 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Aug 07, 2025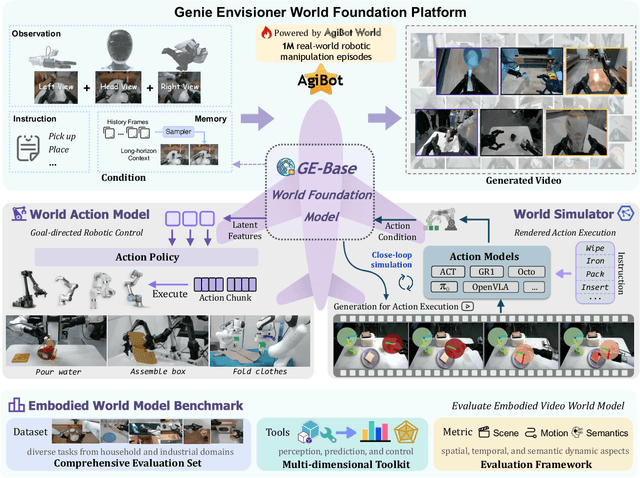
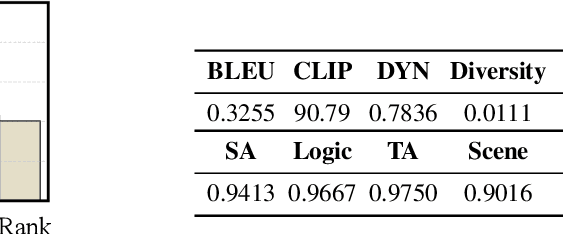

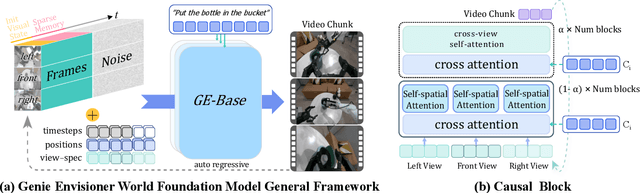
We introduce Genie Envisioner (GE), a unified world foundation platform for robotic manipulation that integrates policy learning, evaluation, and simulation within a single video-generative framework. At its core, GE-Base is a large-scale, instruction-conditioned video diffusion model that captures the spatial, temporal, and semantic dynamics of real-world robotic interactions in a structured latent space. Built upon this foundation, GE-Act maps latent representations to executable action trajectories through a lightweight, flow-matching decoder, enabling precise and generalizable policy inference across diverse embodiments with minimal supervision. To support scalable evaluation and training, GE-Sim serves as an action-conditioned neural simulator, producing high-fidelity rollouts for closed-loop policy development. The platform is further equipped with EWMBench, a standardized benchmark suite measuring visual fidelity, physical consistency, and instruction-action alignment. Together, these components establish Genie Envisioner as a scalable and practical foundation for instruction-driven, general-purpose embodied intelligence. All code, models, and benchmarks will be released publicly.
DOMR: Establishing Cross-View Segmentation via Dense Object Matching
Aug 06, 2025Cross-view object correspondence involves matching objects between egocentric (first-person) and exocentric (third-person) views. It is a critical yet challenging task for visual understanding. In this work, we propose the Dense Object Matching and Refinement (DOMR) framework to establish dense object correspondences across views. The framework centers around the Dense Object Matcher (DOM) module, which jointly models multiple objects. Unlike methods that directly match individual object masks to image features, DOM leverages both positional and semantic relationships among objects to find correspondences. DOM integrates a proposal generation module with a dense matching module that jointly encodes visual, spatial, and semantic cues, explicitly constructing inter-object relationships to achieve dense matching among objects. Furthermore, we combine DOM with a mask refinement head designed to improve the completeness and accuracy of the predicted masks, forming the complete DOMR framework. Extensive evaluations on the Ego-Exo4D benchmark demonstrate that our approach achieves state-of-the-art performance with a mean IoU of 49.7% on Ego$\to$Exo and 55.2% on Exo$\to$Ego. These results outperform those of previous methods by 5.8% and 4.3%, respectively, validating the effectiveness of our integrated approach for cross-view understanding.
CoST: Efficient Collaborative Perception From Unified Spatiotemporal Perspective
Aug 01, 2025Collaborative perception shares information among different agents and helps solving problems that individual agents may face, e.g., occlusions and small sensing range. Prior methods usually separate the multi-agent fusion and multi-time fusion into two consecutive steps. In contrast, this paper proposes an efficient collaborative perception that aggregates the observations from different agents (space) and different times into a unified spatio-temporal space simultanesouly. The unified spatio-temporal space brings two benefits, i.e., efficient feature transmission and superior feature fusion. 1) Efficient feature transmission: each static object yields a single observation in the spatial temporal space, and thus only requires transmission only once (whereas prior methods re-transmit all the object features multiple times). 2) superior feature fusion: merging the multi-agent and multi-time fusion into a unified spatial-temporal aggregation enables a more holistic perspective, thereby enhancing perception performance in challenging scenarios. Consequently, our Collaborative perception with Spatio-temporal Transformer (CoST) gains improvement in both efficiency and accuracy. Notably, CoST is not tied to any specific method and is compatible with a majority of previous methods, enhancing their accuracy while reducing the transmission bandwidth.
OctoNav: Towards Generalist Embodied Navigation
Jun 11, 2025Embodied navigation stands as a foundation pillar within the broader pursuit of embodied AI. However, previous navigation research is divided into different tasks/capabilities, e.g., ObjNav, ImgNav and VLN, where they differ in task objectives and modalities, making datasets and methods are designed individually. In this work, we take steps toward generalist navigation agents, which can follow free-form instructions that include arbitrary compounds of multi-modal and multi-capability. To achieve this, we propose a large-scale benchmark and corresponding method, termed OctoNav-Bench and OctoNav-R1. Specifically, OctoNav-Bench features continuous environments and is constructed via a designed annotation pipeline. We thoroughly craft instruction-trajectory pairs, where instructions are diverse in free-form with arbitrary modality and capability. Also, we construct a Think-Before-Action (TBA-CoT) dataset within OctoNav-Bench to provide the thinking process behind actions. For OctoNav-R1, we build it upon MLLMs and adapt it to a VLA-type model, which can produce low-level actions solely based on 2D visual observations. Moreover, we design a Hybrid Training Paradigm (HTP) that consists of three stages, i.e., Action-/TBA-SFT, Nav-GPRO, and Online RL stages. Each stage contains specifically designed learning policies and rewards. Importantly, for TBA-SFT and Nav-GRPO designs, we are inspired by the OpenAI-o1 and DeepSeek-R1, which show impressive reasoning ability via thinking-before-answer. Thus, we aim to investigate how to achieve thinking-before-action in the embodied navigation field, to improve model's reasoning ability toward generalists. Specifically, we propose TBA-SFT to utilize the TBA-CoT dataset to fine-tune the model as a cold-start phrase and then leverage Nav-GPRO to improve its thinking ability. Finally, OctoNav-R1 shows superior performance compared with previous methods.
RoboCerebra: A Large-scale Benchmark for Long-horizon Robotic Manipulation Evaluation
Jun 07, 2025Recent advances in vision-language models (VLMs) have enabled instruction-conditioned robotic systems with improved generalization. However, most existing work focuses on reactive System 1 policies, underutilizing VLMs' strengths in semantic reasoning and long-horizon planning. These System 2 capabilities-characterized by deliberative, goal-directed thinking-remain under explored due to the limited temporal scale and structural complexity of current benchmarks. To address this gap, we introduce RoboCerebra, a benchmark for evaluating high-level reasoning in long-horizon robotic manipulation. RoboCerebra includes: (1) a large-scale simulation dataset with extended task horizons and diverse subtask sequences in household environments; (2) a hierarchical framework combining a high-level VLM planner with a low-level vision-language-action (VLA) controller; and (3) an evaluation protocol targeting planning, reflection, and memory through structured System 1-System 2 interaction. The dataset is constructed via a top-down pipeline, where GPT generates task instructions and decomposes them into subtask sequences. Human operators execute the subtasks in simulation, yielding high-quality trajectories with dynamic object variations. Compared to prior benchmarks, RoboCerebra features significantly longer action sequences and denser annotations. We further benchmark state-of-the-art VLMs as System 2 modules and analyze their performance across key cognitive dimensions, advancing the development of more capable and generalizable robotic planners.
UAV-Flow Colosseo: A Real-World Benchmark for Flying-on-a-Word UAV Imitation Learning
May 21, 2025Unmanned Aerial Vehicles (UAVs) are evolving into language-interactive platforms, enabling more intuitive forms of human-drone interaction. While prior works have primarily focused on high-level planning and long-horizon navigation, we shift attention to language-guided fine-grained trajectory control, where UAVs execute short-range, reactive flight behaviors in response to language instructions. We formalize this problem as the Flying-on-a-Word (Flow) task and introduce UAV imitation learning as an effective approach. In this framework, UAVs learn fine-grained control policies by mimicking expert pilot trajectories paired with atomic language instructions. To support this paradigm, we present UAV-Flow, the first real-world benchmark for language-conditioned, fine-grained UAV control. It includes a task formulation, a large-scale dataset collected in diverse environments, a deployable control framework, and a simulation suite for systematic evaluation. Our design enables UAVs to closely imitate the precise, expert-level flight trajectories of human pilots and supports direct deployment without sim-to-real gap. We conduct extensive experiments on UAV-Flow, benchmarking VLN and VLA paradigms. Results show that VLA models are superior to VLN baselines and highlight the critical role of spatial grounding in the fine-grained Flow setting.
ProFashion: Prototype-guided Fashion Video Generation with Multiple Reference Images
May 10, 2025



Fashion video generation aims to synthesize temporally consistent videos from reference images of a designated character. Despite significant progress, existing diffusion-based methods only support a single reference image as input, severely limiting their capability to generate view-consistent fashion videos, especially when there are different patterns on the clothes from different perspectives. Moreover, the widely adopted motion module does not sufficiently model human body movement, leading to sub-optimal spatiotemporal consistency. To address these issues, we propose ProFashion, a fashion video generation framework leveraging multiple reference images to achieve improved view consistency and temporal coherency. To effectively leverage features from multiple reference images while maintaining a reasonable computational cost, we devise a Pose-aware Prototype Aggregator, which selects and aggregates global and fine-grained reference features according to pose information to form frame-wise prototypes, which serve as guidance in the denoising process. To further enhance motion consistency, we introduce a Flow-enhanced Prototype Instantiator, which exploits the human keypoint motion flow to guide an extra spatiotemporal attention process in the denoiser. To demonstrate the effectiveness of ProFashion, we extensively evaluate our method on the MRFashion-7K dataset we collected from the Internet. ProFashion also outperforms previous methods on the UBC Fashion dataset.
EvMic: Event-based Non-contact sound recovery from effective spatial-temporal modeling
Apr 03, 2025When sound waves hit an object, they induce vibrations that produce high-frequency and subtle visual changes, which can be used for recovering the sound. Early studies always encounter trade-offs related to sampling rate, bandwidth, field of view, and the simplicity of the optical path. Recent advances in event camera hardware show good potential for its application in visual sound recovery, because of its superior ability in capturing high-frequency signals. However, existing event-based vibration recovery methods are still sub-optimal for sound recovery. In this work, we propose a novel pipeline for non-contact sound recovery, fully utilizing spatial-temporal information from the event stream. We first generate a large training set using a novel simulation pipeline. Then we designed a network that leverages the sparsity of events to capture spatial information and uses Mamba to model long-term temporal information. Lastly, we train a spatial aggregation block to aggregate information from different locations to further improve signal quality. To capture event signals caused by sound waves, we also designed an imaging system using a laser matrix to enhance the gradient and collected multiple data sequences for testing. Experimental results on synthetic and real-world data demonstrate the effectiveness of our method.
LLaVA-CMoE: Towards Continual Mixture of Experts for Large Vision-Language Models
Mar 27, 2025



Although applying Mixture of Experts to large language models for learning new tasks is widely regarded as an effective strategy for continuous learning, there still remain two major challenges: (1) As the number of tasks grows, simple parameter expansion strategies can lead to excessively large models. (2) Modifying the parameters of the existing router results in the erosion of previously acquired knowledge. In this paper, we present an innovative framework named LLaVA-CMoE, which is a continuous Mixture of Experts (MoE) architecture without any replay data. Specifically, we have developed a method called Probe-Guided Knowledge Extension (PGKE), which employs probe experts to assess whether additional knowledge is required for a specific layer. This approach enables the model to adaptively expand its network parameters based on task distribution, thereby significantly improving the efficiency of parameter expansion. Additionally, we introduce a hierarchical routing algorithm called Probabilistic Task Locator (PTL), where high-level routing captures inter-task information and low-level routing focuses on intra-task details, ensuring that new task experts do not interfere with existing ones. Our experiments shows that our efficient architecture has substantially improved model performance on the Coin benchmark while maintaining a reasonable parameter count.
GLRD: Global-Local Collaborative Reason and Debate with PSL for 3D Open-Vocabulary Detection
Mar 26, 2025



The task of LiDAR-based 3D Open-Vocabulary Detection (3D OVD) requires the detector to learn to detect novel objects from point clouds without off-the-shelf training labels. Previous methods focus on the learning of object-level representations and ignore the scene-level information, thus it is hard to distinguish objects with similar classes. In this work, we propose a Global-Local Collaborative Reason and Debate with PSL (GLRD) framework for the 3D OVD task, considering both local object-level information and global scene-level information. Specifically, LLM is utilized to perform common sense reasoning based on object-level and scene-level information, where the detection result is refined accordingly. To further boost the LLM's ability of precise decisions, we also design a probabilistic soft logic solver (OV-PSL) to search for the optimal solution, and a debate scheme to confirm the class of confusable objects. In addition, to alleviate the uneven distribution of classes, a static balance scheme (SBC) and a dynamic balance scheme (DBC) are designed. In addition, to reduce the influence of noise in data and training, we further propose Reflected Pseudo Labels Generation (RPLG) and Background-Aware Object Localization (BAOL). Extensive experiments conducted on ScanNet and SUN RGB-D demonstrate the superiority of GLRD, where absolute improvements in mean average precision are $+2.82\%$ on SUN RGB-D and $+3.72\%$ on ScanNet in the partial open-vocabulary setting. In the full open-vocabulary setting, the absolute improvements in mean average precision are $+4.03\%$ on ScanNet and $+14.11\%$ on SUN RGB-D.