 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
One2Any: One-Reference 6D Pose Estimation for Any Object
May 07, 20256D object pose estimation remains challenging for many applications due to dependencies on complete 3D models, multi-view images, or training limited to specific object categories. These requirements make generalization to novel objects difficult for which neither 3D models nor multi-view images may be available. To address this, we propose a novel method One2Any that estimates the relative 6-degrees of freedom (DOF) object pose using only a single reference-single query RGB-D image, without prior knowledge of its 3D model, multi-view data, or category constraints. We treat object pose estimation as an encoding-decoding process, first, we obtain a comprehensive Reference Object Pose Embedding (ROPE) that encodes an object shape, orientation, and texture from a single reference view. Using this embedding, a U-Net-based pose decoding module produces Reference Object Coordinate (ROC) for new views, enabling fast and accurate pose estimation. This simple encoding-decoding framework allows our model to be trained on any pair-wise pose data, enabling large-scale training and demonstrating great scalability. Experiments on multiple benchmark datasets demonstrate that our model generalizes well to novel objects, achieving state-of-the-art accuracy and robustness even rivaling methods that require multi-view or CAD inputs, at a fraction of compute.
* accepted by CVPR 2025
Video-Bench: Human-Aligned Video Generation Benchmark
Apr 07, 2025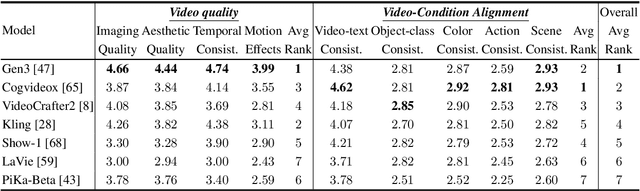
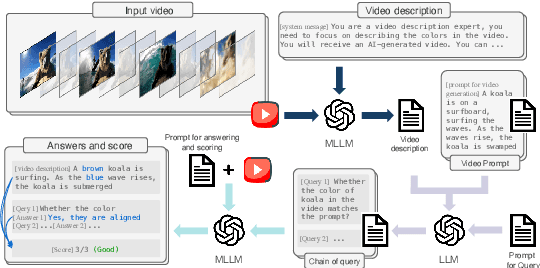
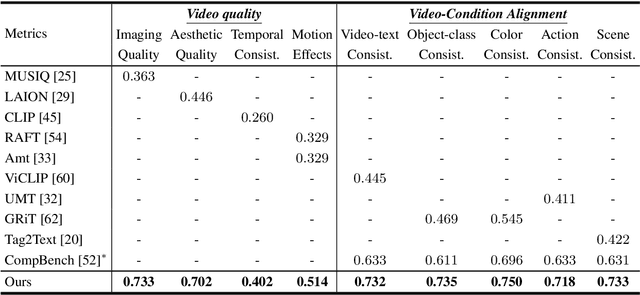
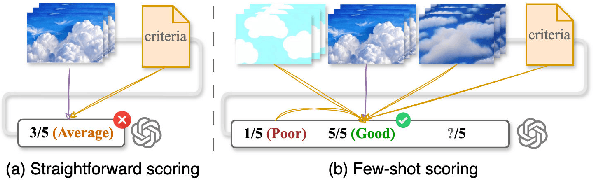
Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework's assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.
Hybrid Global-Local Representation with Augmented Spatial Guidance for Zero-Shot Referring Image Segmentation
Apr 01, 2025



Recent advances in zero-shot referring image segmentation (RIS), driven by models such as the Segment Anything Model (SAM) and CLIP, have made substantial progress in aligning visual and textual information. Despite these successes, the extraction of precise and high-quality mask region representations remains a critical challenge, limiting the full potential of RIS tasks. In this paper, we introduce a training-free, hybrid global-local feature extraction approach that integrates detailed mask-specific features with contextual information from the surrounding area, enhancing mask region representation. To further strengthen alignment between mask regions and referring expressions, we propose a spatial guidance augmentation strategy that improves spatial coherence, which is essential for accurately localizing described areas. By incorporating multiple spatial cues, this approach facilitates more robust and precise referring segmentation. Extensive experiments on standard RIS benchmarks demonstrate that our method significantly outperforms existing zero-shot RIS models, achieving substantial performance gains. We believe our approach advances RIS tasks and establishes a versatile framework for region-text alignment, offering broader implications for cross-modal understanding and interaction. Code is available at https://github.com/fhgyuanshen/HybridGL .
MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization
Apr 01, 2025Masked Image Modeling (MIM) with Vector Quantization (VQ) has achieved great success in both self-supervised pre-training and image generation. However, most existing methods struggle to address the trade-off in shared latent space for generation quality vs. representation learning and efficiency. To push the limits of this paradigm, we propose MergeVQ, which incorporates token merging techniques into VQ-based generative models to bridge the gap between image generation and visual representation learning in a unified architecture. During pre-training, MergeVQ decouples top-k semantics from latent space with the token merge module after self-attention blocks in the encoder for subsequent Look-up Free Quantization (LFQ) and global alignment and recovers their fine-grained details through cross-attention in the decoder for reconstruction. As for the second-stage generation, we introduce MergeAR, which performs KV Cache compression for efficient raster-order prediction. Extensive experiments on ImageNet verify that MergeVQ as an AR generative model achieves competitive performance in both visual representation learning and image generation tasks while maintaining favorable token efficiency and inference speed. The code and model will be available at https://apexgen-x.github.io/MergeVQ.
UniK3D: Universal Camera Monocular 3D Estimation
Mar 20, 2025



Monocular 3D estimation is crucial for visual perception. However, current methods fall short by relying on oversimplified assumptions, such as pinhole camera models or rectified images. These limitations severely restrict their general applicability, causing poor performance in real-world scenarios with fisheye or panoramic images and resulting in substantial context loss. To address this, we present UniK3D, the first generalizable method for monocular 3D estimation able to model any camera. Our method introduces a spherical 3D representation which allows for better disentanglement of camera and scene geometry and enables accurate metric 3D reconstruction for unconstrained camera models. Our camera component features a novel, model-independent representation of the pencil of rays, achieved through a learned superposition of spherical harmonics. We also introduce an angular loss, which, together with the camera module design, prevents the contraction of the 3D outputs for wide-view cameras. A comprehensive zero-shot evaluation on 13 diverse datasets demonstrates the state-of-the-art performance of UniK3D across 3D, depth, and camera metrics, with substantial gains in challenging large-field-of-view and panoramic settings, while maintaining top accuracy in conventional pinhole small-field-of-view domains. Code and models are available at github.com/lpiccinelli-eth/unik3d .
Prior-guided Hierarchical Harmonization Network for Efficient Image Dehazing
Mar 03, 2025Image dehazing is a crucial task that involves the enhancement of degraded images to recover their sharpness and textures. While vision Transformers have exhibited impressive results in diverse dehazing tasks, their quadratic complexity and lack of dehazing priors pose significant drawbacks for real-world applications. In this paper, guided by triple priors, Bright Channel Prior (BCP), Dark Channel Prior (DCP), and Histogram Equalization (HE), we propose a \textit{P}rior-\textit{g}uided Hierarchical \textit{H}armonization Network (PGH$^2$Net) for image dehazing. PGH$^2$Net is built upon the UNet-like architecture with an efficient encoder and decoder, consisting of two module types: (1) Prior aggregation module that injects B/DCP and selects diverse contexts with gating attention. (2) Feature harmonization modules that subtract low-frequency components from spatial and channel aspects and learn more informative feature distributions to equalize the feature maps.
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Feb 27, 2025



Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepthV2, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE paradigm, UniDepthV2 directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepthV2 implements a self-promptable camera module predicting a dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles the camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. UniDepthV2 improves its predecessor UniDepth model via a new edge-guided loss which enhances the localization and sharpness of edges in the metric depth outputs, a revisited, simplified and more efficient architectural design, and an additional uncertainty-level output which enables downstream tasks requiring confidence. Thorough evaluations on ten depth datasets in a zero-shot regime consistently demonstrate the superior performance and generalization of UniDepthV2. Code and models are available at https://github.com/lpiccinelli-eth/UniDepth
Dual-branch Graph Feature Learning for NLOS Imaging
Feb 27, 2025The domain of non-line-of-sight (NLOS) imaging is advancing rapidly, offering the capability to reveal occluded scenes that are not directly visible. However, contemporary NLOS systems face several significant challenges: (1) The computational and storage requirements are profound due to the inherent three-dimensional grid data structure, which restricts practical application. (2) The simultaneous reconstruction of albedo and depth information requires a delicate balance using hyperparameters in the loss function, rendering the concurrent reconstruction of texture and depth information difficult. This paper introduces the innovative methodology, \xnet, which integrates an albedo-focused reconstruction branch dedicated to albedo information recovery and a depth-focused reconstruction branch that extracts geometrical structure, to overcome these obstacles. The dual-branch framework segregates content delivery to the respective reconstructions, thereby enhancing the quality of the retrieved data. To our knowledge, we are the first to employ the GNN as a fundamental component to transform dense NLOS grid data into sparse structural features for efficient reconstruction. Comprehensive experiments demonstrate that our method attains the highest level of performance among existing methods across synthetic and real data. https://github.com/Nicholassu/DG-NLOS.
Life-Code: Central Dogma Modeling with Multi-Omics Sequence Unification
Feb 11, 2025



The interactions between DNA, RNA, and proteins are fundamental to biological processes, as illustrated by the central dogma of molecular biology. While modern biological pre-trained models have achieved great success in analyzing these macromolecules individually, their interconnected nature remains under-explored. In this paper, we follow the guidance of the central dogma to redesign both the data and model pipeline and offer a comprehensive framework, Life-Code, that spans different biological functions. As for data flow, we propose a unified pipeline to integrate multi-omics data by reverse-transcribing RNA and reverse-translating amino acids into nucleotide-based sequences. As for the model, we design a codon tokenizer and a hybrid long-sequence architecture to encode the interactions of both coding and non-coding regions with masked modeling pre-training. To model the translation and folding process with coding sequences, Life-Code learns protein structures of the corresponding amino acids by knowledge distillation from off-the-shelf protein language models. Such designs enable Life-Code to capture complex interactions within genetic sequences, providing a more comprehensive understanding of multi-omics with the central dogma. Extensive Experiments show that Life-Code achieves state-of-the-art performance on various tasks across three omics, highlighting its potential for advancing multi-omics analysis and interpretation.