 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairDeDup: Detecting and Mitigating Vision-Language Fairness Disparities in Semantic Dataset Deduplication
Apr 24, 2024



Recent dataset deduplication techniques have demonstrated that content-aware dataset pruning can dramatically reduce the cost of training Vision-Language Pretrained (VLP) models without significant performance losses compared to training on the original dataset. These results have been based on pruning commonly used image-caption datasets collected from the web -- datasets that are known to harbor harmful social biases that may then be codified in trained models. In this work, we evaluate how deduplication affects the prevalence of these biases in the resulting trained models and introduce an easy-to-implement modification to the recent SemDeDup algorithm that can reduce the negative effects that we observe. When examining CLIP-style models trained on deduplicated variants of LAION-400M, we find our proposed FairDeDup algorithm consistently leads to improved fairness metrics over SemDeDup on the FairFace and FACET datasets while maintaining zero-shot performance on CLIP benchmarks.
VLSlice: Interactive Vision-and-Language Slice Discovery
Sep 13, 2023



Recent work in vision-and-language demonstrates that large-scale pretraining can learn generalizable models that are efficiently transferable to downstream tasks. While this may improve dataset-scale aggregate metrics, analyzing performance around hand-crafted subgroups targeting specific bias dimensions reveals systemic undesirable behaviors. However, this subgroup analysis is frequently stalled by annotation efforts, which require extensive time and resources to collect the necessary data. Prior art attempts to automatically discover subgroups to circumvent these constraints but typically leverages model behavior on existing task-specific annotations and rapidly degrades on more complex inputs beyond "tabular" data, none of which study vision-and-language models. This paper presents VLSlice, an interactive system enabling user-guided discovery of coherent representation-level subgroups with consistent visiolinguistic behavior, denoted as vision-and-language slices, from unlabeled image sets. We show that VLSlice enables users to quickly generate diverse high-coherency slices in a user study (n=22) and release the tool publicly.
Behavioral Analysis of Vision-and-Language Navigation Agents
Jul 20, 2023



To be successful, Vision-and-Language Navigation (VLN) agents must be able to ground instructions to actions based on their surroundings. In this work, we develop a methodology to study agent behavior on a skill-specific basis -- examining how well existing agents ground instructions about stopping, turning, and moving towards specified objects or rooms. Our approach is based on generating skill-specific interventions and measuring changes in agent predictions. We present a detailed case study analyzing the behavior of a recent agent and then compare multiple agents in terms of skill-specific competency scores. This analysis suggests that biases from training have lasting effects on agent behavior and that existing models are able to ground simple referring expressions. Our comparisons between models show that skill-specific scores correlate with improvements in overall VLN task performance.
* accepted to CVPR2023
Navigating to Objects Specified by Images
Apr 03, 2023



Images are a convenient way to specify which particular object instance an embodied agent should navigate to. Solving this task requires semantic visual reasoning and exploration of unknown environments. We present a system that can perform this task in both simulation and the real world. Our modular method solves sub-tasks of exploration, goal instance re-identification, goal localization, and local navigation. We re-identify the goal instance in egocentric vision using feature-matching and localize the goal instance by projecting matched features to a map. Each sub-task is solved using off-the-shelf components requiring zero fine-tuning. On the HM3D InstanceImageNav benchmark, this system outperforms a baseline end-to-end RL policy 7x and a state-of-the-art ImageNav model 2.3x (56% vs 25% success). We deploy this system to a mobile robot platform and demonstrate effective real-world performance, achieving an 88% success rate across a home and an office environment.
Emergence of Maps in the Memories of Blind Navigation Agents
Jan 30, 2023Animal navigation research posits that organisms build and maintain internal spatial representations, or maps, of their environment. We ask if machines -- specifically, artificial intelligence (AI) navigation agents -- also build implicit (or 'mental') maps. A positive answer to this question would (a) explain the surprising phenomenon in recent literature of ostensibly map-free neural-networks achieving strong performance, and (b) strengthen the evidence of mapping as a fundamental mechanism for navigation by intelligent embodied agents, whether they be biological or artificial. Unlike animal navigation, we can judiciously design the agent's perceptual system and control the learning paradigm to nullify alternative navigation mechanisms. Specifically, we train 'blind' agents -- with sensing limited to only egomotion and no other sensing of any kind -- to perform PointGoal navigation ('go to $\Delta$ x, $\Delta$ y') via reinforcement learning. Our agents are composed of navigation-agnostic components (fully-connected and recurrent neural networks), and our experimental setup provides no inductive bias towards mapping. Despite these harsh conditions, we find that blind agents are (1) surprisingly effective navigators in new environments (~95% success); (2) they utilize memory over long horizons (remembering ~1,000 steps of past experience in an episode); (3) this memory enables them to exhibit intelligent behavior (following walls, detecting collisions, taking shortcuts); (4) there is emergence of maps and collision detection neurons in the representations of the environment built by a blind agent as it navigates; and (5) the emergent maps are selective and task dependent (e.g. the agent 'forgets' exploratory detours). Overall, this paper presents no new techniques for the AI audience, but a surprising finding, an insight, and an explanation.
Instance-Specific Image Goal Navigation: Training Embodied Agents to Find Object Instances
Nov 29, 2022



We consider the problem of embodied visual navigation given an image-goal (ImageNav) where an agent is initialized in an unfamiliar environment and tasked with navigating to a location 'described' by an image. Unlike related navigation tasks, ImageNav does not have a standardized task definition which makes comparison across methods difficult. Further, existing formulations have two problematic properties; (1) image-goals are sampled from random locations which can lead to ambiguity (e.g., looking at walls), and (2) image-goals match the camera specification and embodiment of the agent; this rigidity is limiting when considering user-driven downstream applications. We present the Instance-specific ImageNav task (InstanceImageNav) to address these limitations. Specifically, the goal image is 'focused' on some particular object instance in the scene and is taken with camera parameters independent of the agent. We instantiate InstanceImageNav in the Habitat Simulator using scenes from the Habitat-Matterport3D dataset (HM3D) and release a standardized benchmark to measure community progress.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

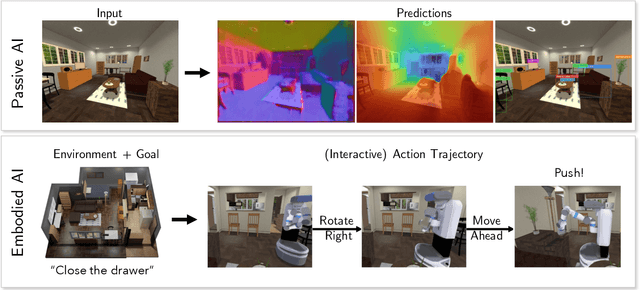
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Iterative Vision-and-Language Navigation
Oct 06, 2022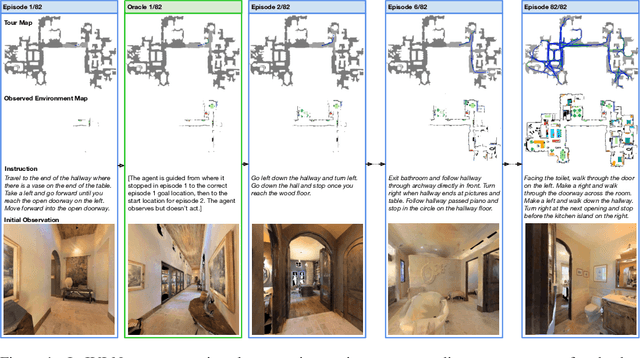
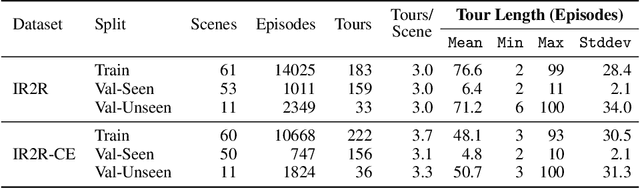
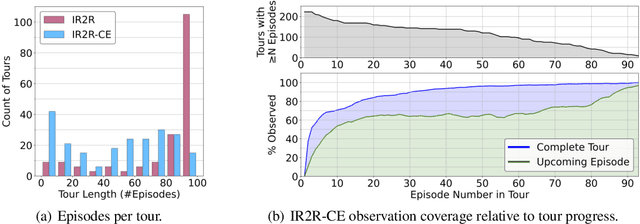

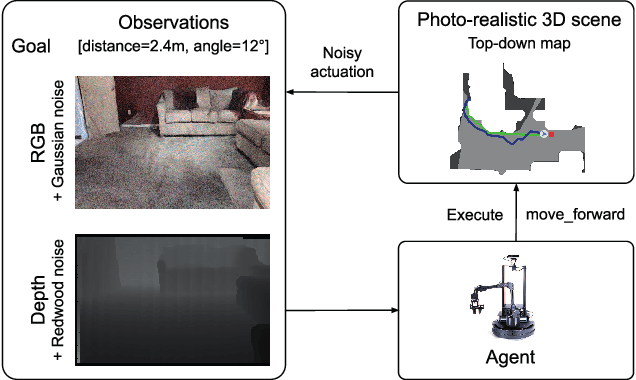
We present Iterative Vision-and-Language Navigation (IVLN), a paradigm for evaluating language-guided agents navigating in a persistent environment over time. Existing Vision-and-Language Navigation (VLN) benchmarks erase the agent's memory at the beginning of every episode, testing the ability to perform cold-start navigation with no prior information. However, deployed robots occupy the same environment for long periods of time. The IVLN paradigm addresses this disparity by training and evaluating VLN agents that maintain memory across tours of scenes that consist of up to 100 ordered instruction-following Room-to-Room (R2R) episodes, each defined by an individual language instruction and a target path. We present discrete and continuous Iterative Room-to-Room (IR2R) benchmarks comprising about 400 tours each in 80 indoor scenes. We find that extending the implicit memory of high-performing transformer VLN agents is not sufficient for IVLN, but agents that build maps can benefit from environment persistence, motivating a renewed focus on map-building agents in VLN.
Sim-2-Sim Transfer for Vision-and-Language Navigation in Continuous Environments
Apr 24, 2022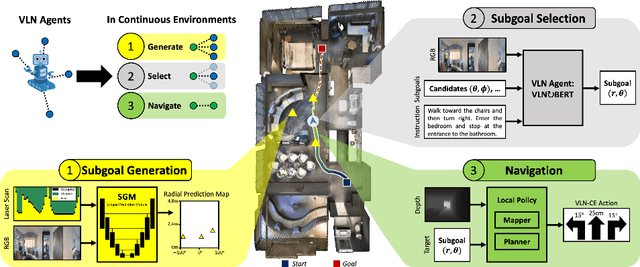


Recent work in Vision-and-Language Navigation (VLN) has presented two environmental paradigms with differing realism -- the standard VLN setting built on topological environments where navigation is abstracted away, and the VLN-CE setting where agents must navigate continuous 3D environments using low-level actions. Despite sharing the high-level task and even the underlying instruction-path data, performance on VLN-CE lags behind VLN significantly. In this work, we explore this gap by transferring an agent from the abstract environment of VLN to the continuous environment of VLN-CE. We find that this sim-2-sim transfer is highly effective, improving over the prior state of the art in VLN-CE by +12% success rate. While this demonstrates the potential for this direction, the transfer does not fully retain the original performance of the agent in the abstract setting. We present a sequence of experiments to identify what differences result in performance degradation, providing clear directions for further improvement.
PROMPT: Learning Dynamic Resource Allocation Policies for Edge-Network Applications
Jan 19, 2022



A growing number of service providers are exploring methods to improve server utilization, reduce power consumption, and reduce total cost of ownership by co-scheduling high-priority latency-critical workloads with best-effort workloads. This practice requires strict resource allocation between workloads to reduce resource contention and maintain Quality of Service (QoS) guarantees. Prior resource allocation works have been shown to improve server utilization under ideal circumstances, yet often compromise QoS guarantees or fail to find valid resource allocations in more dynamic operating environments. Further, prior works are fundamentally reliant upon QoS measurements that can, in practice, exhibit significant transient fluctuations, thus stable control behavior cannot be reliably achieved. In this paper, we propose a novel framework for dynamic resource allocation based on proactive QoS prediction. These predictions help guide a reinforcement-learning-based resource controller towards optimal resource allocations while avoiding transient QoS violations due to fluctuating workload demands. Evaluation shows that the proposed method incurs 4.3x fewer QoS violations, reduces severity of QoS violations by 3.7x, improves best-effort workload performance, and improves overall power efficiency compared with prior work.