 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Intended Query Detection using E2E Modeling for Continued Conversation
Aug 29, 2022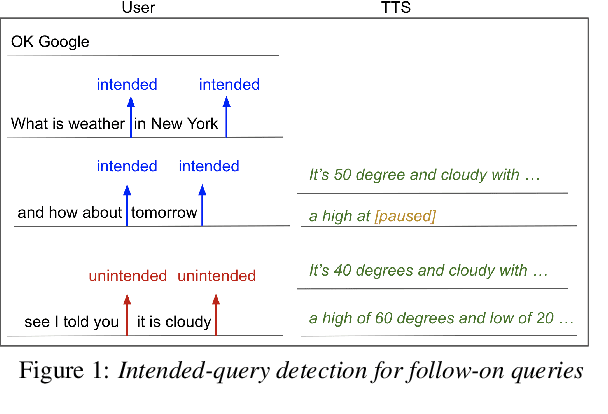

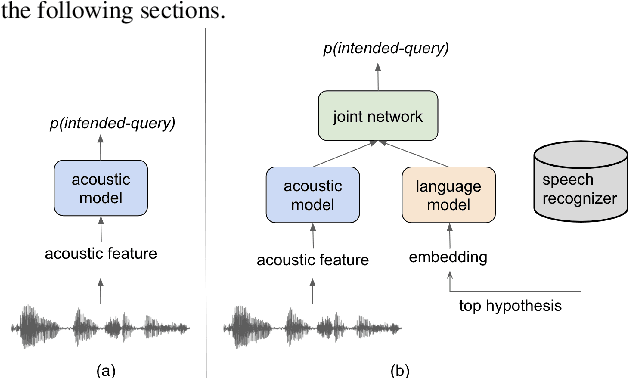
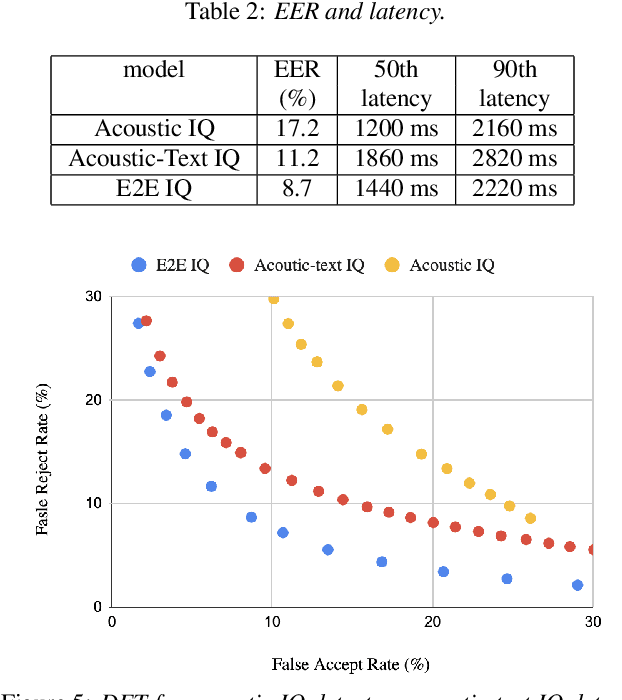
In voice-enabled applications, a predetermined hotword isusually used to activate a device in order to attend to the query.However, speaking queries followed by a hotword each timeintroduces a cognitive burden in continued conversations. Toavoid repeating a hotword, we propose a streaming end-to-end(E2E) intended query detector that identifies the utterancesdirected towards the device and filters out other utterancesnot directed towards device. The proposed approach incor-porates the intended query detector into the E2E model thatalready folds different components of the speech recognitionpipeline into one neural network.The E2E modeling onspeech decoding and intended query detection also allows us todeclare a quick intended query detection based on early partialrecognition result, which is important to decrease latencyand make the system responsive. We demonstrate that theproposed E2E approach yields a 22% relative improvement onequal error rate (EER) for the detection accuracy and 600 mslatency improvement compared with an independent intendedquery detector. In our experiment, the proposed model detectswhether the user is talking to the device with a 8.7% EERwithin 1.4 seconds of median latency after user starts speaking.
Turn-Taking Prediction for Natural Conversational Speech
Aug 29, 2022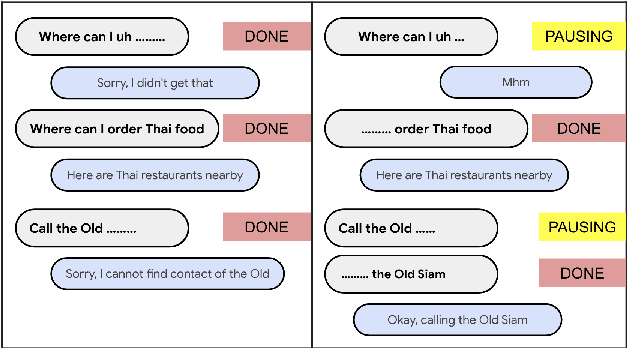
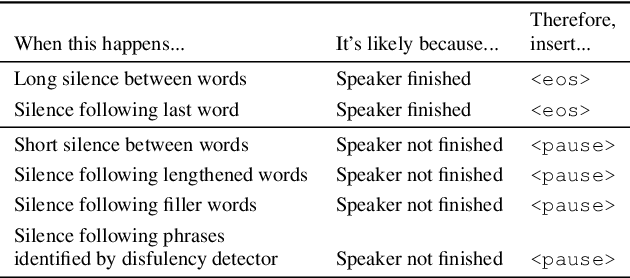
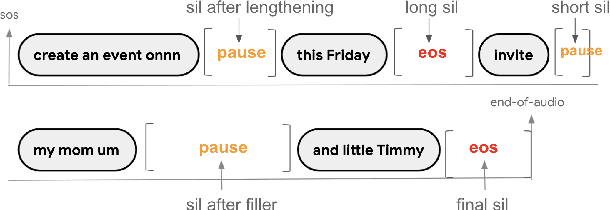
While a streaming voice assistant system has been used in many applications, this system typically focuses on unnatural, one-shot interactions assuming input from a single voice query without hesitation or disfluency. However, a common conversational utterance often involves multiple queries with turn-taking, in addition to disfluencies. These disfluencies include pausing to think, hesitations, word lengthening, filled pauses and repeated phrases. This makes doing speech recognition with conversational speech, including one with multiple queries, a challenging task. To better model the conversational interaction, it is critical to discriminate disfluencies and end of query in order to allow the user to hold the floor for disfluencies while having the system respond as quickly as possible when the user has finished speaking. In this paper, we present a turntaking predictor built on top of the end-to-end (E2E) speech recognizer. Our best system is obtained by jointly optimizing for ASR task and detecting when the user is paused to think or finished speaking. The proposed approach demonstrates over 97% recall rate and 85% precision rate on predicting true turn-taking with only 100 ms latency on a test set designed with 4 types of disfluencies inserted in conversational utterances.
E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
Apr 22, 2022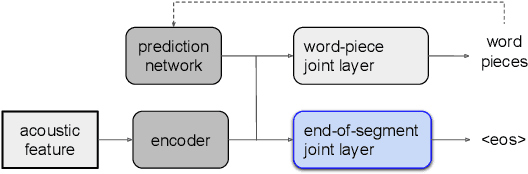
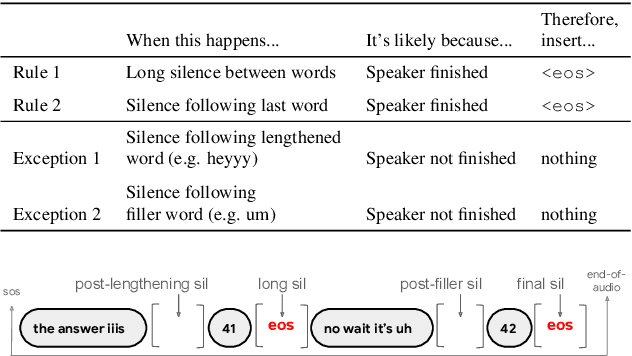
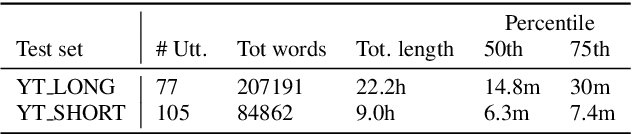
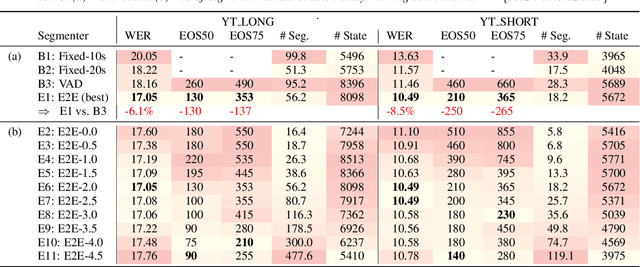
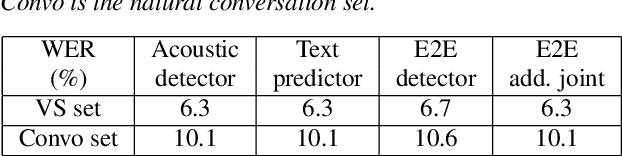
Improving the performance of end-to-end ASR models on long utterances ranging from minutes to hours in length is an ongoing challenge in speech recognition. A common solution is to segment the audio in advance using a separate voice activity detector (VAD) that decides segment boundary locations based purely on acoustic speech/non-speech information. VAD segmenters, however, may be sub-optimal for real-world speech where, e.g., a complete sentence that should be taken as a whole may contain hesitations in the middle ("set an alarm for... 5 o'clock"). We propose to replace the VAD with an end-to-end ASR model capable of predicting segment boundaries in a streaming fashion, allowing the segmentation decision to be conditioned not only on better acoustic features but also on semantic features from the decoded text with negligible extra computation. In experiments on real world long-form audio (YouTube) with lengths of up to 30 minutes, we demonstrate 8.5% relative WER improvement and 250 ms reduction in median end-of-segment latency compared to the VAD segmenter baseline on a state-of-the-art Conformer RNN-T model.
Improving the fusion of acoustic and text representations in RNN-T
Jan 25, 2022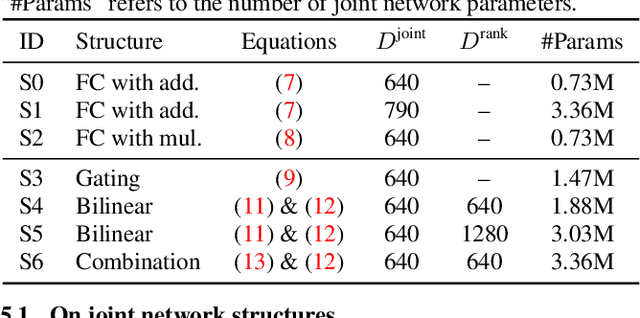

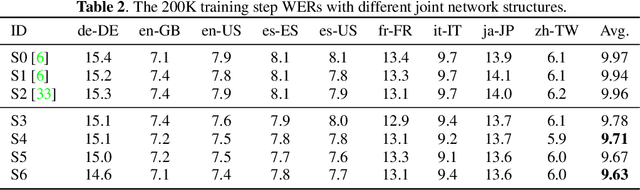
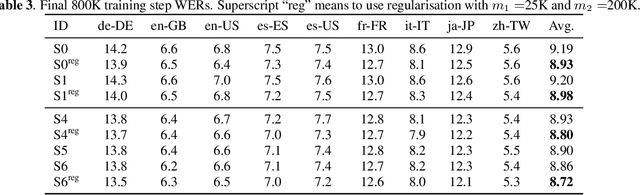
The recurrent neural network transducer (RNN-T) has recently become the mainstream end-to-end approach for streaming automatic speech recognition (ASR). To estimate the output distributions over subword units, RNN-T uses a fully connected layer as the joint network to fuse the acoustic representations extracted using the acoustic encoder with the text representations obtained using the prediction network based on the previous subword units. In this paper, we propose to use gating, bilinear pooling, and a combination of them in the joint network to produce more expressive representations to feed into the output layer. A regularisation method is also proposed to enable better acoustic encoder training by reducing the gradients back-propagated into the prediction network at the beginning of RNN-T training. Experimental results on a multilingual ASR setting for voice search over nine languages show that the joint use of the proposed methods can result in 4%--5% relative word error rate reductions with only a few million extra parameters.
FastEmit: Low-latency Streaming ASR with Sequence-level Emission Regularization
Oct 21, 2020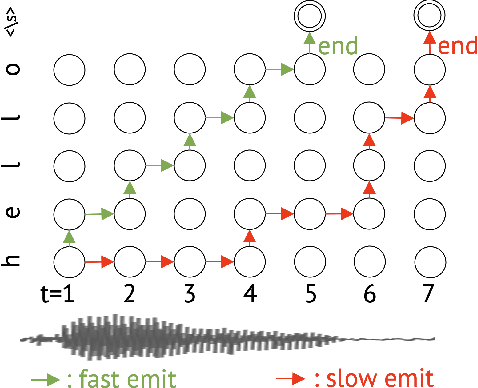
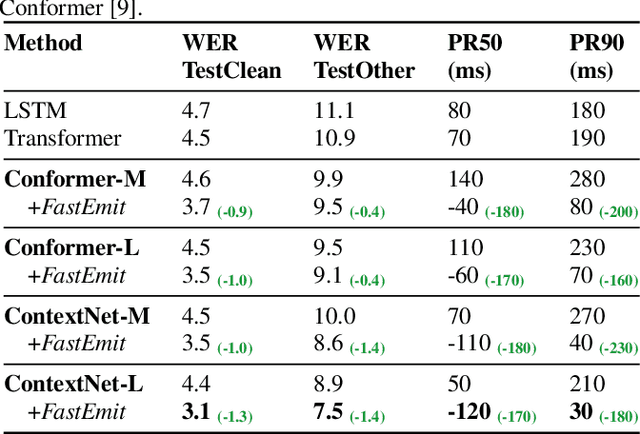

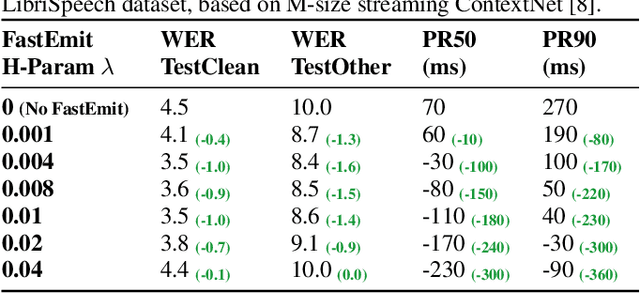
Streaming automatic speech recognition (ASR) aims to emit each hypothesized word as quickly and accurately as possible. However, emitting fast without degrading quality, as measured by word error rate (WER), is highly challenging. Existing approaches including Early and Late Penalties and Constrained Alignments penalize emission delay by manipulating per-token or per-frame probability prediction in sequence transducer models. While being successful in reducing delay, these approaches suffer from significant accuracy regression and also require additional word alignment information from an existing model. In this work, we propose a sequence-level emission regularization method, named FastEmit, that applies latency regularization directly on per-sequence probability in training transducer models, and does not require any alignment. We demonstrate that FastEmit is more suitable to the sequence-level optimization of transducer models for streaming ASR by applying it on various end-to-end streaming ASR networks including RNN-Transducer, Transformer-Transducer, ConvNet-Transducer and Conformer-Transducer. We achieve 150-300 ms latency reduction with significantly better accuracy over previous techniques on a Voice Search test set. FastEmit also improves streaming ASR accuracy from 4.4%/8.9% to 3.1%/7.5% WER, meanwhile reduces 90th percentile latency from 210 ms to only 30 ms on LibriSpeech.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020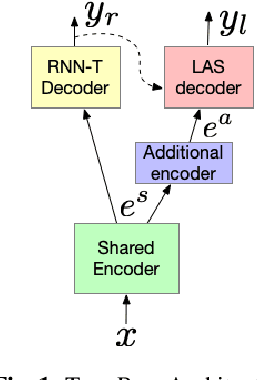
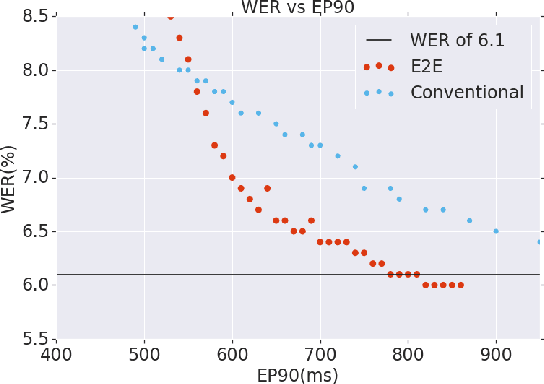
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
Personal VAD: Speaker-Conditioned Voice Activity Detection
Aug 12, 2019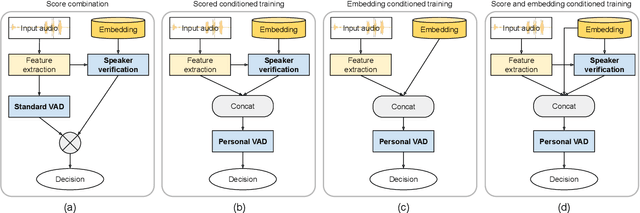

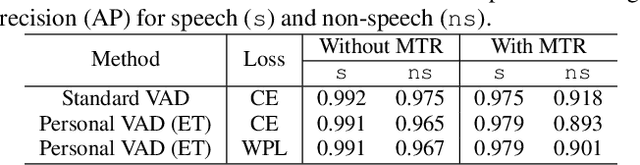
In this paper, we propose "personal VAD", a system to detect the voice activity of a target speaker at the frame level. This system is useful for gating the inputs to a streaming speech recognition system, such that it only triggers for the target user, which helps reduce the computational cost and battery consumption. We achieve this by training a VAD-alike neural network that is conditioned on the target speaker embedding or the speaker verification score. For every frame, personal VAD outputs the scores for three classes: non-speech, target speaker speech, and non-target speaker speech. With our optimal setup, we are able to train a 130KB model that outperforms a baseline system where individually trained standard VAD and speaker recognition network are combined to perform the same task.
Deep Learning for Audio Signal Processing
May 25, 2019
Given the recent surge in developments of deep learning, this article provides a review of the state-of-the-art deep learning techniques for audio signal processing. Speech, music, and environmental sound processing are considered side-by-side, in order to point out similarities and differences between the domains, highlighting general methods, problems, key references, and potential for cross-fertilization between areas. The dominant feature representations (in particular, log-mel spectra and raw waveform) and deep learning models are reviewed, including convolutional neural networks, variants of the long short-term memory architecture, as well as more audio-specific neural network models. Subsequently, prominent deep learning application areas are covered, i.e. audio recognition (automatic speech recognition, music information retrieval, environmental sound detection, localization and tracking) and synthesis and transformation (source separation, audio enhancement, generative models for speech, sound, and music synthesis). Finally, key issues and future questions regarding deep learning applied to audio signal processing are identified.
* 15 pages, 2 pdf figures
Streaming End-to-end Speech Recognition For Mobile Devices
Nov 15, 2018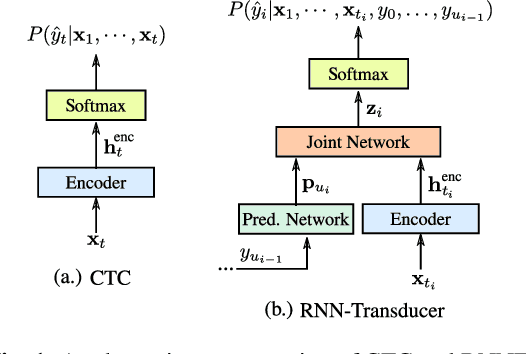
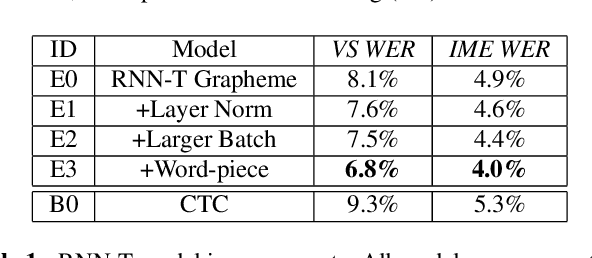
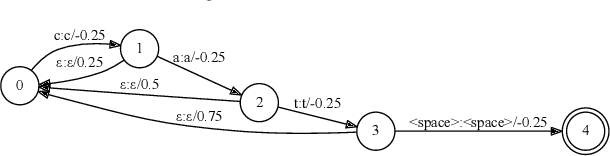
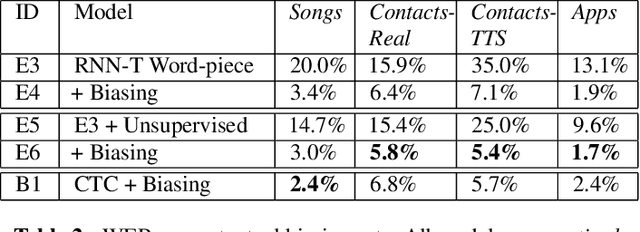
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context (e.g., contact lists); and above all, they must be extremely accurate. In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories.