 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGT-Segmentor: Geometry-Enhanced Cross-View Segmentation
Apr 16, 2026Instance-level object segmentation across disparate egocentric and exocentric views is a fundamental challenge in visual understanding, critical for applications in embodied AI and remote collaboration. This task is exceptionally difficult due to severe changes in scale, perspective, and occlusion, which destabilize direct pixel-level matching. While recent geometry-aware models like VGGT provide a strong foundation for feature alignment, we find they often fail at dense prediction tasks due to significant pixel-level projection drift, even when their internal object-level attention remains consistent. To bridge this gap, we introduce VGGT-Segmentor (VGGT-S), a framework that unifies robust geometric modeling with pixel-accurate semantic segmentation. VGGT-S leverages VGGT's powerful cross-view feature representation and introduces a novel Union Segmentation Head. This head operates in three stages: mask prompt fusion, point-guided prediction, and iterative mask refinement, effectively translating high-level feature alignment into a precise segmentation mask. Furthermore, we propose a single-image self-supervised training strategy that eliminates the need for paired annotations and enables strong generalization. On the Ego-Exo4D benchmark, VGGT-S sets a new state-of-the-art, achieving 67.7% and 68.0% average IoU for Ego to Exo and Exo to Ego tasks, respectively, significantly outperforming prior methods. Notably, our correspondence-free pretrained model surpasses most fully-supervised baselines, demonstrating the effectiveness and scalability of our approach.
Mobile-Agent-v3.5: Multi-platform Fundamental GUI Agents
Feb 15, 2026The paper introduces GUI-Owl-1.5, the latest native GUI agent model that features instruct/thinking variants in multiple sizes (2B/4B/8B/32B/235B) and supports a range of platforms (desktop, mobile, browser, and more) to enable cloud-edge collaboration and real-time interaction. GUI-Owl-1.5 achieves state-of-the-art results on more than 20+ GUI benchmarks on open-source models: (1) on GUI automation tasks, it obtains 56.5 on OSWorld, 71.6 on AndroidWorld, and 48.4 on WebArena; (2) on grounding tasks, it obtains 80.3 on ScreenSpotPro; (3) on tool-calling tasks, it obtains 47.6 on OSWorld-MCP, and 46.8 on MobileWorld; (4) on memory and knowledge tasks, it obtains 75.5 on GUI-Knowledge Bench. GUI-Owl-1.5 incorporates several key innovations: (1) Hybird Data Flywheel: we construct the data pipeline for UI understanding and trajectory generation based on a combination of simulated environments and cloud-based sandbox environments, in order to improve the efficiency and quality of data collection. (2) Unified Enhancement of Agent Capabilities: we use a unified thought-synthesis pipeline to enhance the model's reasoning capabilities, while placing particular emphasis on improving key agent abilities, including Tool/MCP use, memory and multi-agent adaptation; (3) Multi-platform Environment RL Scaling: We propose a new environment RL algorithm, MRPO, to address the challenges of multi-platform conflicts and the low training efficiency of long-horizon tasks. The GUI-Owl-1.5 models are open-sourced, and an online cloud-sandbox demo is available at https://github.com/X-PLUG/MobileAgent.
Mobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025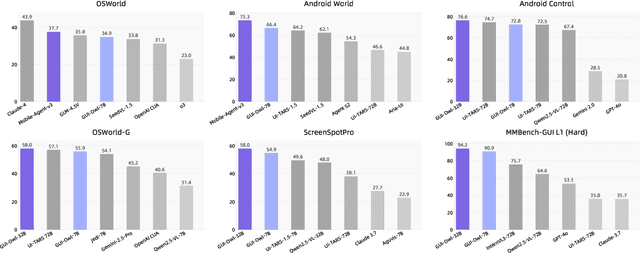
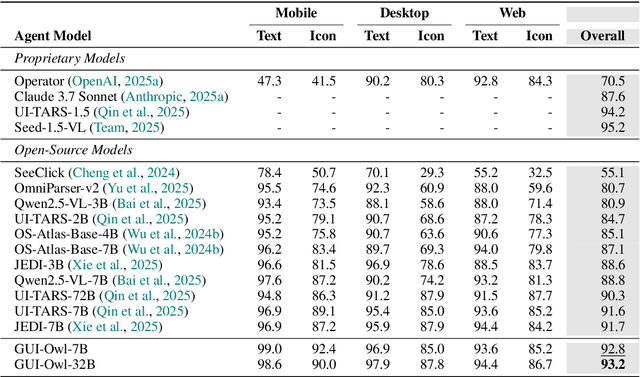
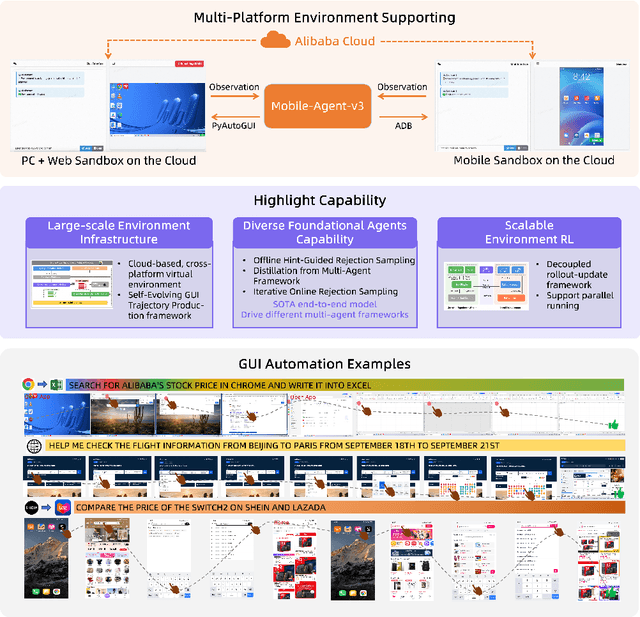
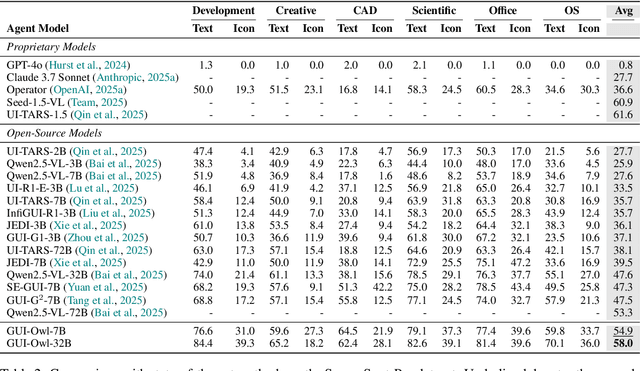
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
DOMR: Establishing Cross-View Segmentation via Dense Object Matching
Aug 06, 2025Cross-view object correspondence involves matching objects between egocentric (first-person) and exocentric (third-person) views. It is a critical yet challenging task for visual understanding. In this work, we propose the Dense Object Matching and Refinement (DOMR) framework to establish dense object correspondences across views. The framework centers around the Dense Object Matcher (DOM) module, which jointly models multiple objects. Unlike methods that directly match individual object masks to image features, DOM leverages both positional and semantic relationships among objects to find correspondences. DOM integrates a proposal generation module with a dense matching module that jointly encodes visual, spatial, and semantic cues, explicitly constructing inter-object relationships to achieve dense matching among objects. Furthermore, we combine DOM with a mask refinement head designed to improve the completeness and accuracy of the predicted masks, forming the complete DOMR framework. Extensive evaluations on the Ego-Exo4D benchmark demonstrate that our approach achieves state-of-the-art performance with a mean IoU of 49.7% on Ego$\to$Exo and 55.2% on Exo$\to$Ego. These results outperform those of previous methods by 5.8% and 4.3%, respectively, validating the effectiveness of our integrated approach for cross-view understanding.