 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisiFold: Long-Term Traffic Forecasting via Temporal Folding Graph and Node Visibility
Mar 12, 2026Traffic forecasting is a cornerstone of intelligent transportation systems. While existing research has made significant progress in short-term prediction, long-term forecasting remains a largely uncharted and challenging frontier. Extending the prediction horizon intensifies two critical issues: escalating computational resource consumption and increasingly complex spatial-temporal dependencies. Current approaches, which rely on spatial-temporal graphs and process temporal and spatial dimensions separately, suffer from snapshot-stacking inflation and cross-step fragmentation. To overcome these limitations, we propose \textit{VisiFold}. Our framework introduces a novel temporal folding graph that consolidates a sequence of temporal snapshots into a single graph. Furthermore, we present a node visibility mechanism that incorporates node-level masking and subgraph sampling to overcome the computational bottleneck imposed by large node counts. Extensive experiments show that VisiFold not only drastically reduces resource consumption but also outperforms existing baselines in long-term forecasting tasks. Remarkably, even with a high mask ratio of 80\%, VisiFold maintains its performance advantage. By effectively breaking the resource constraints in both temporal and spatial dimensions, our work paves the way for more realistic long-term traffic forecasting. The code is available at~ https://github.com/PlanckChang/VisiFold.
EMAformer: Enhancing Transformer through Embedding Armor for Time Series Forecasting
Nov 11, 2025Multivariate time series forecasting is crucial across a wide range of domains. While presenting notable progress for the Transformer architecture, iTransformer still lags behind the latest MLP-based models. We attribute this performance gap to unstable inter-channel relationships. To bridge this gap, we propose EMAformer, a simple yet effective model that enhances the Transformer with an auxiliary embedding suite, akin to armor that reinforces its ability. By introducing three key inductive biases, i.e., \textit{global stability}, \textit{phase sensitivity}, and \textit{cross-axis specificity}, EMAformer unlocks the further potential of the Transformer architecture, achieving state-of-the-art performance on 12 real-world benchmarks and reducing forecasting errors by an average of 2.73\% in MSE and 5.15\% in MAE. This significantly advances the practical applicability of Transformer-based approaches for multivariate time series forecasting. The code is available on https://github.com/PlanckChang/EMAformer.
SToLa: Self-Adaptive Touch-Language Framework with Tactile Commonsense Reasoning in Open-Ended Scenarios
May 07, 2025This paper explores the challenges of integrating tactile sensing into intelligent systems for multimodal reasoning, particularly in enabling commonsense reasoning about the open-ended physical world. We identify two key challenges: modality discrepancy, where existing large touch-language models often treat touch as a mere sub-modality of language, and open-ended tactile data scarcity, where current datasets lack the diversity, open-endness and complexity needed for reasoning. To overcome these challenges, we introduce SToLa, a Self-Adaptive Touch-Language framework. SToLa utilizes Mixture of Experts (MoE) to dynamically process, unify, and manage tactile and language modalities, capturing their unique characteristics. Crucially, we also present a comprehensive tactile commonsense reasoning dataset and benchmark featuring free-form questions and responses, 8 physical properties, 4 interactive characteristics, and diverse commonsense knowledge. Experiments show SToLa exhibits competitive performance compared to existing models on the PhysiCLeAR benchmark and self-constructed datasets, proving the effectiveness of the Mixture of Experts architecture in multimodal management and the performance advantages for open-scenario tactile commonsense reasoning tasks.
Extralonger: Toward a Unified Perspective of Spatial-Temporal Factors for Extra-Long-Term Traffic Forecasting
Oct 30, 2024Traffic forecasting plays a key role in Intelligent Transportation Systems, and significant strides have been made in this field. However, most existing methods can only predict up to four hours in the future, which doesn't quite meet real-world demands. we identify that the prediction horizon is limited to a few hours mainly due to the separation of temporal and spatial factors, which results in high complexity. Drawing inspiration from Albert Einstein's relativity theory, which suggests space and time are unified and inseparable, we introduce Extralonger, which unifies temporal and spatial factors. Extralonger notably extends the prediction horizon to a week on real-world benchmarks, demonstrating superior efficiency in the training time, inference time, and memory usage. It sets new standards in long-term and extra-long-term scenarios. The code is available at https://github.com/PlanckChang/Extralonger.
Touch100k: A Large-Scale Touch-Language-Vision Dataset for Touch-Centric Multimodal Representation
Jun 06, 2024



Touch holds a pivotal position in enhancing the perceptual and interactive capabilities of both humans and robots. Despite its significance, current tactile research mainly focuses on visual and tactile modalities, overlooking the language domain. Inspired by this, we construct Touch100k, a paired touch-language-vision dataset at the scale of 100k, featuring tactile sensation descriptions in multiple granularities (i.e., sentence-level natural expressions with rich semantics, including contextual and dynamic relationships, and phrase-level descriptions capturing the key features of tactile sensations). Based on the dataset, we propose a pre-training method, Touch-Language-Vision Representation Learning through Curriculum Linking (TLV-Link, for short), inspired by the concept of curriculum learning. TLV-Link aims to learn a tactile representation for the GelSight sensor and capture the relationship between tactile, language, and visual modalities. We evaluate our representation's performance across two task categories (namely, material property identification and robot grasping prediction), focusing on tactile representation and zero-shot touch understanding. The experimental evaluation showcases the effectiveness of our representation. By enabling TLV-Link to achieve substantial improvements and establish a new state-of-the-art in touch-centric multimodal representation learning, Touch100k demonstrates its value as a valuable resource for research. Project page: https://cocacola-lab.github.io/Touch100k/.
Transformer in Touch: A Survey
May 21, 2024The Transformer model, initially achieving significant success in the field of natural language processing, has recently shown great potential in the application of tactile perception. This review aims to comprehensively outline the application and development of Transformers in tactile technology. We first introduce the two fundamental concepts behind the success of the Transformer: the self-attention mechanism and large-scale pre-training. Then, we delve into the application of Transformers in various tactile tasks, including but not limited to object recognition, cross-modal generation, and object manipulation, offering a concise summary of the core methodologies, performance benchmarks, and design highlights. Finally, we suggest potential areas for further research and future work, aiming to generate more interest within the community, tackle existing challenges, and encourage the use of Transformer models in the tactile field.
Potential and Limitations of LLMs in Capturing Structured Semantics: A Case Study on SRL
May 10, 2024

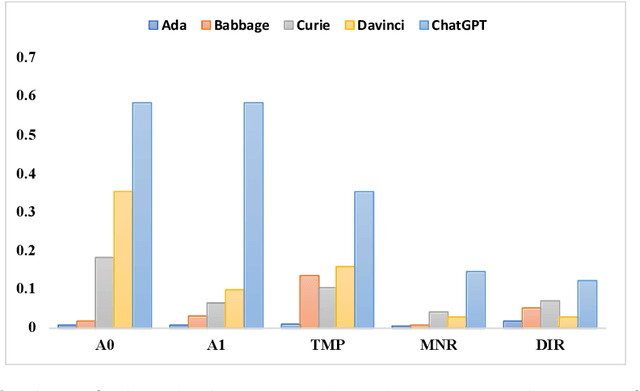

Large Language Models (LLMs) play a crucial role in capturing structured semantics to enhance language understanding, improve interpretability, and reduce bias. Nevertheless, an ongoing controversy exists over the extent to which LLMs can grasp structured semantics. To assess this, we propose using Semantic Role Labeling (SRL) as a fundamental task to explore LLMs' ability to extract structured semantics. In our assessment, we employ the prompting approach, which leads to the creation of our few-shot SRL parser, called PromptSRL. PromptSRL enables LLMs to map natural languages to explicit semantic structures, which provides an interpretable window into the properties of LLMs. We find interesting potential: LLMs can indeed capture semantic structures, and scaling-up doesn't always mirror potential. Additionally, limitations of LLMs are observed in C-arguments, etc. Lastly, we are surprised to discover that significant overlap in the errors is made by both LLMs and untrained humans, accounting for almost 30% of all errors.
MineLand: Simulating Large-Scale Multi-Agent Interactions with Limited Multimodal Senses and Physical Needs
Mar 28, 2024



Conventional multi-agent simulators often assume perfect information and limitless capabilities, hindering the ecological validity of social interactions. We propose a multi-agent Minecraft simulator, MineLand, that bridges this gap by introducing limited multimodal senses and physical needs. Our simulator supports up to 48 agents with limited visual, auditory, and environmental awareness, forcing them to actively communicate and collaborate to fulfill physical needs like food and resources. This fosters dynamic and valid multi-agent interactions. We further introduce an AI agent framework, Alex, inspired by multitasking theory, enabling agents to handle intricate coordination and scheduling. Our experiments demonstrate that the simulator, the corresponding benchmark, and the AI agent framework contribute to more ecological and nuanced collective behavior. The source code of MineLand and Alex is openly available at https://github.com/cocacola-lab/MineLand.
Towards Comprehensive Multimodal Perception: Introducing the Touch-Language-Vision Dataset
Mar 14, 2024



Tactility provides crucial support and enhancement for the perception and interaction capabilities of both humans and robots. Nevertheless, the multimodal research related to touch primarily focuses on visual and tactile modalities, with limited exploration in the domain of language. Beyond vocabulary, sentence-level descriptions contain richer semantics. Based on this, we construct a touch-language-vision dataset named TLV (Touch-Language-Vision) by human-machine cascade collaboration, featuring sentence-level descriptions for multimode alignment. The new dataset is used to fine-tune our proposed lightweight training framework, TLV-Link (Linking Touch, Language, and Vision through Alignment), achieving effective semantic alignment with minimal parameter adjustments (1%). Project Page: https://xiaoen0.github.io/touch.page/.
TransGPT: Multi-modal Generative Pre-trained Transformer for Transportation
Feb 11, 2024



Natural language processing (NLP) is a key component of intelligent transportation systems (ITS), but it faces many challenges in the transportation domain, such as domain-specific knowledge and data, and multi-modal inputs and outputs. This paper presents TransGPT, a novel (multi-modal) large language model for the transportation domain, which consists of two independent variants: TransGPT-SM for single-modal data and TransGPT-MM for multi-modal data. TransGPT-SM is finetuned on a single-modal Transportation dataset (STD) that contains textual data from various sources in the transportation domain. TransGPT-MM is finetuned on a multi-modal Transportation dataset (MTD) that we manually collected from three areas of the transportation domain: driving tests, traffic signs, and landmarks. We evaluate TransGPT on several benchmark datasets for different tasks in the transportation domain, and show that it outperforms baseline models on most tasks. We also showcase the potential applications of TransGPT for traffic analysis and modeling, such as generating synthetic traffic scenarios, explaining traffic phenomena, answering traffic-related questions, providing traffic recommendations, and generating traffic reports. This work advances the state-of-the-art of NLP in the transportation domain and provides a useful tool for ITS researchers and practitioners.