 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXingGAN for Person Image Generation
Jul 17, 2020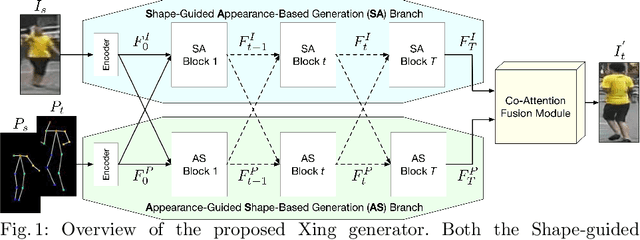
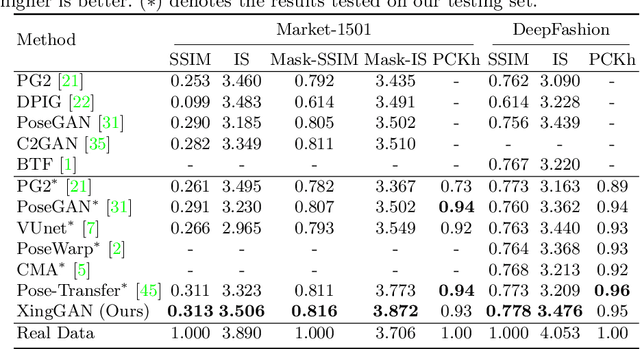
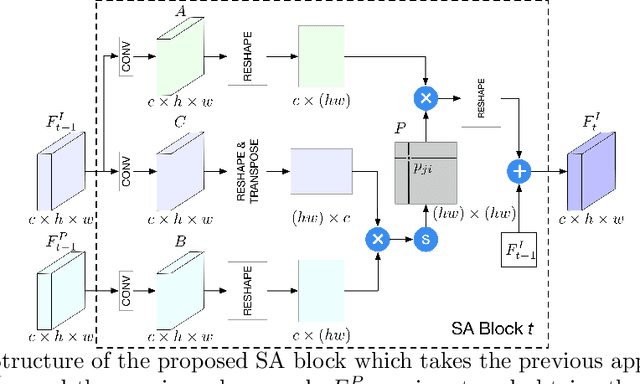
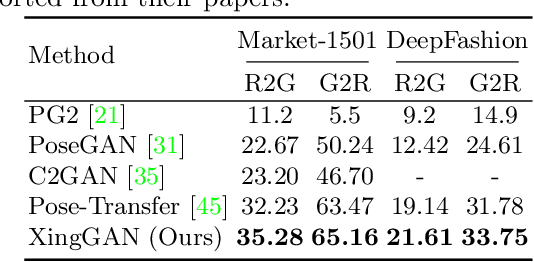
We propose a novel Generative Adversarial Network (XingGAN or CrossingGAN) for person image generation tasks, i.e., translating the pose of a given person to a desired one. The proposed Xing generator consists of two generation branches that model the person's appearance and shape information, respectively. Moreover, we propose two novel blocks to effectively transfer and update the person's shape and appearance embeddings in a crossing way to mutually improve each other, which has not been considered by any other existing GAN-based image generation work. Extensive experiments on two challenging datasets, i.e., Market-1501 and DeepFashion, demonstrate that the proposed XingGAN advances the state-of-the-art performance both in terms of objective quantitative scores and subjective visual realness. The source code and trained models are available at https://github.com/Ha0Tang/XingGAN.
Neural Architecture Search for Lightweight Non-Local Networks
Apr 04, 2020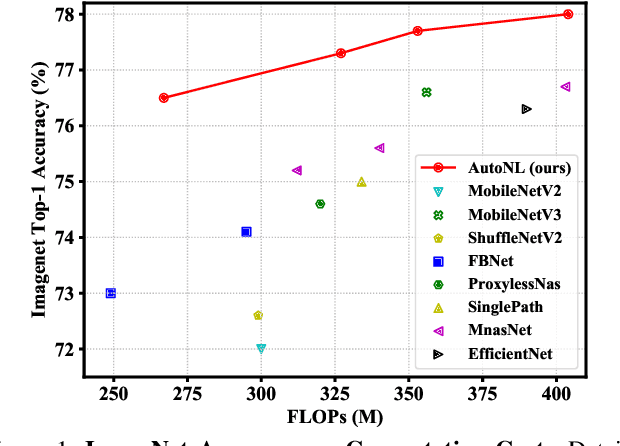

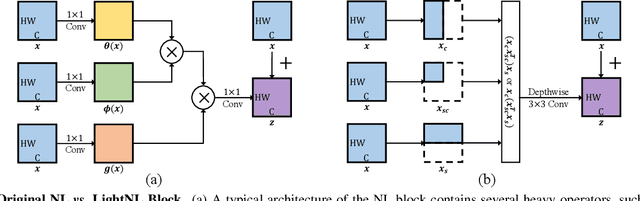

Non-Local (NL) blocks have been widely studied in various vision tasks. However, it has been rarely explored to embed the NL blocks in mobile neural networks, mainly due to the following challenges: 1) NL blocks generally have heavy computation cost which makes it difficult to be applied in applications where computational resources are limited, and 2) it is an open problem to discover an optimal configuration to embed NL blocks into mobile neural networks. We propose AutoNL to overcome the above two obstacles. Firstly, we propose a Lightweight Non-Local (LightNL) block by squeezing the transformation operations and incorporating compact features. With the novel design choices, the proposed LightNL block is 400x computationally cheaper} than its conventional counterpart without sacrificing the performance. Secondly, by relaxing the structure of the LightNL block to be differentiable during training, we propose an efficient neural architecture search algorithm to learn an optimal configuration of LightNL blocks in an end-to-end manner. Notably, using only 32 GPU hours, the searched AutoNL model achieves 77.7% top-1 accuracy on ImageNet under a typical mobile setting (350M FLOPs), significantly outperforming previous mobile models including MobileNetV2 (+5.7%), FBNet (+2.8%) and MnasNet (+2.1%). Code and models are available at https://github.com/LiYingwei/AutoNL.
Holistically-Attracted Wireframe Parsing
Mar 03, 2020
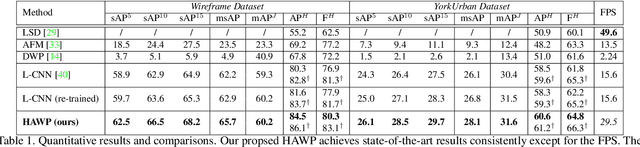
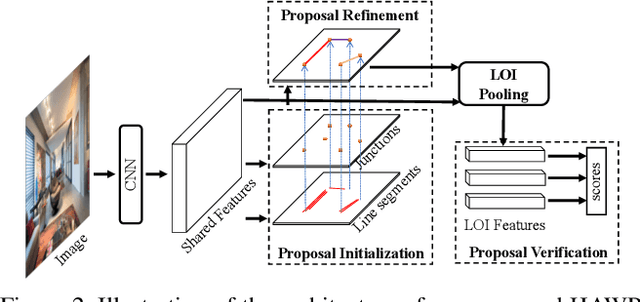
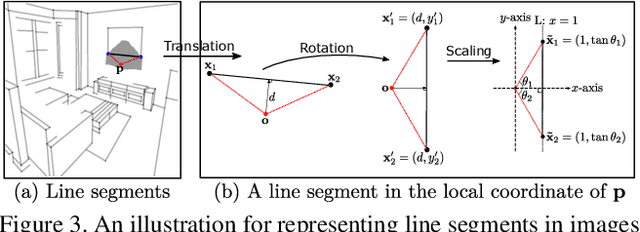
This paper presents a fast and parsimonious parsing method to accurately and robustly detect a vectorized wireframe in an input image with a single forward pass. The proposed method is end-to-end trainable, consisting of three components: (i) line segment and junction proposal generation, (ii) line segment and junction matching, and (iii) line segment and junction verification. For computing line segment proposals, a novel exact dual representation is proposed which exploits a parsimonious geometric reparameterization for line segments and forms a holistic 4-dimensional attraction field map for an input image. Junctions can be treated as the "basins" in the attraction field. The proposed method is thus called Holistically-Attracted Wireframe Parser (HAWP). In experiments, the proposed method is tested on two benchmarks, the Wireframe dataset, and the YorkUrban dataset. On both benchmarks, it obtains state-of-the-art performance in terms of accuracy and efficiency. For example, on the Wireframe dataset, compared to the previous state-of-the-art method L-CNN, it improves the challenging mean structural average precision (msAP) by a large margin ($2.8\%$ absolute improvements) and achieves 29.5 FPS on single GPU ($89\%$ relative improvement). A systematic ablation study is performed to further justify the proposed method.
AutoScale: Learning to Scale for Crowd Counting
Dec 20, 2019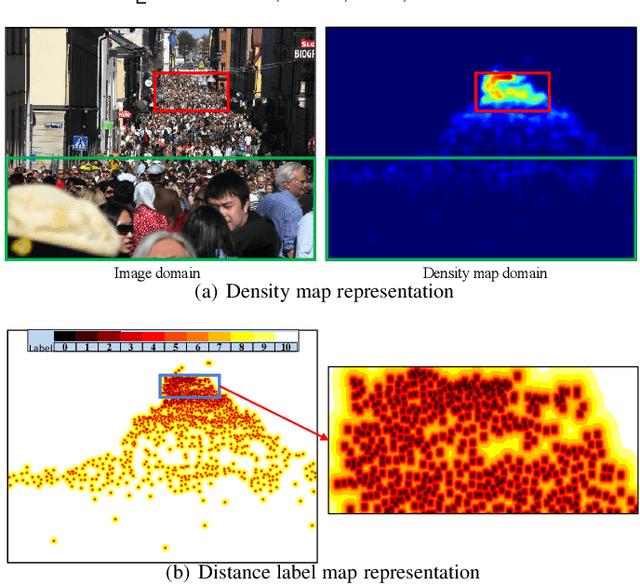


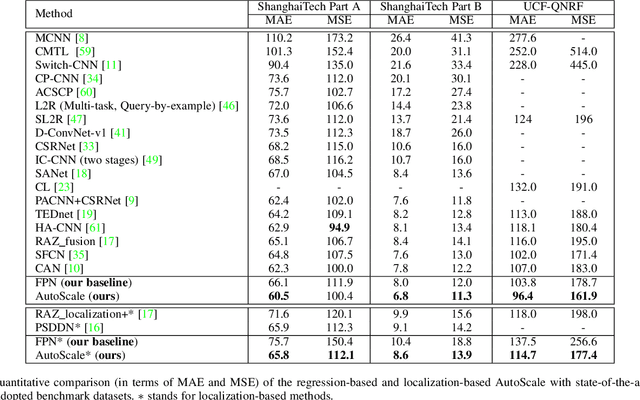
Crowd counting in images is a widely explored but challenging task. Though recent convolutional neural network (CNN) methods have achieved great progress, it is still difficult to accurately count and even to precisely localize people in very dense regions. A major issue is that dense regions usually consist of many instances of small size, and thus exhibit very different density patterns compared with sparse regions. Localizing or detecting dense small objects is also very delicate. In this paper, instead of processing image pyramid and aggregating multi-scale features, we propose a simple yet effective Learning to Scale (L2S) module to cope with significant scale variations in both regression and localization. Specifically, L2S module aims to automatically scale dense regions into similar and reasonable scale levels. This alleviates the density pattern shift for density regression methods and facilitates the localization of small instances. Besides, we also introduce a novel distance label map combined with a customized adapted cross-entropy loss for precise person localization. Extensive experiments demonstrate that the proposed method termed AutoScale consistently improves upon state-of-the-art methods in both regression and localization benchmarks on three widely used datasets. The proposed AutoScale also demonstrates a noteworthy transferability under cross-dataset validation on different datasets.
Learning Regional Attraction for Line Segment Detection
Dec 18, 2019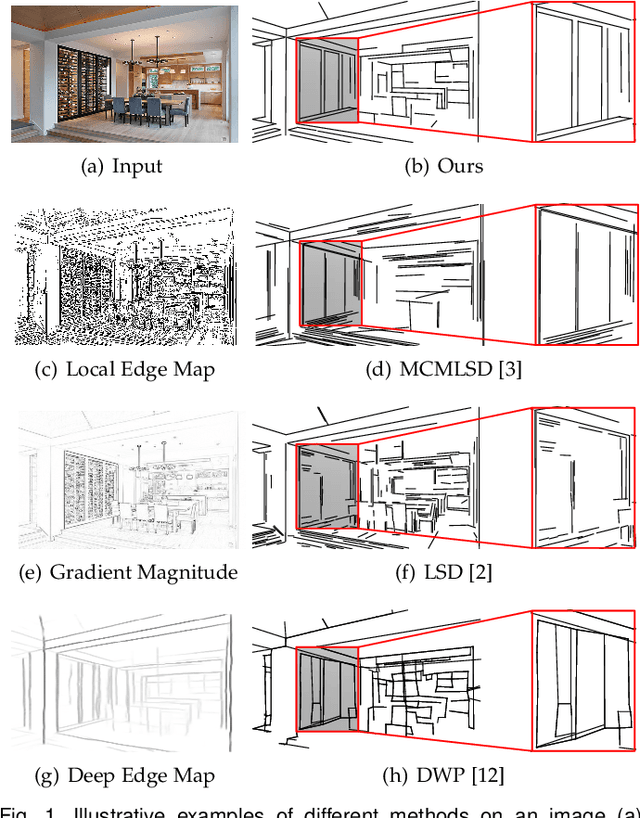
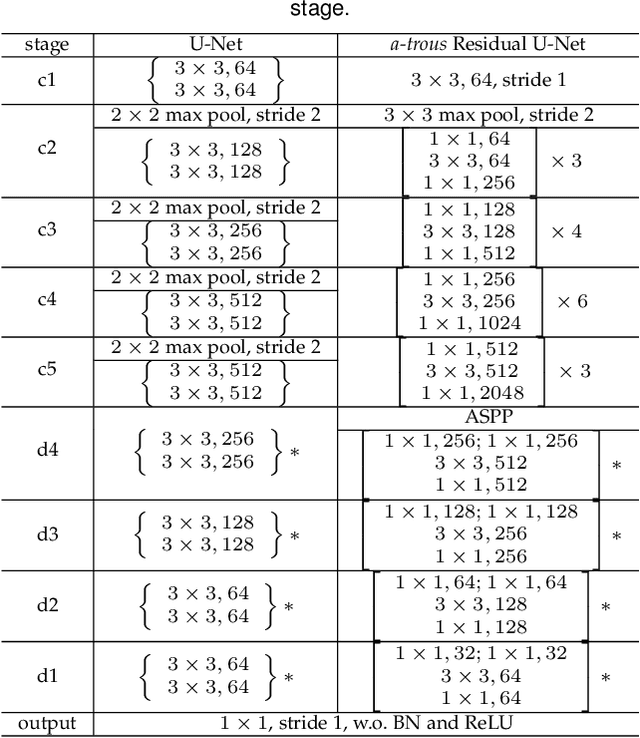
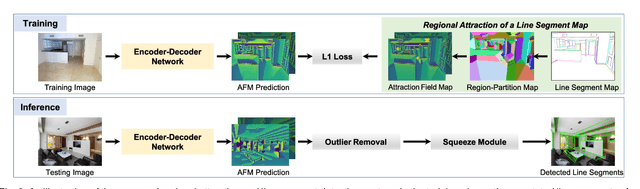
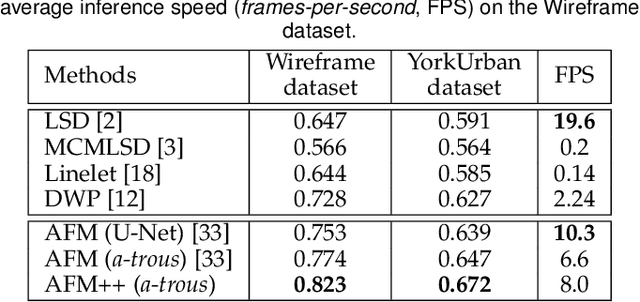
This paper presents regional attraction of line segment maps, and hereby poses the problem of line segment detection (LSD) as a problem of region coloring. Given a line segment map, the proposed regional attraction first establishes the relationship between line segments and regions in the image lattice. Based on this, the line segment map is equivalently transformed to an attraction field map (AFM), which can be remapped to a set of line segments without loss of information. Accordingly, we develop an end-to-end framework to learn attraction field maps for raw input images, followed by a squeeze module to detect line segments. Apart from existing works, the proposed detector properly handles the local ambiguity and does not rely on the accurate identification of edge pixels. Comprehensive experiments on the Wireframe dataset and the YorkUrban dataset demonstrate the superiority of our method. In particular, we achieve an F-measure of 0.831 on the Wireframe dataset, advancing the state-of-the-art performance by 10.3 percent.
Anchor Diffusion for Unsupervised Video Object Segmentation
Oct 24, 2019
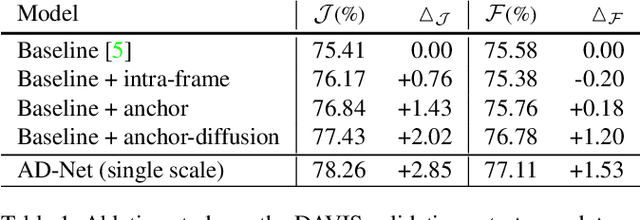
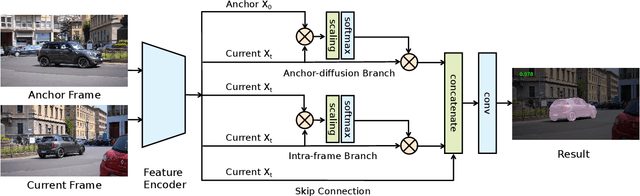
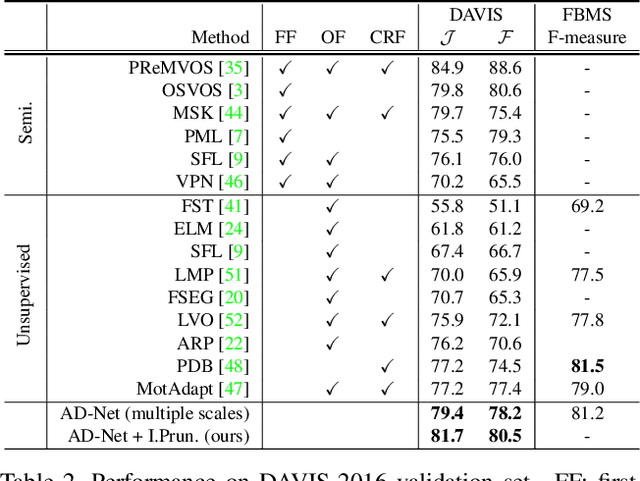
Unsupervised video object segmentation has often been tackled by methods based on recurrent neural networks and optical flow. Despite their complexity, these kinds of approaches tend to favour short-term temporal dependencies and are thus prone to accumulating inaccuracies, which cause drift over time. Moreover, simple (static) image segmentation models, alone, can perform competitively against these methods, which further suggests that the way temporal dependencies are modelled should be reconsidered. Motivated by these observations, in this paper we explore simple yet effective strategies to model long-term temporal dependencies. Inspired by the non-local operators of [70], we introduce a technique to establish dense correspondences between pixel embeddings of a reference "anchor" frame and the current one. This allows the learning of pairwise dependencies at arbitrarily long distances without conditioning on intermediate frames. Without online supervision, our approach can suppress the background and precisely segment the foreground object even in challenging scenarios, while maintaining consistent performance over time. With a mean IoU of $81.7\%$, our method ranks first on the DAVIS-2016 leaderboard of unsupervised methods, while still being competitive against state-of-the-art online semi-supervised approaches. We further evaluate our method on the FBMS dataset and the ViSal video saliency dataset, showing results competitive with the state of the art.
Asymmetric Non-local Neural Networks for Semantic Segmentation
Aug 29, 2019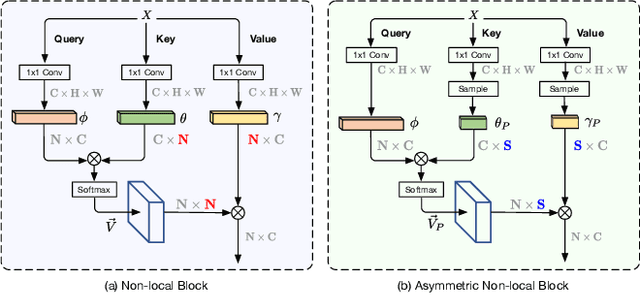
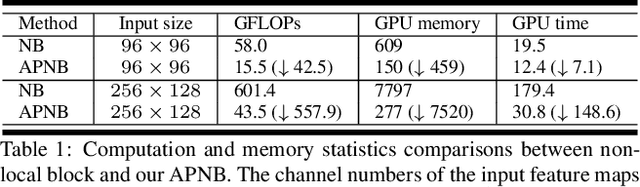
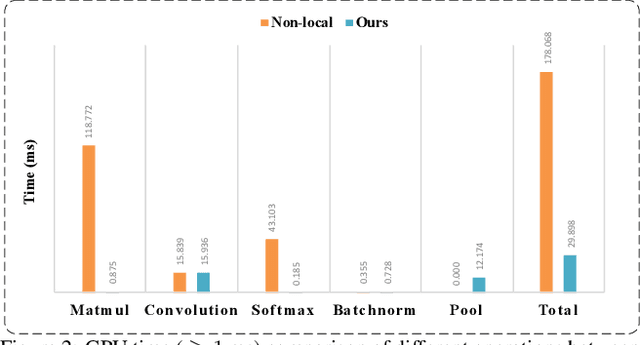
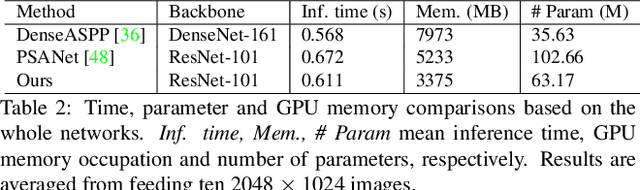
The non-local module works as a particularly useful technique for semantic segmentation while criticized for its prohibitive computation and GPU memory occupation. In this paper, we present Asymmetric Non-local Neural Network to semantic segmentation, which has two prominent components: Asymmetric Pyramid Non-local Block (APNB) and Asymmetric Fusion Non-local Block (AFNB). APNB leverages a pyramid sampling module into the non-local block to largely reduce the computation and memory consumption without sacrificing the performance. AFNB is adapted from APNB to fuse the features of different levels under a sufficient consideration of long range dependencies and thus considerably improves the performance. Extensive experiments on semantic segmentation benchmarks demonstrate the effectiveness and efficiency of our work. In particular, we report the state-of-the-art performance of 81.3 mIoU on the Cityscapes test set. For a 256x128 input, APNB is around 6 times faster than a non-local block on GPU while 28 times smaller in GPU running memory occupation. Code is available at: https://github.com/MendelXu/ANN.git.
View N-gram Network for 3D Object Retrieval
Aug 15, 2019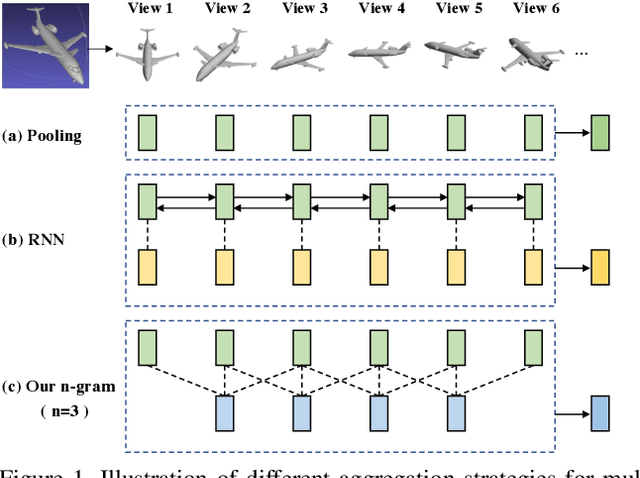
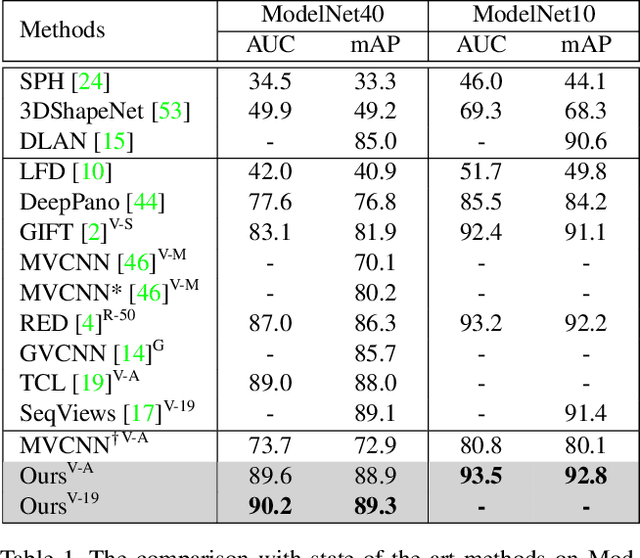
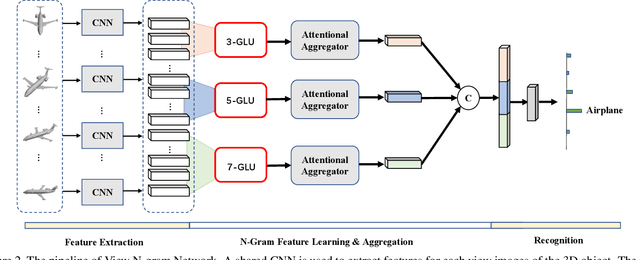
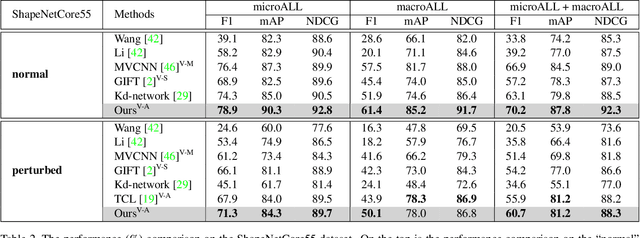
How to aggregate multi-view representations of a 3D object into an informative and discriminative one remains a key challenge for multi-view 3D object retrieval. Existing methods either use view-wise pooling strategies which neglect the spatial information across different views or employ recurrent neural networks which may face the efficiency problem. To address these issues, we propose an effective and efficient framework called View N-gram Network (VNN). Inspired by n-gram models in natural language processing, VNN divides the view sequence into a set of visual n-grams, which involve overlapping consecutive view sub-sequences. By doing so, spatial information across multiple views is captured, which helps to learn a discriminative global embedding for each 3D object. Experiments on 3D shape retrieval benchmarks, including ModelNet10, ModelNet40 and ShapeNetCore55 datasets, demonstrate the superiority of our proposed method.
Learn to Scale: Generating Multipolar Normalized Density Maps for Crowd Counting
Aug 08, 2019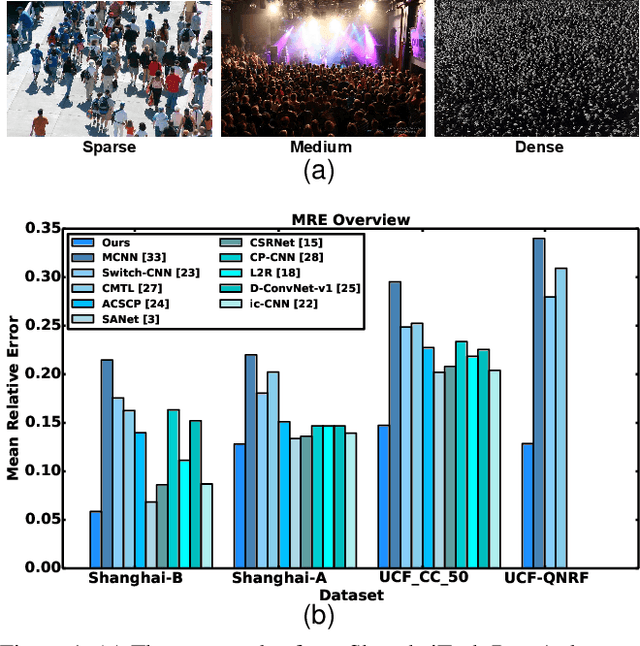
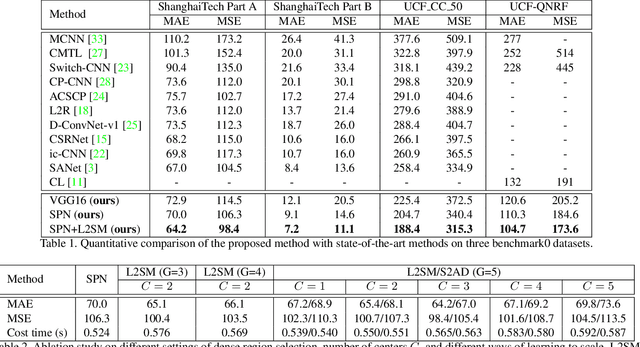

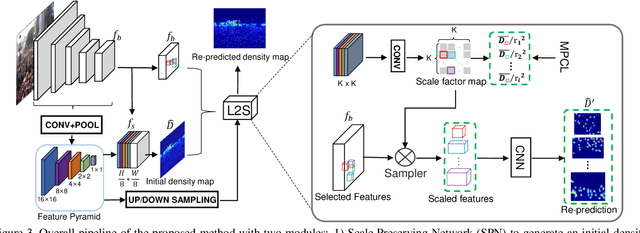
Dense crowd counting aims to predict thousands of human instances from an image, by calculating integrals of a density map over image pixels. Existing approaches mainly suffer from the extreme density variances. Such density pattern shift poses challenges even for multi-scale model ensembling. In this paper, we propose a simple yet effective approach to tackle this problem. First, a patch-level density map is extracted by a density estimation model and further grouped into several density levels which are determined over full datasets. Second, each patch density map is automatically normalized by an online center learning strategy with a multipolar center loss. Such a design can significantly condense the density distribution into several clusters, and enable that the density variance can be learned by a single model. Extensive experiments demonstrate the superiority of the proposed method. Our work outperforms the state-of-the-art by 4.2%, 14.3%, 27.1% and 20.1% in MAE, on ShanghaiTech Part A, ShanghaiTech Part B, UCF_CC_50 and UCF-QNRF datasets, respectively.
Symmetry-constrained Rectification Network for Scene Text Recognition
Aug 06, 2019
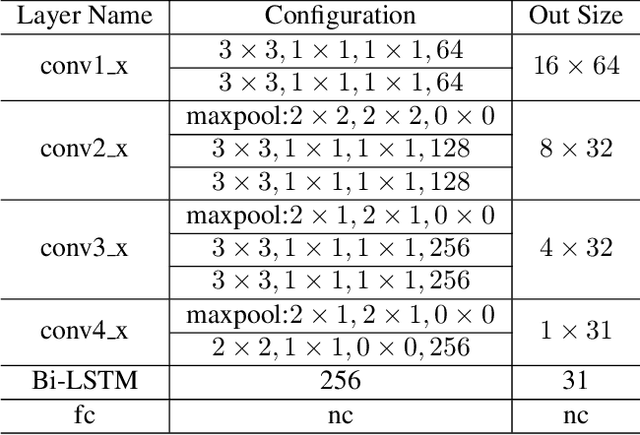

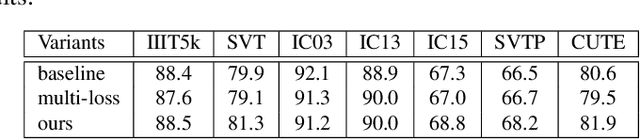
Reading text in the wild is a very challenging task due to the diversity of text instances and the complexity of natural scenes. Recently, the community has paid increasing attention to the problem of recognizing text instances with irregular shapes. One intuitive and effective way to handle this problem is to rectify irregular text to a canonical form before recognition. However, these methods might struggle when dealing with highly curved or distorted text instances. To tackle this issue, we propose in this paper a Symmetry-constrained Rectification Network (ScRN) based on local attributes of text instances, such as center line, scale and orientation. Such constraints with an accurate description of text shape enable ScRN to generate better rectification results than existing methods and thus lead to higher recognition accuracy. Our method achieves state-of-the-art performance on text with both regular and irregular shapes. Specifically, the system outperforms existing algorithms by a large margin on datasets that contain quite a proportion of irregular text instances, e.g., ICDAR 2015, SVT-Perspective and CUTE80.