 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconfigurable Data Glove for Reconstructing Physical and Virtual Grasps
Jan 18, 2023We present a reconfigurable data glove design to capture different modes of human hand-object interactions, critical for training embodied AI agents for fine manipulation tasks. Sharing a unified backbone design that reconstructs hand gestures in real-time, our reconfigurable data glove operates in three modes for various downstream tasks with distinct features. In the tactile-sensing mode, the glove system aggregates manipulation force via customized force sensors made from a soft and thin piezoresistive material; this design is to minimize interference during complex hand movements. The Virtual Reality (VR) mode enables real-time interaction in a physically plausible fashion; a caging-based approach is devised to determine stable grasps by detecting collision events. Leveraging a state-of-the-art Finite Element Method (FEM) simulator, the simulation mode collects a fine-grained 4D manipulation event: hand and object motions in 3D space and how the object's physical properties (e.g., stress, energy) change in accord with the manipulation in time. Of note, this glove system is the first to look into, through high-fidelity simulation, the unobservable physical and causal factors behind manipulation actions. In a series of experiments, we characterize our data glove in terms of individual sensors and the overall system. Specifically, we evaluate the system's three modes by (i) recording hand gestures and associated forces, (ii) improving manipulation fluency in VR, and (iii) producing realistic simulation effects of various tool uses, respectively. Together, our reconfigurable data glove collects and reconstructs fine-grained human grasp data in both the physical and virtual environments, opening up new avenues to learning manipulation skills for embodied AI agents.
Diffusion-based Generation, Optimization, and Planning in 3D Scenes
Jan 15, 2023We introduce SceneDiffuser, a conditional generative model for 3D scene understanding. SceneDiffuser provides a unified model for solving scene-conditioned generation, optimization, and planning. In contrast to prior works, SceneDiffuser is intrinsically scene-aware, physics-based, and goal-oriented. With an iterative sampling strategy, SceneDiffuser jointly formulates the scene-aware generation, physics-based optimization, and goal-oriented planning via a diffusion-based denoising process in a fully differentiable fashion. Such a design alleviates the discrepancies among different modules and the posterior collapse of previous scene-conditioned generative models. We evaluate SceneDiffuser with various 3D scene understanding tasks, including human pose and motion generation, dexterous grasp generation, path planning for 3D navigation, and motion planning for robot arms. The results show significant improvements compared with previous models, demonstrating the tremendous potential of SceneDiffuser for the broad community of 3D scene understanding.
On the Complexity of Bayesian Generalization
Nov 26, 2022



We consider concept generalization at a large scale in the diverse and natural visual spectrum. Established computational modes (i.e., rule-based or similarity-based) are primarily studied isolated and focus on confined and abstract problem spaces. In this work, we study these two modes when the problem space scales up, and the $complexity$ of concepts becomes diverse. Specifically, at the $representational \ level$, we seek to answer how the complexity varies when a visual concept is mapped to the representation space. Prior psychology literature has shown that two types of complexities (i.e., subjective complexity and visual complexity) (Griffiths and Tenenbaum, 2003) build an inverted-U relation (Donderi, 2006; Sun and Firestone, 2021). Leveraging Representativeness of Attribute (RoA), we computationally confirm the following observation: Models use attributes with high RoA to describe visual concepts, and the description length falls in an inverted-U relation with the increment in visual complexity. At the $computational \ level$, we aim to answer how the complexity of representation affects the shift between the rule- and similarity-based generalization. We hypothesize that category-conditioned visual modeling estimates the co-occurrence frequency between visual and categorical attributes, thus potentially serving as the prior for the natural visual world. Experimental results show that representations with relatively high subjective complexity outperform those with relatively low subjective complexity in the rule-based generalization, while the trend is the opposite in the similarity-based generalization.
Learning Probabilistic Models from Generator Latent Spaces with Hat EBM
Oct 29, 2022



This work proposes a method for using any generator network as the foundation of an Energy-Based Model (EBM). Our formulation posits that observed images are the sum of unobserved latent variables passed through the generator network and a residual random variable that spans the gap between the generator output and the image manifold. One can then define an EBM that includes the generator as part of its forward pass, which we call the Hat EBM. The model can be trained without inferring the latent variables of the observed data or calculating the generator Jacobian determinant. This enables explicit probabilistic modeling of the output distribution of any type of generator network. Experiments show strong performance of the proposed method on (1) unconditional ImageNet synthesis at 128x128 resolution, (2) refining the output of existing generators, and (3) learning EBMs that incorporate non-probabilistic generators. Code and pretrained models to reproduce our results are available at https://github.com/point0bar1/hat-ebm.
RulE: Neural-Symbolic Knowledge Graph Reasoning with Rule Embedding
Oct 24, 2022



Knowledge graph (KG) reasoning is an important problem for knowledge graphs. It predicts missing links by reasoning on existing facts. Knowledge graph embedding (KGE) is one of the most popular methods to address this problem. It embeds entities and relations into low-dimensional vectors and uses the learned entity/relation embeddings to predict missing facts. However, KGE only uses zeroth-order (propositional) logic to encode existing triplets (e.g., ``Alice is Bob's wife."); it is unable to leverage first-order (predicate) logic to represent generally applicable logical \textbf{rules} (e.g., ``$\forall x,y \colon x ~\text{is}~ y\text{'s wife} \rightarrow y ~\text{is}~ x\text{'s husband}$''). On the other hand, traditional rule-based KG reasoning methods usually rely on hard logical rule inference, making it brittle and hardly competitive with KGE. In this paper, we propose RulE, a novel and principled framework to represent and model logical rules and triplets. RulE jointly represents entities, relations and logical rules in a unified embedding space. By learning an embedding for each logical rule, RulE can perform logical rule inference in a soft way and give a confidence score to each grounded rule, similar to how KGE gives each triplet a confidence score. Compared to KGE alone, RulE allows injecting prior logical rule information into the embedding space, which improves the generalization of knowledge graph embedding. Besides, the learned confidence scores of rules improve the logical rule inference process by softly controlling the contribution of each rule, which alleviates the brittleness of logic. We evaluate our method with link prediction tasks. Experimental results on multiple benchmark KGs demonstrate the effectiveness of RulE.
SQA3D: Situated Question Answering in 3D Scenes
Oct 14, 2022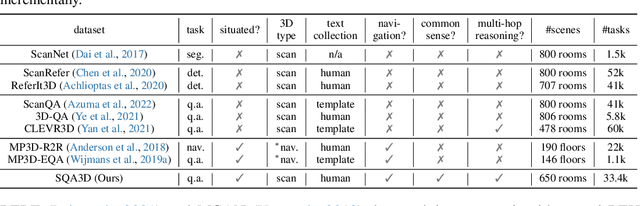
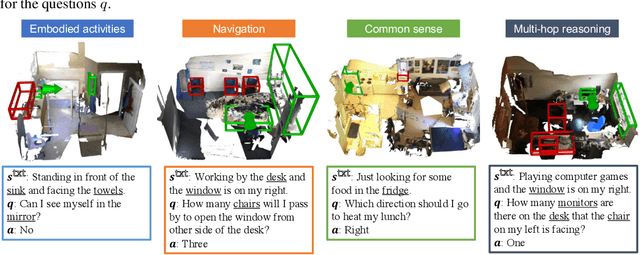

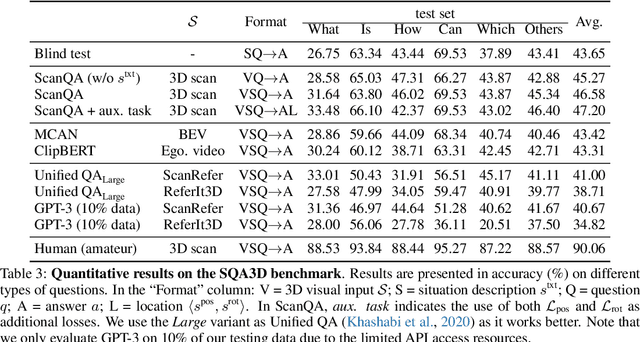
We propose a new task to benchmark scene understanding of embodied agents: Situated Question Answering in 3D Scenes (SQA3D). Given a scene context (e.g., 3D scan), SQA3D requires the tested agent to first understand its situation (position, orientation, etc.) in the 3D scene as described by text, then reason about its surrounding environment and answer a question under that situation. Based upon 650 scenes from ScanNet, we provide a dataset centered around 6.8k unique situations, along with 20.4k descriptions and 33.4k diverse reasoning questions for these situations. These questions examine a wide spectrum of reasoning capabilities for an intelligent agent, ranging from spatial relation comprehension to commonsense understanding, navigation, and multi-hop reasoning. SQA3D imposes a significant challenge to current multi-modal especially 3D reasoning models. We evaluate various state-of-the-art approaches and find that the best one only achieves an overall score of 47.20%, while amateur human participants can reach 90.06%. We believe SQA3D could facilitate future embodied AI research with stronger situation understanding and reasoning capability.
EgoTaskQA: Understanding Human Tasks in Egocentric Videos
Oct 08, 2022
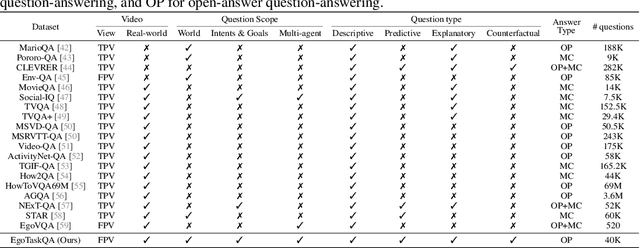
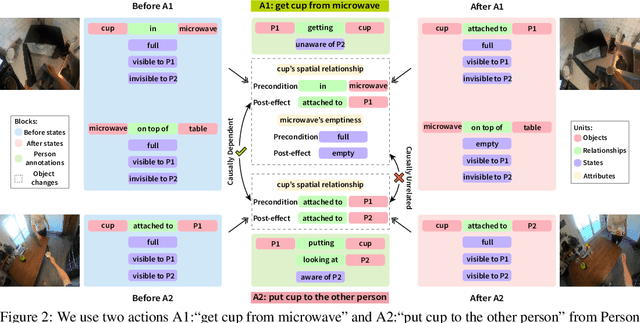
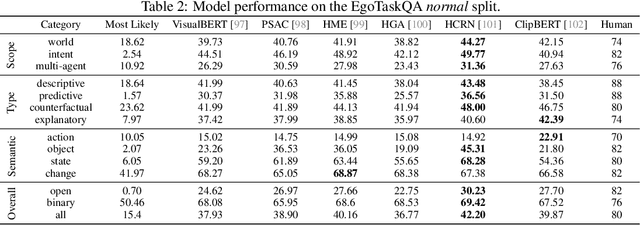
Understanding human tasks through video observations is an essential capability of intelligent agents. The challenges of such capability lie in the difficulty of generating a detailed understanding of situated actions, their effects on object states (i.e., state changes), and their causal dependencies. These challenges are further aggravated by the natural parallelism from multi-tasking and partial observations in multi-agent collaboration. Most prior works leverage action localization or future prediction as an indirect metric for evaluating such task understanding from videos. To make a direct evaluation, we introduce the EgoTaskQA benchmark that provides a single home for the crucial dimensions of task understanding through question-answering on real-world egocentric videos. We meticulously design questions that target the understanding of (1) action dependencies and effects, (2) intents and goals, and (3) agents' beliefs about others. These questions are divided into four types, including descriptive (what status?), predictive (what will?), explanatory (what caused?), and counterfactual (what if?) to provide diagnostic analyses on spatial, temporal, and causal understandings of goal-oriented tasks. We evaluate state-of-the-art video reasoning models on our benchmark and show their significant gaps between humans in understanding complex goal-oriented egocentric videos. We hope this effort will drive the vision community to move onward with goal-oriented video understanding and reasoning.
Neural-Symbolic Recursive Machine for Systematic Generalization
Oct 04, 2022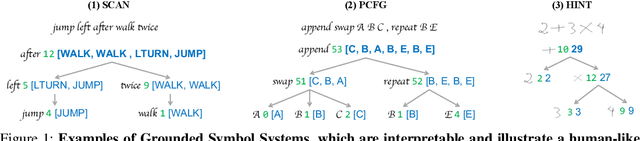
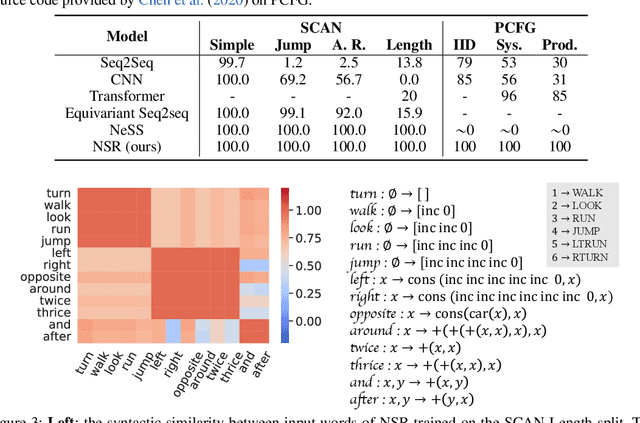
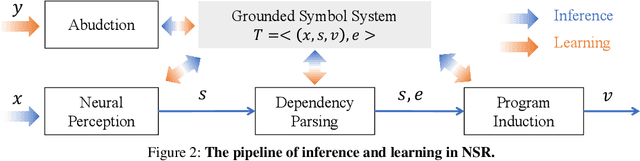
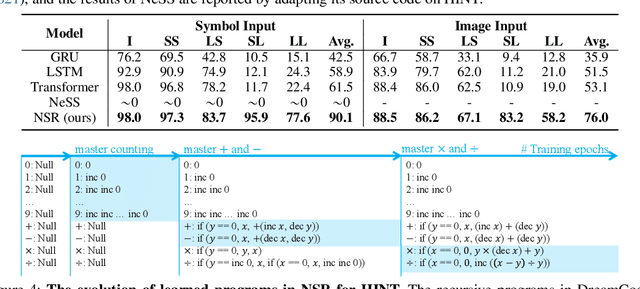
Despite the tremendous success, existing machine learning models still fall short of human-like systematic generalization -- learning compositional rules from limited data and applying them to unseen combinations in various domains. We propose Neural-Symbolic Recursive Machine (NSR) to tackle this deficiency. The core representation of NSR is a Grounded Symbol System (GSS) with combinatorial syntax and semantics, which entirely emerges from training data. Akin to the neuroscience studies suggesting separate brain systems for perceptual, syntactic, and semantic processing, NSR implements analogous separate modules of neural perception, syntactic parsing, and semantic reasoning, which are jointly learned by a deduction-abduction algorithm. We prove that NSR is expressive enough to model various sequence-to-sequence tasks. Superior systematic generalization is achieved via the inductive biases of equivariance and recursiveness embedded in NSR. In experiments, NSR achieves state-of-the-art performance in three benchmarks from different domains: SCAN for semantic parsing, PCFG for string manipulation, and HINT for arithmetic reasoning. Specifically, NSR achieves 100% generalization accuracy on SCAN and PCFG and outperforms state-of-the-art models on HINT by about 23%. Our NSR demonstrates stronger generalization than pure neural networks due to its symbolic representation and inductive biases. NSR also demonstrates better transferability than existing neural-symbolic approaches due to less domain-specific knowledge required.
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
Sep 29, 2022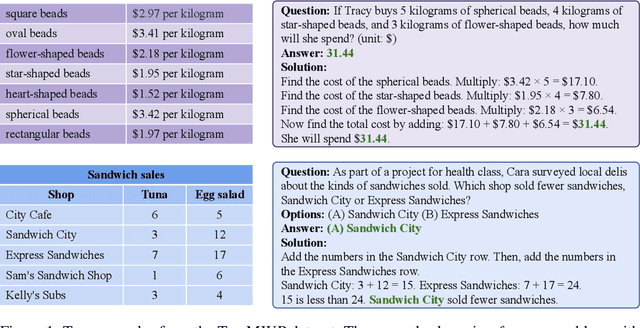
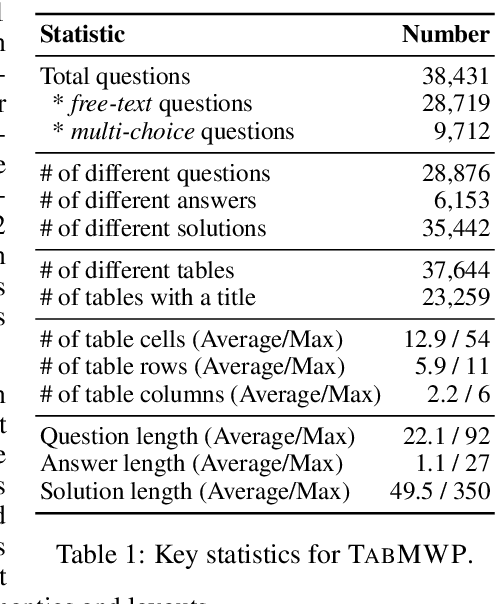
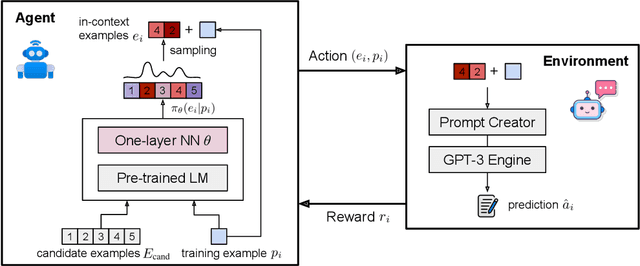
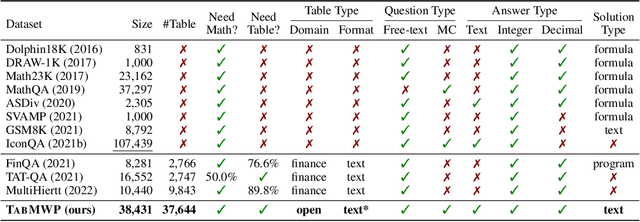
Mathematical reasoning, a core ability of human intelligence, presents unique challenges for machines in abstract thinking and logical reasoning. Recent large pre-trained language models such as GPT-3 have achieved remarkable progress on mathematical reasoning tasks written in text form, such as math word problems (MWP). However, it is unknown if the models can handle more complex problems that involve math reasoning over heterogeneous information, such as tabular data. To fill the gap, we present Tabular Math Word Problems (TabMWP), a new dataset containing 38,431 open-domain grade-level problems that require mathematical reasoning on both textual and tabular data. Each question in TabMWP is aligned with a tabular context, which is presented as an image, semi-structured text, and a structured table. There are two types of questions: free-text and multi-choice, and each problem is annotated with gold solutions to reveal the multi-step reasoning process. We evaluate different pre-trained models on TabMWP, including the GPT-3 model in a few-shot setting. As earlier studies suggest, since few-shot GPT-3 relies on the selection of in-context examples, its performance is unstable and can degrade to near chance. The unstable issue is more severe when handling complex problems like TabMWP. To mitigate this, we further propose a novel approach, PromptPG, which utilizes policy gradient to learn to select in-context examples from a small amount of training data and then constructs the corresponding prompt for the test example. Experimental results show that our method outperforms the best baseline by 5.31% on the accuracy metric and reduces the prediction variance significantly compared to random selection, which verifies its effectiveness in the selection of in-context examples.
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
Sep 20, 2022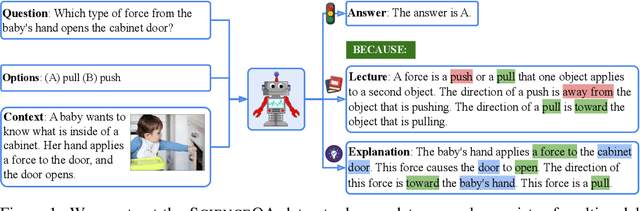
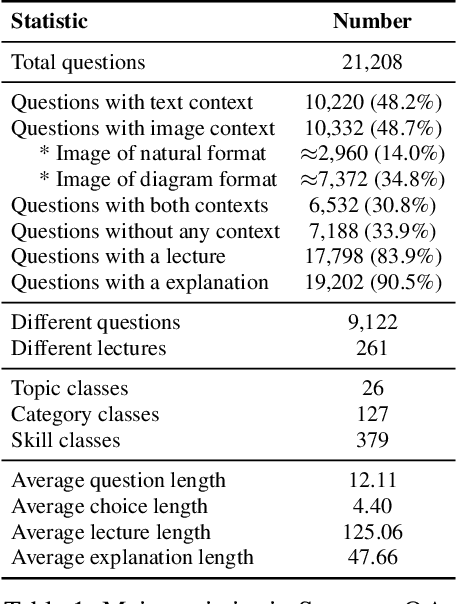
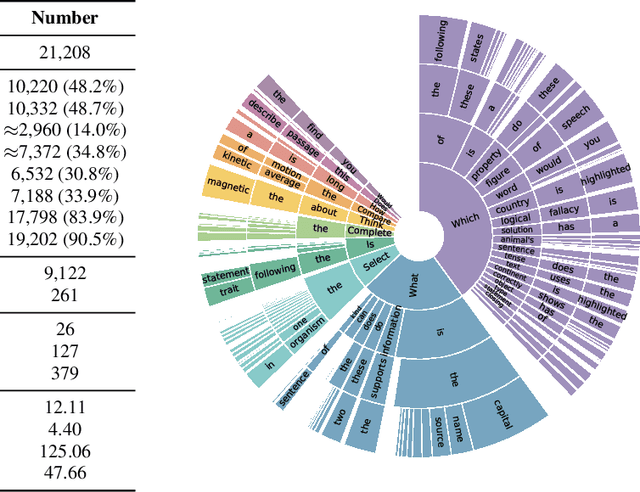
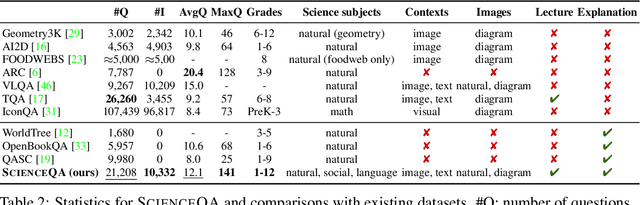
When answering a question, humans utilize the information available across different modalities to synthesize a consistent and complete chain of thought (CoT). This process is normally a black box in the case of deep learning models like large-scale language models. Recently, science question benchmarks have been used to diagnose the multi-hop reasoning ability and interpretability of an AI system. However, existing datasets fail to provide annotations for the answers, or are restricted to the textual-only modality, small scales, and limited domain diversity. To this end, we present Science Question Answering (SQA), a new benchmark that consists of ~21k multimodal multiple choice questions with a diverse set of science topics and annotations of their answers with corresponding lectures and explanations. We further design language models to learn to generate lectures and explanations as the chain of thought (CoT) to mimic the multi-hop reasoning process when answering SQA questions. SQA demonstrates the utility of CoT in language models, as CoT improves the question answering performance by 1.20% in few-shot GPT-3 and 3.99% in fine-tuned UnifiedQA. We also explore the upper bound for models to leverage explanations by feeding those in the input; we observe that it improves the few-shot performance of GPT-3 by 18.96%. Our analysis further shows that language models, similar to humans, benefit from explanations to learn from fewer data and achieve the same performance with just 40% of the data.