 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonal VAD: Speaker-Conditioned Voice Activity Detection
Paper and Code
Aug 12, 2019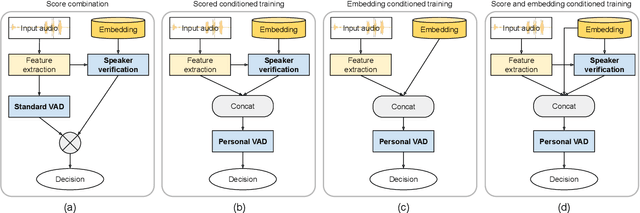

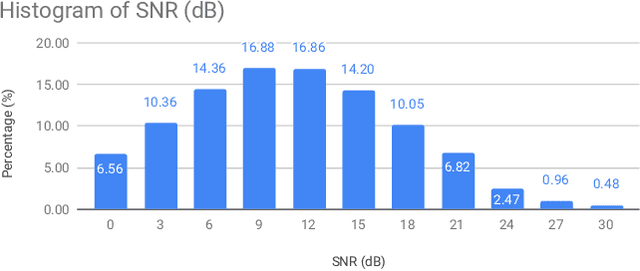
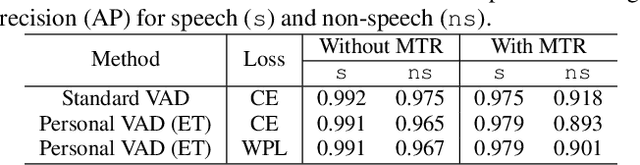
In this paper, we propose "personal VAD", a system to detect the voice activity of a target speaker at the frame level. This system is useful for gating the inputs to a streaming speech recognition system, such that it only triggers for the target user, which helps reduce the computational cost and battery consumption. We achieve this by training a VAD-alike neural network that is conditioned on the target speaker embedding or the speaker verification score. For every frame, personal VAD outputs the scores for three classes: non-speech, target speaker speech, and non-target speaker speech. With our optimal setup, we are able to train a 130KB model that outperforms a baseline system where individually trained standard VAD and speaker recognition network are combined to perform the same task.