is computationally more efficient, both for training and inference, while achieving higher accuracy. Code and data are available at https://github.com/nchen9191/tensegrity_gnn_simulator_public
OVIR-3D: Open-Vocabulary 3D Instance Retrieval Without Training on 3D Data
Nov 06, 2023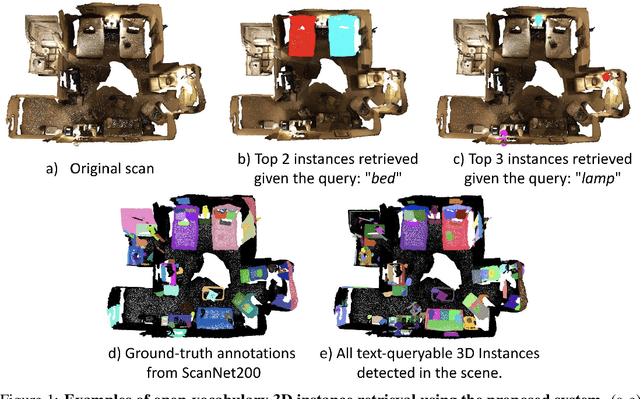
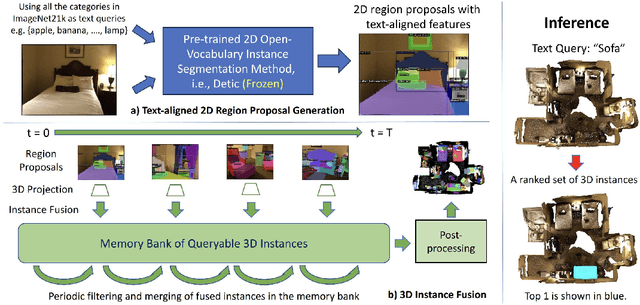
This work presents OVIR-3D, a straightforward yet effective method for open-vocabulary 3D object instance retrieval without using any 3D data for training. Given a language query, the proposed method is able to return a ranked set of 3D object instance segments based on the feature similarity of the instance and the text query. This is achieved by a multi-view fusion of text-aligned 2D region proposals into 3D space, where the 2D region proposal network could leverage 2D datasets, which are more accessible and typically larger than 3D datasets. The proposed fusion process is efficient as it can be performed in real-time for most indoor 3D scenes and does not require additional training in 3D space. Experiments on public datasets and a real robot show the effectiveness of the method and its potential for applications in robot navigation and manipulation.
Socially Cognizant Robotics for a Technology Enhanced Society
Oct 27, 2023



Emerging applications of robotics, and concerns about their impact, require the research community to put human-centric objectives front-and-center. To meet this challenge, we advocate an interdisciplinary approach, socially cognizant robotics, which synthesizes technical and social science methods. We argue that this approach follows from the need to empower stakeholder participation (from synchronous human feedback to asynchronous societal assessment) in shaping AI-driven robot behavior at all levels, and leads to a range of novel research perspectives and problems both for improving robots' interactions with individuals and impacts on society. Drawing on these arguments, we develop best practices for socially cognizant robot design that balance traditional technology-based metrics (e.g. efficiency, precision and accuracy) with critically important, albeit challenging to measure, human and society-based metrics.
Context-Aware Entity Grounding with Open-Vocabulary 3D Scene Graphs
Sep 27, 2023



We present an Open-Vocabulary 3D Scene Graph (OVSG), a formal framework for grounding a variety of entities, such as object instances, agents, and regions, with free-form text-based queries. Unlike conventional semantic-based object localization approaches, our system facilitates context-aware entity localization, allowing for queries such as ``pick up a cup on a kitchen table" or ``navigate to a sofa on which someone is sitting". In contrast to existing research on 3D scene graphs, OVSG supports free-form text input and open-vocabulary querying. Through a series of comparative experiments using the ScanNet dataset and a self-collected dataset, we demonstrate that our proposed approach significantly surpasses the performance of previous semantic-based localization techniques. Moreover, we highlight the practical application of OVSG in real-world robot navigation and manipulation experiments.