 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMSI-Video-Bench: A Holistic Benchmark for Video-Based Spatial Intelligence
Dec 11, 2025Spatial understanding over continuous visual input is crucial for MLLMs to evolve into general-purpose assistants in physical environments. Yet there is still no comprehensive benchmark that holistically assesses the progress toward this goal. In this work, we introduce MMSI-Video-Bench, a fully human-annotated benchmark for video-based spatial intelligence in MLLMs. It operationalizes a four-level framework, Perception, Planning, Prediction, and Cross-Video Reasoning, through 1,106 questions grounded in 1,278 clips from 25 datasets and in-house videos. Each item is carefully designed and reviewed by 3DV experts with explanatory rationales to ensure precise, unambiguous grounding. Leveraging its diverse data sources and holistic task coverage, MMSI-Video-Bench also supports three domain-oriented sub-benchmarks (Indoor Scene Perception Bench, Robot Bench and Grounding Bench) for targeted capability assessment. We evaluate 25 strong open-source and proprietary MLLMs, revealing a striking human--AI gap: many models perform near chance, and the best reasoning model lags humans by nearly 60%. We further find that spatially fine-tuned models still fail to generalize effectively on our benchmark. Fine-grained error analysis exposes systematic failures in geometric reasoning, motion grounding, long-horizon prediction, and cross-video correspondence. We also show that typical frame-sampling strategies transfer poorly to our reasoning-intensive benchmark, and that neither 3D spatial cues nor chain-of-thought prompting yields meaningful gains. We expect our benchmark to establish a solid testbed for advancing video-based spatial intelligence.
CT-NeRF: Incremental Optimizing Neural Radiance Field and Poses with Complex Trajectory
Apr 23, 2024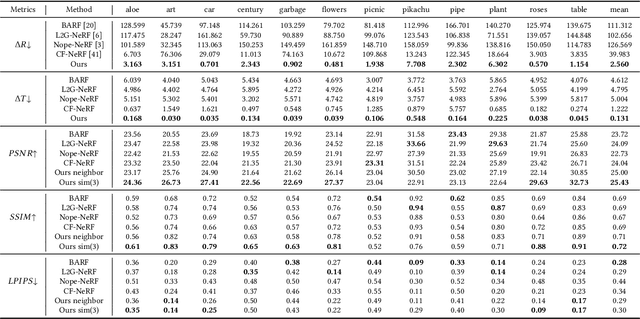
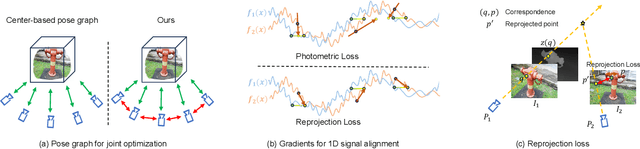
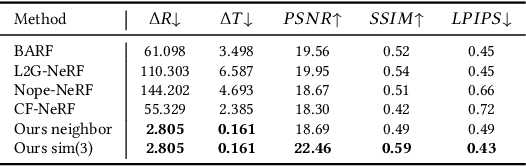
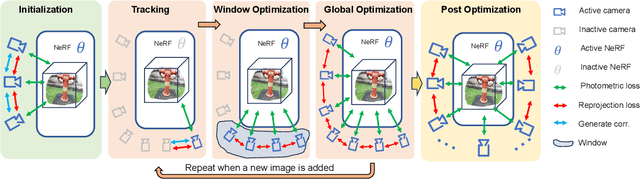
Neural radiance field (NeRF) has achieved impressive results in high-quality 3D scene reconstruction. However, NeRF heavily relies on precise camera poses. While recent works like BARF have introduced camera pose optimization within NeRF, their applicability is limited to simple trajectory scenes. Existing methods struggle while tackling complex trajectories involving large rotations. To address this limitation, we propose CT-NeRF, an incremental reconstruction optimization pipeline using only RGB images without pose and depth input. In this pipeline, we first propose a local-global bundle adjustment under a pose graph connecting neighboring frames to enforce the consistency between poses to escape the local minima caused by only pose consistency with the scene structure. Further, we instantiate the consistency between poses as a reprojected geometric image distance constraint resulting from pixel-level correspondences between input image pairs. Through the incremental reconstruction, CT-NeRF enables the recovery of both camera poses and scene structure and is capable of handling scenes with complex trajectories. We evaluate the performance of CT-NeRF on two real-world datasets, NeRFBuster and Free-Dataset, which feature complex trajectories. Results show CT-NeRF outperforms existing methods in novel view synthesis and pose estimation accuracy.
Autonomous Implicit Indoor Scene Reconstruction with Frontier Exploration
Apr 16, 2024



Implicit neural representations have demonstrated significant promise for 3D scene reconstruction. Recent works have extended their applications to autonomous implicit reconstruction through the Next Best View (NBV) based method. However, the NBV method cannot guarantee complete scene coverage and often necessitates extensive viewpoint sampling, particularly in complex scenes. In the paper, we propose to 1) incorporate frontier-based exploration tasks for global coverage with implicit surface uncertainty-based reconstruction tasks to achieve high-quality reconstruction. and 2) introduce a method to achieve implicit surface uncertainty using color uncertainty, which reduces the time needed for view selection. Further with these two tasks, we propose an adaptive strategy for switching modes in view path planning, to reduce time and maintain superior reconstruction quality. Our method exhibits the highest reconstruction quality among all planning methods and superior planning efficiency in methods involving reconstruction tasks. We deploy our method on a UAV and the results show that our method can plan multi-task views and reconstruct a scene with high quality.
* 7 pages
Seal-3D: Interactive Pixel-Level Editing for Neural Radiance Fields
Jul 27, 2023



With the popularity of implicit neural representations, or neural radiance fields (NeRF), there is a pressing need for editing methods to interact with the implicit 3D models for tasks like post-processing reconstructed scenes and 3D content creation. While previous works have explored NeRF editing from various perspectives, they are restricted in editing flexibility, quality, and speed, failing to offer direct editing response and instant preview. The key challenge is to conceive a locally editable neural representation that can directly reflect the editing instructions and update instantly. To bridge the gap, we propose a new interactive editing method and system for implicit representations, called Seal-3D, which allows users to edit NeRF models in a pixel-level and free manner with a wide range of NeRF-like backbone and preview the editing effects instantly. To achieve the effects, the challenges are addressed by our proposed proxy function mapping the editing instructions to the original space of NeRF models and a teacher-student training strategy with local pretraining and global finetuning. A NeRF editing system is built to showcase various editing types. Our system can achieve compelling editing effects with an interactive speed of about 1 second.
Efficient View Path Planning for Autonomous Implicit Reconstruction
Sep 27, 2022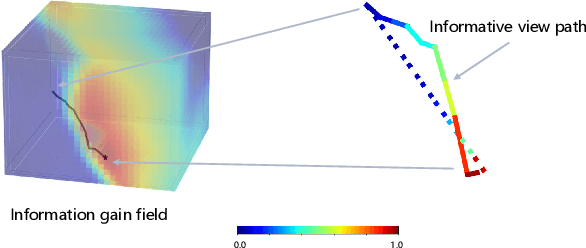
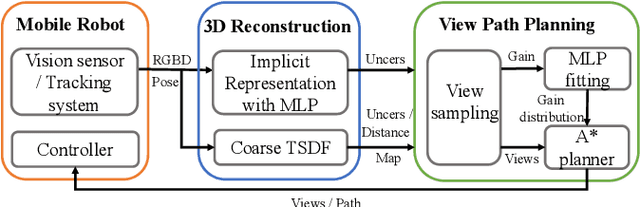


Implicit neural representations have shown promising potential for the 3D scene reconstruction. Recent work applies it to autonomous 3D reconstruction by learning information gain for view path planning. Effective as it is, the computation of the information gain is expensive, and compared with that using volumetric representations, collision checking using the implicit representation for a 3D point is much slower. In the paper, we propose to 1) leverage a neural network as an implicit function approximator for the information gain field and 2) combine the implicit fine-grained representation with coarse volumetric representations to improve efficiency. Further with the improved efficiency, we propose a novel informative path planning based on a graph-based planner. Our method demonstrates significant improvements in the reconstruction quality and planning efficiency compared with autonomous reconstructions with implicit and explicit representations. We deploy the method on a real UAV and the results show that our method can plan informative views and reconstruct a scene with high quality.
NeurAR: Neural Uncertainty for Autonomous 3D Reconstruction
Jul 22, 2022
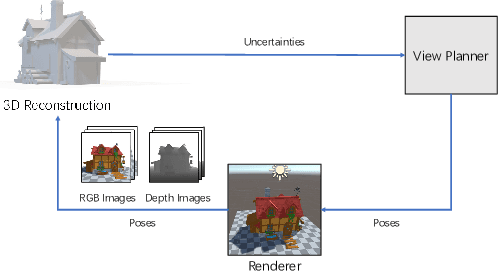
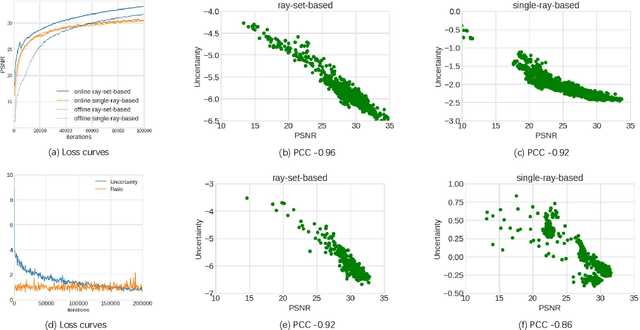

Implicit neural representations have shown compelling results in offline 3D reconstruction and also recently demonstrated the potential for online SLAM systems. However, applying them to autonomous 3D reconstruction, where robots are required to explore a scene and plan a view path for the reconstruction, has not been studied. In this paper, we explore for the first time the possibility of using implicit neural representations for autonomous 3D scene reconstruction by addressing two key challenges: 1) seeking a criterion to measure the quality of the candidate viewpoints for the view planning based on the new representations, and 2) learning the criterion from data that can generalize to different scenes instead of hand-crafting one. For the first challenge, a proxy of Peak Signal-to-Noise Ratio (PSNR) is proposed to quantify a viewpoint quality. The proxy is acquired by treating the color of a spatial point in a scene as a random variable under a Gaussian distribution rather than a deterministic one; the variance of the distribution quantifies the uncertainty of the reconstruction and composes the proxy. For the second challenge, the proxy is optimized jointly with the parameters of an implicit neural network for the scene. With the proposed view quality criterion, we can then apply the new representations to autonomous 3D reconstruction. Our method demonstrates significant improvements on various metrics for the rendered image quality and the geometry quality of the reconstructed 3D models when compared with variants using TSDF or reconstruction without view planning.