 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Analysis of Detecting Large Model-Generated Time Series
Nov 12, 2025Motivated by the increasing risks of data misuse and fabrication, we investigate the problem of identifying synthetic time series generated by Time-Series Large Models (TSLMs) in this work. While there are extensive researches on detecting model generated text, we find that these existing methods are not applicable to time series data due to the fundamental modality difference, as time series usually have lower information density and smoother probability distributions than text data, which limit the discriminative power of token-based detectors. To address this issue, we examine the subtle distributional differences between real and model-generated time series and propose the contraction hypothesis, which states that model-generated time series, unlike real ones, exhibit progressively decreasing uncertainty under recursive forecasting. We formally prove this hypothesis under theoretical assumptions on model behavior and time series structure. Model-generated time series exhibit progressively concentrated distributions under recursive forecasting, leading to uncertainty contraction. We provide empirical validation of the hypothesis across diverse datasets. Building on this insight, we introduce the Uncertainty Contraction Estimator (UCE), a white-box detector that aggregates uncertainty metrics over successive prefixes to identify TSLM-generated time series. Extensive experiments on 32 datasets show that UCE consistently outperforms state-of-the-art baselines, offering a reliable and generalizable solution for detecting model-generated time series.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
REMA: A Unified Reasoning Manifold Framework for Interpreting Large Language Model
Sep 26, 2025Understanding how Large Language Models (LLMs) perform complex reasoning and their failure mechanisms is a challenge in interpretability research. To provide a measurable geometric analysis perspective, we define the concept of the Reasoning Manifold, a latent low-dimensional geometric structure formed by the internal representations corresponding to all correctly reasoned generations. This structure can be conceptualized as the embodiment of the effective thinking paths that the model has learned to successfully solve a given task. Based on this concept, we build REMA, a framework that explains the origins of failures by quantitatively comparing the spatial relationships of internal model representations corresponding to both erroneous and correct reasoning samples. Specifically, REMA first quantifies the geometric deviation of each erroneous representation by calculating its k-nearest neighbors distance to the approximated manifold formed by correct representations, thereby providing a unified failure signal. It then localizes the divergence points where these deviations first become significant by tracking this deviation metric across the model's layers and comparing it against a baseline of internal fluctuations from correct representations, thus identifying where the reasoning chain begins to go off-track. Our extensive experiments on diverse language and multimodal models and tasks demonstrate the low-dimensional nature of the reasoning manifold and the high separability between erroneous and correct reasoning representations. The results also validate the effectiveness of the REMA framework in analyzing the origins of reasoning failures. This research connects abstract reasoning failures to measurable geometric deviations in representations, providing new avenues for in-depth understanding and diagnosis of the internal computational processes of black-box models.
GitTaskBench: A Benchmark for Code Agents Solving Real-World Tasks Through Code Repository Leveraging
Aug 26, 2025



Beyond scratch coding, exploiting large-scale code repositories (e.g., GitHub) for practical tasks is vital in real-world software development, yet current benchmarks rarely evaluate code agents in such authentic, workflow-driven scenarios. To bridge this gap, we introduce GitTaskBench, a benchmark designed to systematically assess this capability via 54 realistic tasks across 7 modalities and 7 domains. Each task pairs a relevant repository with an automated, human-curated evaluation harness specifying practical success criteria. Beyond measuring execution and task success, we also propose the alpha-value metric to quantify the economic benefit of agent performance, which integrates task success rates, token cost, and average developer salaries. Experiments across three state-of-the-art agent frameworks with multiple advanced LLMs show that leveraging code repositories for complex task solving remains challenging: even the best-performing system, OpenHands+Claude 3.7, solves only 48.15% of tasks. Error analysis attributes over half of failures to seemingly mundane yet critical steps like environment setup and dependency resolution, highlighting the need for more robust workflow management and increased timeout preparedness. By releasing GitTaskBench, we aim to drive progress and attention toward repository-aware code reasoning, execution, and deployment -- moving agents closer to solving complex, end-to-end real-world tasks. The benchmark and code are open-sourced at https://github.com/QuantaAlpha/GitTaskBench.
Fence off Anomaly Interference: Cross-Domain Distillation for Fully Unsupervised Anomaly Detection
Aug 25, 2025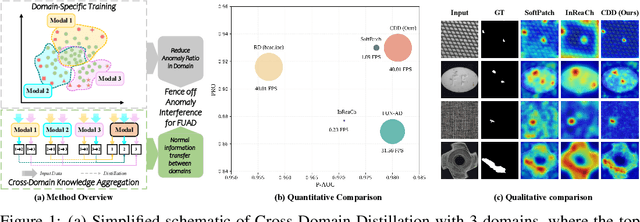

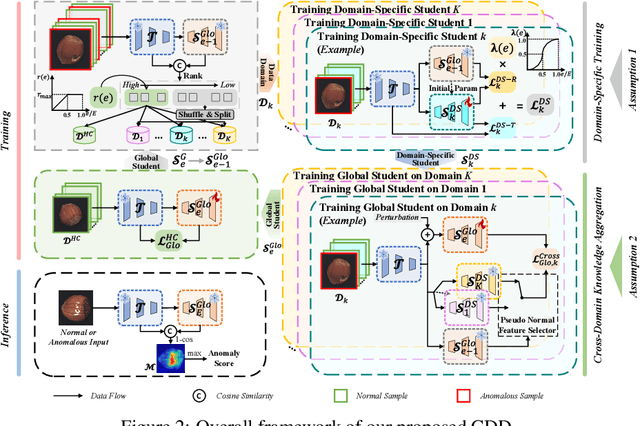
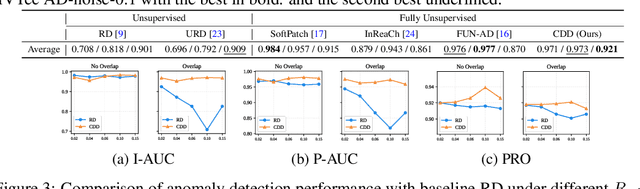
Fully Unsupervised Anomaly Detection (FUAD) is a practical extension of Unsupervised Anomaly Detection (UAD), aiming to detect anomalies without any labels even when the training set may contain anomalous samples. To achieve FUAD, we pioneer the introduction of Knowledge Distillation (KD) paradigm based on teacher-student framework into the FUAD setting. However, due to the presence of anomalies in the training data, traditional KD methods risk enabling the student to learn the teacher's representation of anomalies under FUAD setting, thereby resulting in poor anomaly detection performance. To address this issue, we propose a novel Cross-Domain Distillation (CDD) framework based on the widely studied reverse distillation (RD) paradigm. Specifically, we design a Domain-Specific Training, which divides the training set into multiple domains with lower anomaly ratios and train a domain-specific student for each. Cross-Domain Knowledge Aggregation is then performed, where pseudo-normal features generated by domain-specific students collaboratively guide a global student to learn generalized normal representations across all samples. Experimental results on noisy versions of the MVTec AD and VisA datasets demonstrate that our method achieves significant performance improvements over the baseline, validating its effectiveness under FUAD setting.
Learning Point Cloud Representations with Pose Continuity for Depth-Based Category-Level 6D Object Pose Estimation
Aug 20, 2025Category-level object pose estimation aims to predict the 6D pose and 3D size of objects within given categories. Existing approaches for this task rely solely on 6D poses as supervisory signals without explicitly capturing the intrinsic continuity of poses, leading to inconsistencies in predictions and reduced generalization to unseen poses. To address this limitation, we propose HRC-Pose, a novel depth-only framework for category-level object pose estimation, which leverages contrastive learning to learn point cloud representations that preserve the continuity of 6D poses. HRC-Pose decouples object pose into rotation and translation components, which are separately encoded and leveraged throughout the network. Specifically, we introduce a contrastive learning strategy for multi-task, multi-category scenarios based on our 6D pose-aware hierarchical ranking scheme, which contrasts point clouds from multiple categories by considering rotational and translational differences as well as categorical information. We further design pose estimation modules that separately process the learned rotation-aware and translation-aware embeddings. Our experiments demonstrate that HRC-Pose successfully learns continuous feature spaces. Results on REAL275 and CAMERA25 benchmarks show that our method consistently outperforms existing depth-only state-of-the-art methods and runs in real-time, demonstrating its effectiveness and potential for real-world applications. Our code is at https://github.com/zhujunli1993/HRC-Pose.
Integrating LLM-Derived Multi-Semantic Intent into Graph Model for Session-based Recommendation
Jul 27, 2025Session-based recommendation (SBR) is mainly based on anonymous user interaction sequences to recommend the items that the next user is most likely to click. Currently, the most popular and high-performing SBR methods primarily leverage graph neural networks (GNNs), which model session sequences as graph-structured data to effectively capture user intent. However, most GNNs-based SBR methods primarily focus on modeling the ID sequence information of session sequences, while neglecting the rich semantic information embedded within them. This limitation significantly hampers model's ability to accurately infer users' true intention. To address above challenge, this paper proposes a novel SBR approach called Integrating LLM-Derived Multi-Semantic Intent into Graph Model for Session-based Recommendation (LLM-DMsRec). The method utilizes a pre-trained GNN model to select the top-k items as candidate item sets and designs prompts along with a large language model (LLM) to infer multi-semantic intents from these candidate items. Specifically, we propose an alignment mechanism that effectively integrates the semantic intent inferred by the LLM with the structural intent captured by GNNs. Extensive experiments conducted on the Beauty and ML-1M datasets demonstrate that the proposed method can be seamlessly integrated into GNNs framework, significantly enhancing its recommendation performance.
MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
Jun 05, 2025We introduce MonkeyOCR, a vision-language model for document parsing that advances the state of the art by leveraging a Structure-Recognition-Relation (SRR) triplet paradigm. This design simplifies what would otherwise be a complex multi-tool pipeline (as in MinerU's modular approach) and avoids the inefficiencies of processing full pages with giant end-to-end models (e.g., large multimodal LLMs like Qwen-VL). In SRR, document parsing is abstracted into three fundamental questions - "Where is it?" (structure), "What is it?" (recognition), and "How is it organized?" (relation) - corresponding to layout analysis, content identification, and logical ordering. This focused decomposition balances accuracy and speed: it enables efficient, scalable processing without sacrificing precision. To train and evaluate this approach, we introduce the MonkeyDoc (the most comprehensive document parsing dataset to date), with 3.9 million instances spanning over ten document types in both Chinese and English. Experiments show that MonkeyOCR outperforms MinerU by an average of 5.1%, with particularly notable improvements on challenging content such as formulas (+15.0%) and tables (+8.6%). Remarkably, our 3B-parameter model surpasses much larger and top-performing models, including Qwen2.5-VL (72B) and Gemini 2.5 Pro, achieving state-of-the-art average performance on English document parsing tasks. In addition, MonkeyOCR processes multi-page documents significantly faster (0.84 pages per second compared to 0.65 for MinerU and 0.12 for Qwen2.5-VL-7B). The 3B model can be efficiently deployed for inference on a single NVIDIA 3090 GPU. Code and models will be released at https://github.com/Yuliang-Liu/MonkeyOCR.
EECD-Net: Energy-Efficient Crack Detection with Spiking Neural Networks and Gated Attention
Jun 05, 2025Crack detection on road surfaces is a critical measurement technology in the instrumentation domain, essential for ensuring infrastructure safety and transportation reliability. However, due to limited energy and low-resolution imaging, smart terminal devices struggle to maintain real-time monitoring performance. To overcome these challenges, this paper proposes a multi-stage detection approach for road crack detection, EECD-Net, to enhance accuracy and energy efficiency of instrumentation. Specifically, the sophisticated Super-Resolution Convolutional Neural Network (SRCNN) is employed to address the inherent challenges of low-quality images, which effectively enhance image resolution while preserving critical structural details. Meanwhile, a Spike Convolution Unit (SCU) with Continuous Integrate-and-Fire (CIF) neurons is proposed to convert these images into sparse pulse sequences, significantly reducing power consumption. Additionally, a Gated Attention Transformer (GAT) module is designed to strategically fuse multi-scale feature representations through adaptive attention mechanisms, effectively capturing both long-range dependencies and intricate local crack patterns, and significantly enhancing detection robustness across varying crack morphologies. The experiments on the CrackVision12K benchmark demonstrate that EECD-Net achieves a remarkable 98.6\% detection accuracy, surpassing state-of-the-art counterparts such as Hybrid-Segmentor by a significant 1.5\%. Notably, the EECD-Net maintains exceptional energy efficiency, consuming merely 5.6 mJ, which is a substantial 33\% reduction compared to baseline implementations. This work pioneers a transformative approach in instrumentation-based crack detection, offering a scalable, low-power solution for real-time, large-scale infrastructure monitoring in resource-constrained environments.
RepoMaster: Autonomous Exploration and Understanding of GitHub Repositories for Complex Task Solving
May 27, 2025



The ultimate goal of code agents is to solve complex tasks autonomously. Although large language models (LLMs) have made substantial progress in code generation, real-world tasks typically demand full-fledged code repositories rather than simple scripts. Building such repositories from scratch remains a major challenge. Fortunately, GitHub hosts a vast, evolving collection of open-source repositories, which developers frequently reuse as modular components for complex tasks. Yet, existing frameworks like OpenHands and SWE-Agent still struggle to effectively leverage these valuable resources. Relying solely on README files provides insufficient guidance, and deeper exploration reveals two core obstacles: overwhelming information and tangled dependencies of repositories, both constrained by the limited context windows of current LLMs. To tackle these issues, we propose RepoMaster, an autonomous agent framework designed to explore and reuse GitHub repositories for solving complex tasks. For efficient understanding, RepoMaster constructs function-call graphs, module-dependency graphs, and hierarchical code trees to identify essential components, providing only identified core elements to the LLMs rather than the entire repository. During autonomous execution, it progressively explores related components using our exploration tools and prunes information to optimize context usage. Evaluated on the adjusted MLE-bench, RepoMaster achieves a 110% relative boost in valid submissions over the strongest baseline OpenHands. On our newly released GitTaskBench, RepoMaster lifts the task-pass rate from 24.1% to 62.9% while reducing token usage by 95%. Our code and demonstration materials are publicly available at https://github.com/wanghuacan/RepoMaster.