 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERITAS: Verifier-Guided Proof Search for Zero-Shot Formal Theorem Proving
Jun 17, 2026LLM-based formal provers often collapse rich verifier signals (syntax errors, type mismatches, partial goal progress) into a binary pass/fail bit. We present VERITAS, a zero-shot framework that routes every verifier signal back into proof search through a two-phase protocol: Best-of-N sampling first, then a critic-guided MCTS pass that ingests Phase 1 failures as explicit negative examples. The protocol preserves every theorem solved by its own Phase 1 sweep, so Phase 2's additional solves are attributable to feedback-driven exploration. VERITAS reaches 40.6% on miniF2F (vs. an independently run Best-of-5 at 36.9%, Portfolio 26.2%) and 7.3% on VERITAS-CombiBench, a 55-theorem combinatorics benchmark we release on which Best-of-5 (1.8%) falls below Portfolio (3.6%), exposing that unguided sampling hurts when correct lemma names must be recovered iteratively from verifier feedback. Artifacts are available on GitHub.
Debiasing Random Oblique Projections for Subsampled OLS and Fast CUR in High Dimensions
May 24, 2026Random sampling is a fundamental tool in modern machine learning and numerical linear algebra for reducing the computational cost of large-scale matrix problems. Existing analyses, however, rely primarily on subspace embedding guarantees, which do not precisely characterize the statistical bias of nonlinear random oblique projections induced by sampling, which arises ubiquitously in subsampled least squares and fast low-rank approximation methods. Because (pseudo)inversion is nonlinear, these random oblique projections can be systematically biased even when the underlying sketch is unbiased, thereby introducing hidden bias into downstream least squares and low-rank approximation solutions. In this work, we develop a unified non-asymptotic theory for random oblique projections in high dimensions. We show that standard random sampling schemes generally induce a systematic statistical bias overlooked by classical subspace embedding-style analyses, and we propose a principled debiasing framework to correct it. We illustrate the power of the theory through two canonical applications. For subsampled least squares, we obtain sharp bias--variance characterizations, reveal previously unrecognized statistical suboptimality in widely used sampling schemes, and identify when debiasing yields provable improvements. For fast CUR decomposition, we develop a debiased approach with improved approximation accuracy. Numerical experiments further validate our theoretical findings.
Frequency Matching in Spiking Neural Networks for mmWave Sensing
May 11, 2026Millimeter-wave (mmWave) sensing enables privacy-preserving, always-on edge perception, but its measurements are often sparse, temporally irregular, and corrupted by high-frequency noise. Existing mmWave pipelines predominantly rely on artificial neural networks (ANNs), which achieve robustness through extensive preprocessing or deep architectures, thereby limiting their efficiency on edge devices. In this work, we study spiking neural networks (SNNs) for mmWave sensing from a mechanism-data alignment perspective. By leveraging the low-pass filtering behavior of leaky integrate-and-fire (LIF) dynamics, we analyze how their implicit temporal filtering interacts with the frequency structure of mmWave signals. Our analysis shows that when discriminative information resides in low-to-mid frequencies, LIF dynamics can inherently suppress high-frequency noise, clarifying when and why SNNs outperform ANNs. Based on this insight, we derive a principled criterion for configuring the membrane decay factor by matching the effective bandwidth of LIF dynamics to the data's discriminative spectral content. Experimental results across four widely used mmWave datasets validate the proposed frequency-matching hypothesis, yielding an average test-accuracy improvement of 6.22% and a 3.64$\times$ reduction in theoretical energy consumption relative to ANN baselines, under a unified evaluation protocol.
Intent-aligned Formal Specification Synthesis via Traceable Refinement
Apr 12, 2026Large language models are increasingly used to generate code from natural language, but ensuring correctness remains challenging. Formal verification offers a principled way to obtain such guarantees by proving that a program satisfies a formal specification. However, specifications are frequently missing in real-world codebases, and writing high-quality specifications remains expensive and expertise-intensive. We present VeriSpecGen, a traceable refinement framework that synthesizes intent-aligned specifications in Lean through requirement-level attribution and localized repair. VeriSpecGen decomposes natural language into atomic requirements and generates requirement-targeted tests with explicit traceability maps to validate generated specifications. When validation fails, traceability maps attribute failures to specific requirements, enabling targeted clause-level repairs. VeriSpecGen achieve 86.6% on VERINA SpecGen task using Claude Opus 4.5, improving over baselines by up to 31.8 points across different model families and scales. Beyond inference-time gains, we generate 343K training examples from VeriSpecGen refinement trajectories and demonstrate that training on these trajectories substantially improves specification synthesis by 62-106% relative and transfers gains to general reasoning abilities.
Characterization of Gaussian Universality Breakdown in High-Dimensional Empirical Risk Minimization
Apr 03, 2026We study high-dimensional convex empirical risk minimization (ERM) under general non-Gaussian data designs. By heuristically extending the Convex Gaussian Min-Max Theorem (CGMT) to non-Gaussian settings, we derive an asymptotic min-max characterization of key statistics, enabling approximation of the mean $μ_{\hatθ}$ and covariance $C_{\hatθ}$ of the ERM estimator $\hatθ$. Specifically, under a concentration assumption on the data matrix and standard regularity conditions on the loss and regularizer, we show that for a test covariate $x$ independent of the training data, the projection $\hatθ^\top x$ approximately follows the convolution of the (generally non-Gaussian) distribution of $μ_{\hatθ}^\top x$ with an independent centered Gaussian variable of variance $\text{Tr}(C_{\hatθ}\mathbb{E}[xx^\top])$. This result clarifies the scope and limits of Gaussian universality for ERMs. Additionally, we prove that any $\mathcal{C}^2$ regularizer is asymptotically equivalent to a quadratic form determined solely by its Hessian at zero and gradient at $μ_{\hatθ}$. Numerical simulations across diverse losses and models are provided to validate our theoretical predictions and qualitative insights.
Diving into Kronecker Adapters: Component Design Matters
Feb 01, 2026Kronecker adapters have emerged as a promising approach for fine-tuning large-scale models, enabling high-rank updates through tunable component structures. However, existing work largely treats the component structure as a fixed or heuristic design choice, leaving the dimensions and number of Kronecker components underexplored. In this paper, we identify component structure as a key factor governing the capacity of Kronecker adapters. We perform a fine-grained analysis of both the dimensions and number of Kronecker components. In particular, we show that the alignment between Kronecker adapters and full fine-tuning depends on component configurations. Guided by these insights, we propose Component Designed Kronecker Adapters (CDKA). We further provide parameter-budget-aware configuration guidelines and a tailored training stabilization strategy for practical deployment. Experiments across various natural language processing tasks demonstrate the effectiveness of CDKA. Code is available at https://github.com/rainstonee/CDKA.
What Happens Next? Next Scene Prediction with a Unified Video Model
Dec 15, 2025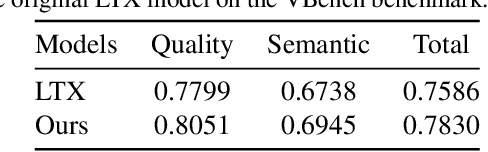
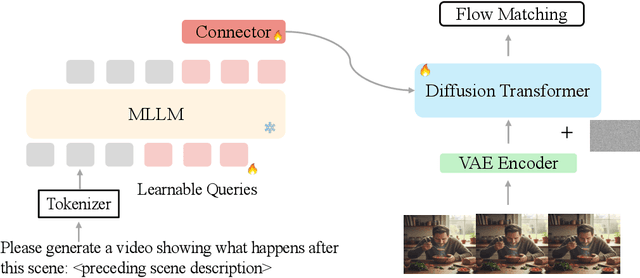
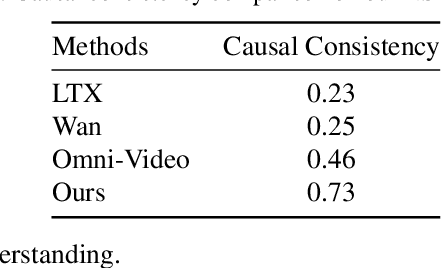
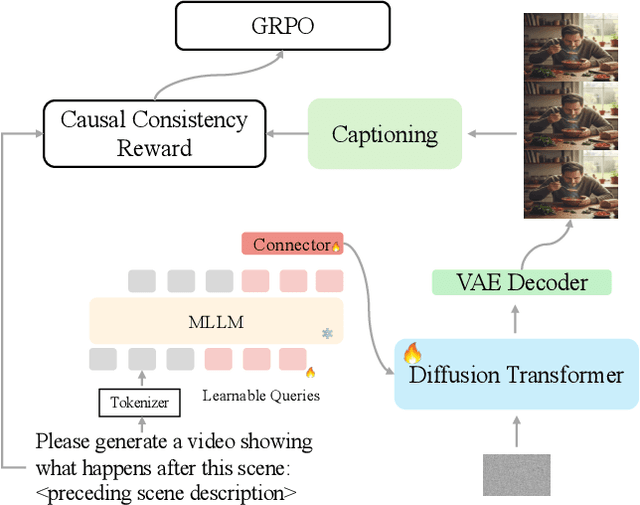
Recent unified models for joint understanding and generation have significantly advanced visual generation capabilities. However, their focus on conventional tasks like text-to-video generation has left the temporal reasoning potential of unified models largely underexplored. To address this gap, we introduce Next Scene Prediction (NSP), a new task that pushes unified video models toward temporal and causal reasoning. Unlike text-to-video generation, NSP requires predicting plausible futures from preceding context, demanding deeper understanding and reasoning. To tackle this task, we propose a unified framework combining Qwen-VL for comprehension and LTX for synthesis, bridged by a latent query embedding and a connector module. This model is trained in three stages on our newly curated, large-scale NSP dataset: text-to-video pre-training, supervised fine-tuning, and reinforcement learning (via GRPO) with our proposed causal consistency reward. Experiments demonstrate our model achieves state-of-the-art performance on our benchmark, advancing the capability of generalist multimodal systems to anticipate what happens next.
VIDEOP2R: Video Understanding from Perception to Reasoning
Nov 14, 2025Reinforcement fine-tuning (RFT), a two-stage framework consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) has shown promising results on improving reasoning ability of large language models (LLMs). Yet extending RFT to large video language models (LVLMs) remains challenging. We propose VideoP2R, a novel process-aware video RFT framework that enhances video reasoning by modeling perception and reasoning as distinct processes. In the SFT stage, we develop a three-step pipeline to generate VideoP2R-CoT-162K, a high-quality, process-aware chain-of-thought (CoT) dataset for perception and reasoning. In the RL stage, we introduce a novel process-aware group relative policy optimization (PA-GRPO) algorithm that supplies separate rewards for perception and reasoning. Extensive experiments show that VideoP2R achieves state-of-the-art (SotA) performance on six out of seven video reasoning and understanding benchmarks. Ablation studies further confirm the effectiveness of our process-aware modeling and PA-GRPO and demonstrate that model's perception output is information-sufficient for downstream reasoning.
A Random Matrix Perspective of Echo State Networks: From Precise Bias--Variance Characterization to Optimal Regularization
Sep 26, 2025We present a rigorous asymptotic analysis of Echo State Networks (ESNs) in a teacher student setting with a linear teacher with oracle weights. Leveraging random matrix theory, we derive closed form expressions for the asymptotic bias, variance, and mean-squared error (MSE) as functions of the input statistics, the oracle vector, and the ridge regularization parameter. The analysis reveals two key departures from classical ridge regression: (i) ESNs do not exhibit double descent, and (ii) ESNs attain lower MSE when both the number of training samples and the teacher memory length are limited. We further provide an explicit formula for the optimal regularization in the identity input covariance case, and propose an efficient numerical scheme to compute the optimum in the general case. Together, these results offer interpretable theory and practical guidelines for tuning ESNs, helping reconcile recent empirical observations with provable performance guarantees
Random Matrix Theory for Deep Learning: Beyond Eigenvalues of Linear Models
Jun 16, 2025Modern Machine Learning (ML) and Deep Neural Networks (DNNs) often operate on high-dimensional data and rely on overparameterized models, where classical low-dimensional intuitions break down. In particular, the proportional regime where the data dimension, sample size, and number of model parameters are all large and comparable, gives rise to novel and sometimes counterintuitive behaviors. This paper extends traditional Random Matrix Theory (RMT) beyond eigenvalue-based analysis of linear models to address the challenges posed by nonlinear ML models such as DNNs in this regime. We introduce the concept of High-dimensional Equivalent, which unifies and generalizes both Deterministic Equivalent and Linear Equivalent, to systematically address three technical challenges: high dimensionality, nonlinearity, and the need to analyze generic eigenspectral functionals. Leveraging this framework, we provide precise characterizations of the training and generalization performance of linear models, nonlinear shallow networks, and deep networks. Our results capture rich phenomena, including scaling laws, double descent, and nonlinear learning dynamics, offering a unified perspective on the theoretical understanding of deep learning in high dimensions.