 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Point Cloud Representations with Pose Continuity for Depth-Based Category-Level 6D Object Pose Estimation
Aug 20, 2025Category-level object pose estimation aims to predict the 6D pose and 3D size of objects within given categories. Existing approaches for this task rely solely on 6D poses as supervisory signals without explicitly capturing the intrinsic continuity of poses, leading to inconsistencies in predictions and reduced generalization to unseen poses. To address this limitation, we propose HRC-Pose, a novel depth-only framework for category-level object pose estimation, which leverages contrastive learning to learn point cloud representations that preserve the continuity of 6D poses. HRC-Pose decouples object pose into rotation and translation components, which are separately encoded and leveraged throughout the network. Specifically, we introduce a contrastive learning strategy for multi-task, multi-category scenarios based on our 6D pose-aware hierarchical ranking scheme, which contrasts point clouds from multiple categories by considering rotational and translational differences as well as categorical information. We further design pose estimation modules that separately process the learned rotation-aware and translation-aware embeddings. Our experiments demonstrate that HRC-Pose successfully learns continuous feature spaces. Results on REAL275 and CAMERA25 benchmarks show that our method consistently outperforms existing depth-only state-of-the-art methods and runs in real-time, demonstrating its effectiveness and potential for real-world applications. Our code is at https://github.com/zhujunli1993/HRC-Pose.
Depth-based 6DoF Object Pose Estimation using Swin Transformer
Mar 03, 2023Accurately estimating the 6D pose of objects is crucial for many applications, such as robotic grasping, autonomous driving, and augmented reality. However, this task becomes more challenging in poor lighting conditions or when dealing with textureless objects. To address this issue, depth images are becoming an increasingly popular choice due to their invariance to a scene's appearance and the implicit incorporation of essential geometric characteristics. However, fully leveraging depth information to improve the performance of pose estimation remains a difficult and under-investigated problem. To tackle this challenge, we propose a novel framework called SwinDePose, that uses only geometric information from depth images to achieve accurate 6D pose estimation. SwinDePose first calculates the angles between each normal vector defined in a depth image and the three coordinate axes in the camera coordinate system. The resulting angles are then formed into an image, which is encoded using Swin Transformer. Additionally, we apply RandLA-Net to learn the representations from point clouds. The resulting image and point clouds embeddings are concatenated and fed into a semantic segmentation module and a 3D keypoints localization module. Finally, we estimate 6D poses using a least-square fitting approach based on the target object's predicted semantic mask and 3D keypoints. In experiments on the LineMod and Occlusion LineMod datasets, SwinDePose outperforms existing state-of-the-art methods for 6D object pose estimation using depth images. This demonstrates the effectiveness of our approach and highlights its potential for improving performance in real-world scenarios. Our code is at https://github.com/zhujunli1993/SwinDePose.
You Only Need One Detector: Unified Object Detector for Different Modalities based on Vision Transformers
Jul 03, 2022


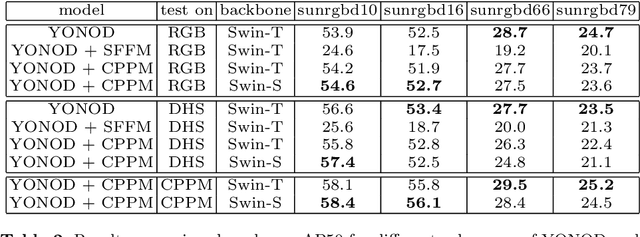
Most systems use different models for different modalities, such as one model for processing RGB images and one for depth images. Meanwhile, some recent works discovered that an identical model for one modality can be used for another modality with the help of cross modality transfer learning. In this article, we further find out that by using a vision transformer together with cross/inter modality transfer learning, a unified detector can achieve better performances when using different modalities as inputs. The unified model is useful as we don't need to maintain separate models or weights for robotics, hence, it is more efficient. One application scenario of our unified system for robotics can be: without any model architecture and model weights updating, robotics can switch smoothly on using RGB camera or both RGB and Depth Sensor during the day time and Depth sensor during the night time . Experiments on SUN RGB-D dataset show: Our unified model is not only efficient, but also has a similar or better performance in terms of mAP50 based on SUNRGBD16 category: compare with the RGB only one, ours is slightly worse (52.3 $\to$ 51.9). compare with the point cloud only one, we have similar performance (52.7 $\to$ 52.8); When using the novel inter modality mixing method proposed in this work, our model can achieve a significantly better performance with 3.1 (52.7 $\to$ 55.8) absolute improvement comparing with the previous best result. Code (including training/inference logs and model checkpoints) is available: \url{https://github.com/liketheflower/YONOD.git}