 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformalized Credal Regions for Classification with Ambiguous Ground Truth
Nov 07, 2024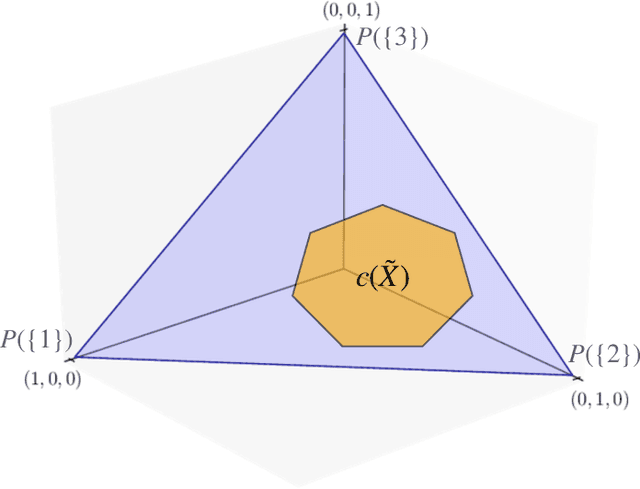
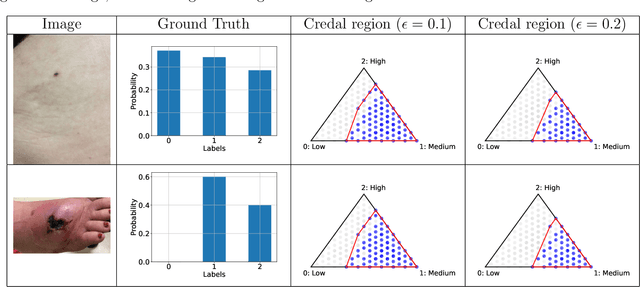
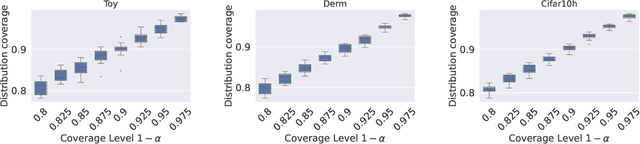
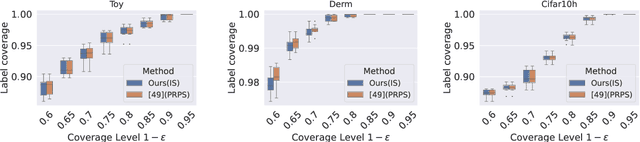
An open question in \emph{Imprecise Probabilistic Machine Learning} is how to empirically derive a credal region (i.e., a closed and convex family of probabilities on the output space) from the available data, without any prior knowledge or assumption. In classification problems, credal regions are a tool that is able to provide provable guarantees under realistic assumptions by characterizing the uncertainty about the distribution of the labels. Building on previous work, we show that credal regions can be directly constructed using conformal methods. This allows us to provide a novel extension of classical conformal prediction to problems with ambiguous ground truth, that is, when the exact labels for given inputs are not exactly known. The resulting construction enjoys desirable practical and theoretical properties: (i) conformal coverage guarantees, (ii) smaller prediction sets (compared to classical conformal prediction regions) and (iii) disentanglement of uncertainty sources (epistemic, aleatoric). We empirically verify our findings on both synthetic and real datasets.
Have the VLMs Lost Confidence? A Study of Sycophancy in VLMs
Oct 15, 2024



In the study of LLMs, sycophancy represents a prevalent hallucination that poses significant challenges to these models. Specifically, LLMs often fail to adhere to original correct responses, instead blindly agreeing with users' opinions, even when those opinions are incorrect or malicious. However, research on sycophancy in visual language models (VLMs) has been scarce. In this work, we extend the exploration of sycophancy from LLMs to VLMs, introducing the MM-SY benchmark to evaluate this phenomenon. We present evaluation results from multiple representative models, addressing the gap in sycophancy research for VLMs. To mitigate sycophancy, we propose a synthetic dataset for training and employ methods based on prompts, supervised fine-tuning, and DPO. Our experiments demonstrate that these methods effectively alleviate sycophancy in VLMs. Additionally, we probe VLMs to assess the semantic impact of sycophancy and analyze the attention distribution of visual tokens. Our findings indicate that the ability to prevent sycophancy is predominantly observed in higher layers of the model. The lack of attention to image knowledge in these higher layers may contribute to sycophancy, and enhancing image attention at high layers proves beneficial in mitigating this issue.
Conformal Structured Prediction
Oct 08, 2024



Conformal prediction has recently emerged as a promising strategy for quantifying the uncertainty of a predictive model; these algorithms modify the model to output sets of labels that are guaranteed to contain the true label with high probability. However, existing conformal prediction algorithms have largely targeted classification and regression settings, where the structure of the prediction set has a simple form as a level set of the scoring function. However, for complex structured outputs such as text generation, these prediction sets might include a large number of labels and therefore be hard for users to interpret. In this paper, we propose a general framework for conformal prediction in the structured prediction setting, that modifies existing conformal prediction algorithms to output structured prediction sets that implicitly represent sets of labels. In addition, we demonstrate how our approach can be applied in domains where the prediction sets can be represented as a set of nodes in a directed acyclic graph; for instance, for hierarchical labels such as image classification, a prediction set might be a small subset of coarse labels implicitly representing the prediction set of all their more fine-descendants. We demonstrate how our algorithm can be used to construct prediction sets that satisfy a desired coverage guarantee in several domains.
Imaging foundation model for universal enhancement of non-ideal measurement CT
Oct 02, 2024Non-ideal measurement computed tomography (NICT), which sacrifices optimal imaging standards for new advantages in CT imaging, is expanding the clinical application scope of CT images. However, with the reduction of imaging standards, the image quality has also been reduced, extremely limiting the clinical acceptability. Although numerous studies have demonstrated the feasibility of deep learning for the NICT enhancement in specific scenarios, their high data cost and limited generalizability have become large obstacles. The recent research on the foundation model has brought new opportunities for building a universal NICT enhancement model - bridging the image quality degradation with minimal data cost. However, owing to the challenges in the collection of large pre-training datasets and the compatibility of data variation, no success has been reported. In this paper, we propose a multi-scale integrated Transformer AMPlifier (TAMP), the first imaging foundation model for universal NICT enhancement. It has been pre-trained on a large-scale physical-driven simulation dataset with 3.6 million NICT-ICT image pairs, and is able to directly generalize to the NICT enhancement tasks with various non-ideal settings and body regions. Via the adaptation with few data, it can further achieve professional performance in real-world specific scenarios. Our extensive experiments have demonstrated that the proposed TAMP has significant potential for promoting the exploration and application of NICT and serving a wider range of medical scenarios.
TSdetector: Temporal-Spatial Self-correction Collaborative Learning for Colonoscopy Video Detection
Sep 30, 2024



CNN-based object detection models that strike a balance between performance and speed have been gradually used in polyp detection tasks. Nevertheless, accurately locating polyps within complex colonoscopy video scenes remains challenging since existing methods ignore two key issues: intra-sequence distribution heterogeneity and precision-confidence discrepancy. To address these challenges, we propose a novel Temporal-Spatial self-correction detector (TSdetector), which first integrates temporal-level consistency learning and spatial-level reliability learning to detect objects continuously. Technically, we first propose a global temporal-aware convolution, assembling the preceding information to dynamically guide the current convolution kernel to focus on global features between sequences. In addition, we designed a hierarchical queue integration mechanism to combine multi-temporal features through a progressive accumulation manner, fully leveraging contextual consistency information together with retaining long-sequence-dependency features. Meanwhile, at the spatial level, we advance a position-aware clustering to explore the spatial relationships among candidate boxes for recalibrating prediction confidence adaptively, thus eliminating redundant bounding boxes efficiently. The experimental results on three publicly available polyp video dataset show that TSdetector achieves the highest polyp detection rate and outperforms other state-of-the-art methods. The code can be available at https://github.com/soleilssss/TSdetector.
Universal Medical Image Representation Learning with Compositional Decoders
Sep 30, 2024



Visual-language models have advanced the development of universal models, yet their application in medical imaging remains constrained by specific functional requirements and the limited data. Current general-purpose models are typically designed with task-specific branches and heads, which restricts the shared feature space and the flexibility of model. To address these challenges, we have developed a decomposed-composed universal medical imaging paradigm (UniMed) that supports tasks at all levels. To this end, we first propose a decomposed decoder that can predict two types of outputs -- pixel and semantic, based on a defined input queue. Additionally, we introduce a composed decoder that unifies the input and output spaces and standardizes task annotations across different levels into a discrete token format. The coupled design of these two components enables the model to flexibly combine tasks and mutual benefits. Moreover, our joint representation learning strategy skilfully leverages large amounts of unlabeled data and unsupervised loss, achieving efficient one-stage pretraining for more robust performance. Experimental results show that UniMed achieves state-of-the-art performance on eight datasets across all three tasks and exhibits strong zero-shot and 100-shot transferability. We will release the code and trained models upon the paper's acceptance.
Dashing for the Golden Snitch: Multi-Drone Time-Optimal Motion Planning with Multi-Agent Reinforcement Learning
Sep 25, 2024



Recent innovations in autonomous drones have facilitated time-optimal flight in single-drone configurations and enhanced maneuverability in multi-drone systems through the application of optimal control and learning-based methods. However, few studies have achieved time-optimal motion planning for multi-drone systems, particularly during highly agile maneuvers or in dynamic scenarios. This paper presents a decentralized policy network for time-optimal multi-drone flight using multi-agent reinforcement learning. To strike a balance between flight efficiency and collision avoidance, we introduce a soft collision penalty inspired by optimization-based methods. By customizing PPO in a centralized training, decentralized execution (CTDE) fashion, we unlock higher efficiency and stability in training, while ensuring lightweight implementation. Extensive simulations show that, despite slight performance trade-offs compared to single-drone systems, our multi-drone approach maintains near-time-optimal performance with low collision rates. Real-world experiments validate our method, with two quadrotors using the same network as simulation achieving a maximum speed of 13.65 m/s and a maximum body rate of 13.4 rad/s in a 5.5 m * 5.5 m * 2.0 m space across various tracks, relying entirely on onboard computation.
TASL-Net: Tri-Attention Selective Learning Network for Intelligent Diagnosis of Bimodal Ultrasound Video
Sep 03, 2024In the intelligent diagnosis of bimodal (gray-scale and contrast-enhanced) ultrasound videos, medical domain knowledge such as the way sonographers browse videos, the particular areas they emphasize, and the features they pay special attention to, plays a decisive role in facilitating precise diagnosis. Embedding medical knowledge into the deep learning network can not only enhance performance but also boost clinical confidence and reliability of the network. However, it is an intractable challenge to automatically focus on these person- and disease-specific features in videos and to enable networks to encode bimodal information comprehensively and efficiently. This paper proposes a novel Tri-Attention Selective Learning Network (TASL-Net) to tackle this challenge and automatically embed three types of diagnostic attention of sonographers into a mutual transformer framework for intelligent diagnosis of bimodal ultrasound videos. Firstly, a time-intensity-curve-based video selector is designed to mimic the temporal attention of sonographers, thus removing a large amount of redundant information while improving computational efficiency of TASL-Net. Then, to introduce the spatial attention of the sonographers for contrast-enhanced video analysis, we propose the earliest-enhanced position detector based on structural similarity variation, on which the TASL-Net is made to focus on the differences of perfusion variation inside and outside the lesion. Finally, by proposing a mutual encoding strategy that combines convolution and transformer, TASL-Net possesses bimodal attention to structure features on gray-scale videos and to perfusion variations on contrast-enhanced videos. These modules work collaboratively and contribute to superior performance. We conduct a detailed experimental validation of TASL-Net's performance on three datasets, including lung, breast, and liver.
FlowTrack: Point-level Flow Network for 3D Single Object Tracking
Jul 02, 2024



3D single object tracking (SOT) is a crucial task in fields of mobile robotics and autonomous driving. Traditional motion-based approaches achieve target tracking by estimating the relative movement of target between two consecutive frames. However, they usually overlook local motion information of the target and fail to exploit historical frame information effectively. To overcome the above limitations, we propose a point-level flow method with multi-frame information for 3D SOT task, called FlowTrack. Specifically, by estimating the flow for each point in the target, our method could capture the local motion details of target, thereby improving the tracking performance. At the same time, to handle scenes with sparse points, we present a learnable target feature as the bridge to efficiently integrate target information from past frames. Moreover, we design a novel Instance Flow Head to transform dense point-level flow into instance-level motion, effectively aggregating local motion information to obtain global target motion. Finally, our method achieves competitive performance with improvements of 5.9% on the KITTI dataset and 2.9% on NuScenes. The code will be made publicly available soon.
Causal Distillation for Alleviating Performance Heterogeneity in Recommender Systems
May 31, 2024



Recommendation performance usually exhibits a long-tail distribution over users -- a small portion of head users enjoy much more accurate recommendation services than the others. We reveal two sources of this performance heterogeneity problem: the uneven distribution of historical interactions (a natural source); and the biased training of recommender models (a model source). As addressing this problem cannot sacrifice the overall performance, a wise choice is to eliminate the model bias while maintaining the natural heterogeneity. The key to debiased training lies in eliminating the effect of confounders that influence both the user's historical behaviors and the next behavior. The emerging causal recommendation methods achieve this by modeling the causal effect between user behaviors, however potentially neglect unobserved confounders (\eg, friend suggestions) that are hard to measure in practice. To address unobserved confounders, we resort to the front-door adjustment (FDA) in causal theory and propose a causal multi-teacher distillation framework (CausalD). FDA requires proper mediators in order to estimate the causal effects of historical behaviors on the next behavior. To achieve this, we equip CausalD with multiple heterogeneous recommendation models to model the mediator distribution. Then, the causal effect estimated by FDA is the expectation of recommendation prediction over the mediator distribution and the prior distribution of historical behaviors, which is technically achieved by multi-teacher ensemble. To pursue efficient inference, CausalD further distills multiple teachers into one student model to directly infer the causal effect for making recommendations.