 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Discrimination to Generation: Knowledge Graph Completion with Generative Transformer
Feb 08, 2022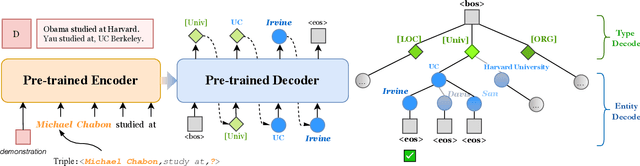

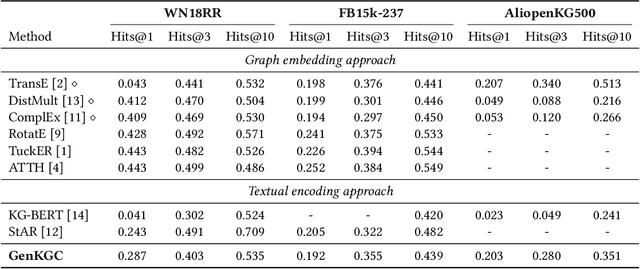
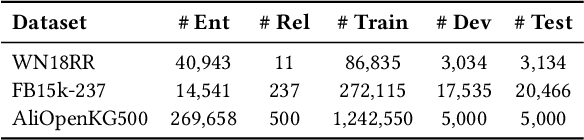
Knowledge graph completion aims to address the problem of extending a KG with missing triples. In this paper, we provide an approach GenKGC, which converts knowledge graph completion to sequence-to-sequence generation task with the pre-trained language model. We further introduce relation-guided demonstration and entity-aware hierarchical decoding for better representation learning and fast inference. Experimental results on three datasets show that our approach can obtain better or comparable performance than baselines and achieve faster inference speed compared with previous methods with pre-trained language models. We also release a new large-scale Chinese knowledge graph dataset AliopenKG500 for research purpose. Code and datasets are available in https://github.com/zjunlp/PromptKGC/tree/main/GenKGC.
Ontology-enhanced Prompt-tuning for Few-shot Learning
Jan 27, 2022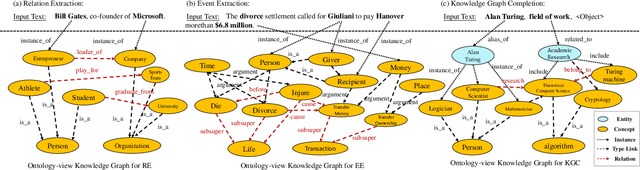
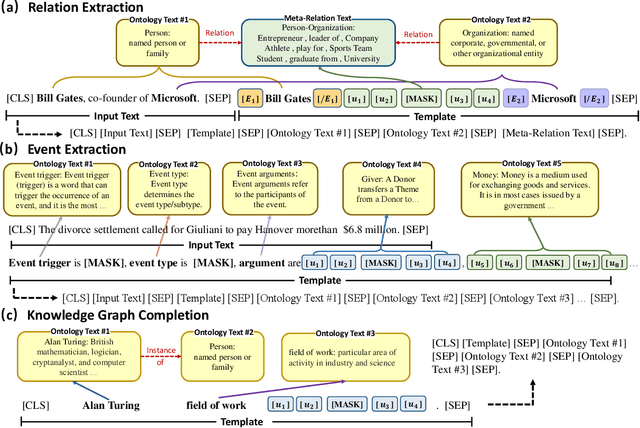
Few-shot Learning (FSL) is aimed to make predictions based on a limited number of samples. Structured data such as knowledge graphs and ontology libraries has been leveraged to benefit the few-shot setting in various tasks. However, the priors adopted by the existing methods suffer from challenging knowledge missing, knowledge noise, and knowledge heterogeneity, which hinder the performance for few-shot learning. In this study, we explore knowledge injection for FSL with pre-trained language models and propose ontology-enhanced prompt-tuning (OntoPrompt). Specifically, we develop the ontology transformation based on the external knowledge graph to address the knowledge missing issue, which fulfills and converts structure knowledge to text. We further introduce span-sensitive knowledge injection via a visible matrix to select informative knowledge to handle the knowledge noise issue. To bridge the gap between knowledge and text, we propose a collective training algorithm to optimize representations jointly. We evaluate our proposed OntoPrompt in three tasks, including relation extraction, event extraction, and knowledge graph completion, with eight datasets. Experimental results demonstrate that our approach can obtain better few-shot performance than baselines.
DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
Jan 24, 2022
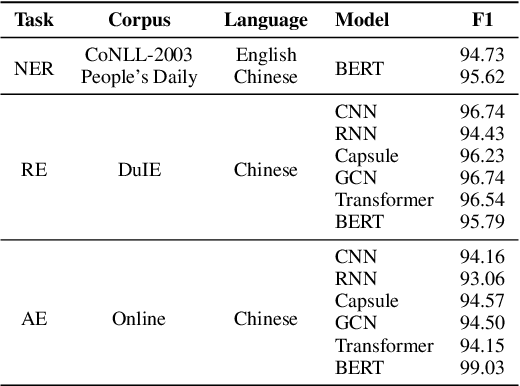
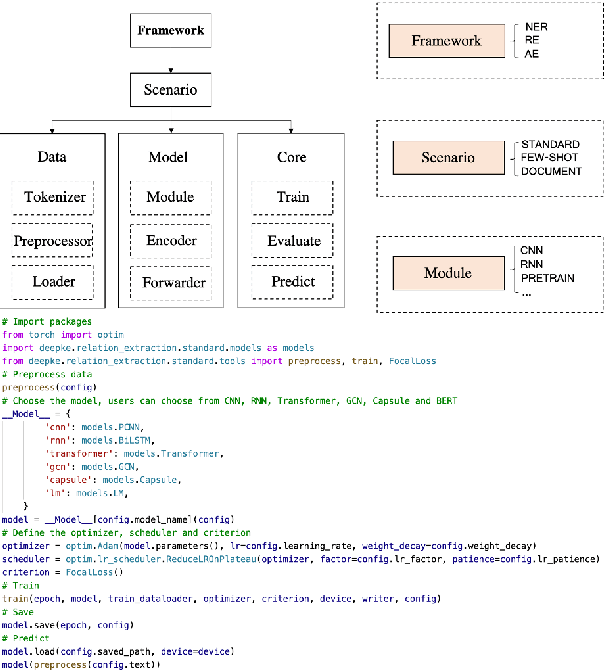
We present a new open-source and extensible knowledge extraction toolkit, called DeepKE (Deep learning based Knowledge Extraction), supporting standard fully supervised, low-resource few-shot and document-level scenarios. DeepKE implements various information extraction tasks, including named entity recognition, relation extraction and attribute extraction. With a unified framework, DeepKE allows developers and researchers to customize datasets and models to extract information from unstructured texts according to their requirements. Specifically, DeepKE not only provides various functional modules and model implementation for different tasks and scenarios but also organizes all components by consistent frameworks to maintain sufficient modularity and extensibility. Besides, we present an online platform in http://deepke.zjukg.cn/ for real-time extraction of various tasks. DeepKE has been equipped with Google Colab tutorials and comprehensive documents for beginners. We release the source code at https://github.com/zjunlp/DeepKE, with a demo video.
OntoProtein: Protein Pretraining With Gene Ontology Embedding
Jan 23, 2022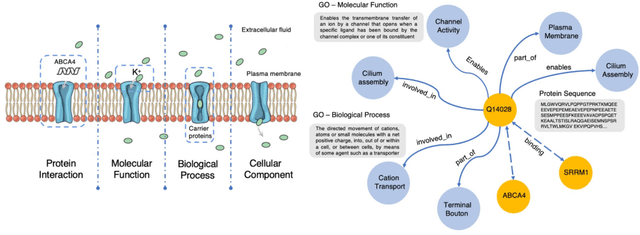
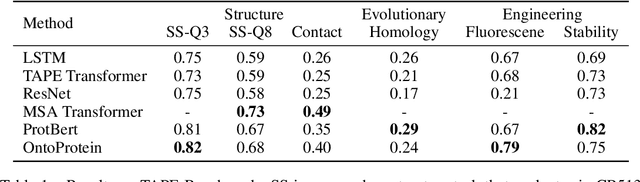
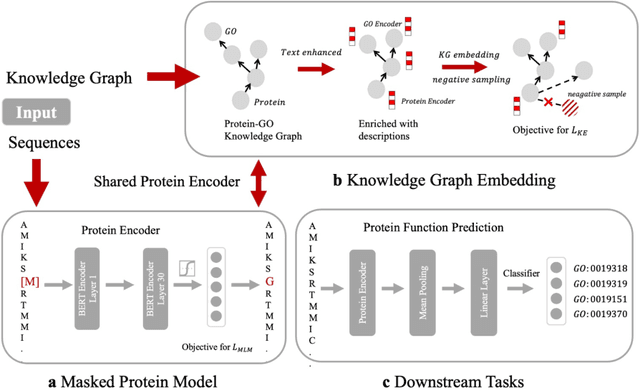
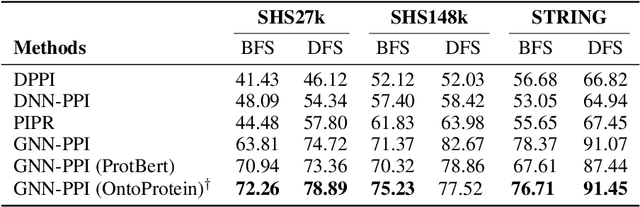
Self-supervised protein language models have proved their effectiveness in learning the proteins representations. With the increasing computational power, current protein language models pre-trained with millions of diverse sequences can advance the parameter scale from million-level to billion-level and achieve remarkable improvement. However, those prevailing approaches rarely consider incorporating knowledge graphs (KGs), which can provide rich structured knowledge facts for better protein representations. We argue that informative biology knowledge in KGs can enhance protein representation with external knowledge. In this work, we propose OntoProtein, the first general framework that makes use of structure in GO (Gene Ontology) into protein pre-training models. We construct a novel large-scale knowledge graph that consists of GO and its related proteins, and gene annotation texts or protein sequences describe all nodes in the graph. We propose novel contrastive learning with knowledge-aware negative sampling to jointly optimize the knowledge graph and protein embedding during pre-training. Experimental results show that OntoProtein can surpass state-of-the-art methods with pre-trained protein language models in TAPE benchmark and yield better performance compared with baselines in protein-protein interaction and protein function prediction. Code and datasets are available in https://github.com/zjunlp/OntoProtein.
Reasoning Through Memorization: Nearest Neighbor Knowledge Graph Embeddings
Jan 14, 2022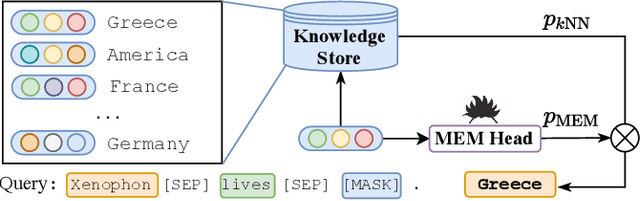
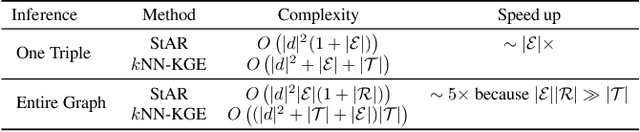
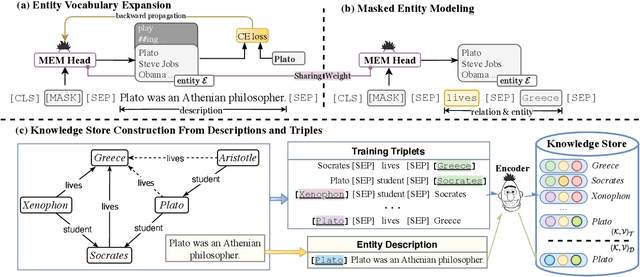
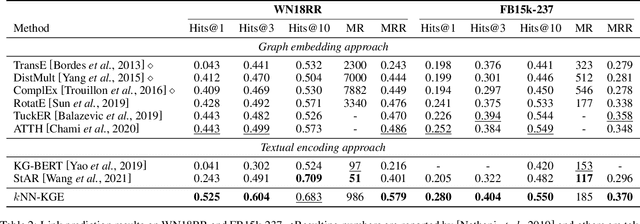
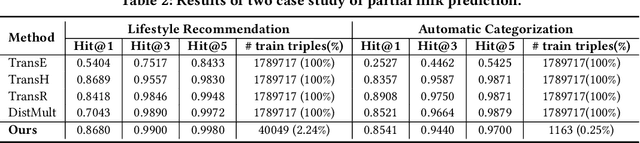
Previous knowledge graph embedding approaches usually map entities to representations and utilize score functions to predict the target entities, yet they struggle to reason rare or emerging unseen entities. In this paper, we propose kNN-KGE, a new knowledge graph embedding approach, by linearly interpolating its entity distribution with k-nearest neighbors. We compute the nearest neighbors based on the distance in the entity embedding space from the knowledge store. Our approach can allow rare or emerging entities to be memorized explicitly rather than implicitly in model parameters. Experimental results demonstrate that our approach can improve inductive and transductive link prediction results and yield better performance for low-resource settings with only a few triples, which might be easier to reason via explicit memory.
Knowledge Graph Embedding in E-commerce Applications: Attentive Reasoning, Explanations, and Transferable Rules
Dec 16, 2021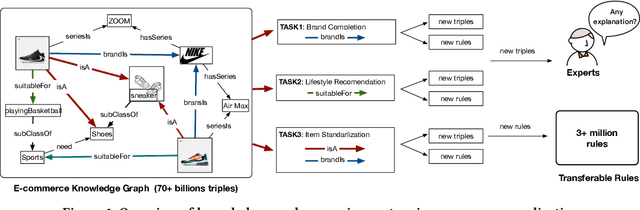
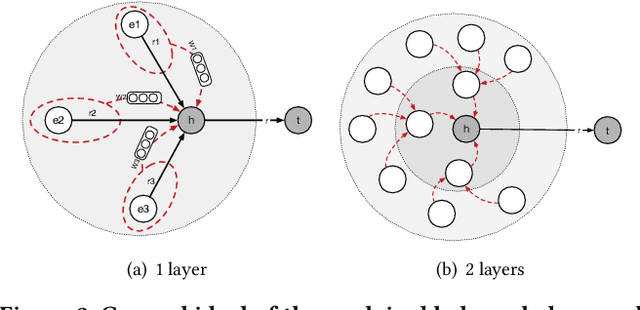
Knowledge Graphs (KGs), representing facts as triples, have been widely adopted in many applications. Reasoning tasks such as link prediction and rule induction are important for the development of KGs. Knowledge Graph Embeddings (KGEs) embedding entities and relations of a KG into continuous vector spaces, have been proposed for these reasoning tasks and proven to be efficient and robust. But the plausibility and feasibility of applying and deploying KGEs in real-work applications has not been well-explored. In this paper, we discuss and report our experiences of deploying KGEs in a real domain application: e-commerce. We first identity three important desiderata for e-commerce KG systems: 1) attentive reasoning, reasoning over a few target relations of more concerns instead of all; 2) explanation, providing explanations for a prediction to help both users and business operators understand why the prediction is made; 3) transferable rules, generating reusable rules to accelerate the deployment of a KG to new systems. While non existing KGE could meet all these desiderata, we propose a novel one, an explainable knowledge graph attention network that make prediction through modeling correlations between triples rather than purely relying on its head entity, relation and tail entity embeddings. It could automatically selects attentive triples for prediction and records the contribution of them at the same time, from which explanations could be easily provided and transferable rules could be efficiently produced. We empirically show that our method is capable of meeting all three desiderata in our e-commerce application and outperform typical baselines on datasets from real domain applications.
LOGEN: Few-shot Logical Knowledge-Conditioned Text Generation with Self-training
Dec 02, 2021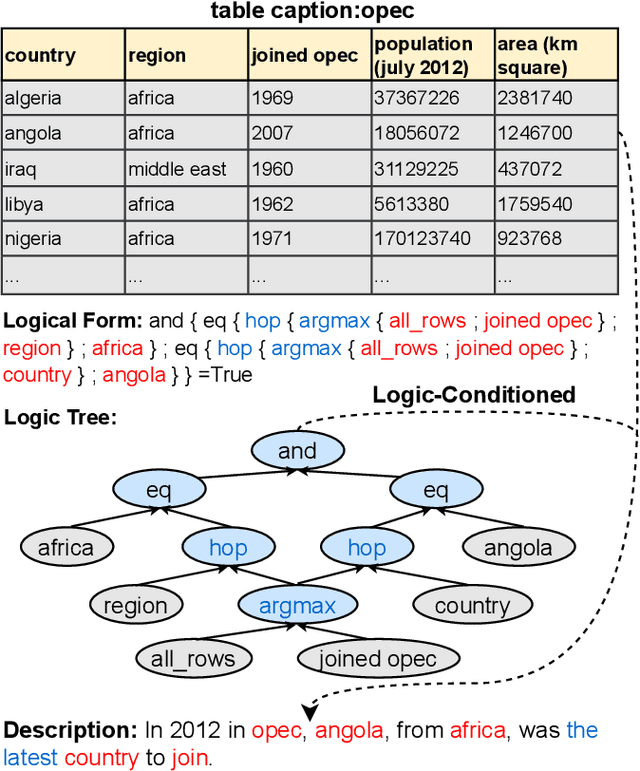
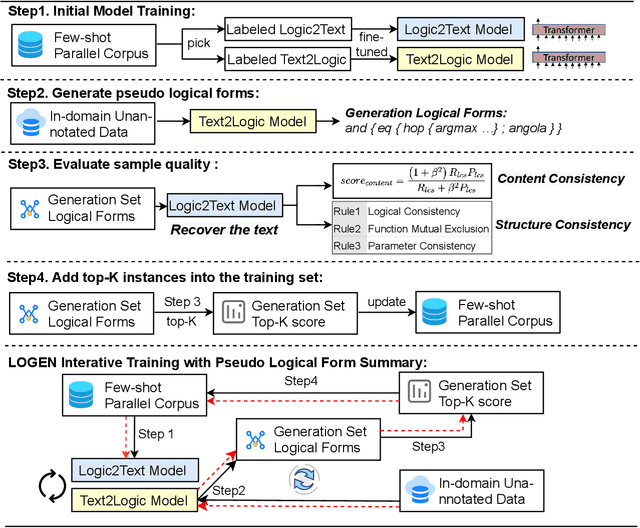
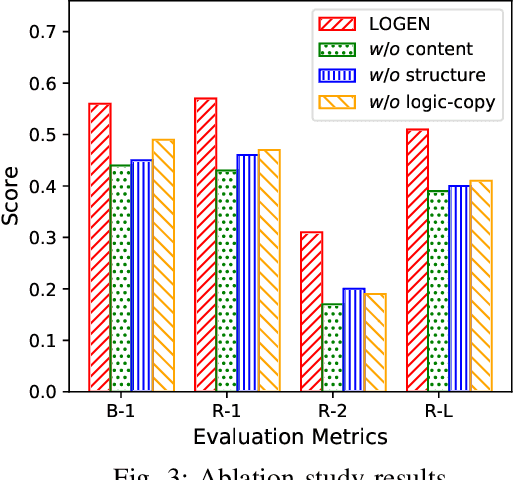

Natural language generation from structured data mainly focuses on surface-level descriptions, suffering from uncontrollable content selection and low fidelity. Previous works leverage logical forms to facilitate logical knowledge-conditioned text generation. Though achieving remarkable progress, they are data-hungry, which makes the adoption for real-world applications challenging with limited data. To this end, this paper proposes a unified framework for logical knowledge-conditioned text generation in the few-shot setting. With only a few seeds logical forms (e.g., 20/100 shot), our approach leverages self-training and samples pseudo logical forms based on content and structure consistency. Experimental results demonstrate that our approach can obtain better few-shot performance than baselines.
Molecular Contrastive Learning with Chemical Element Knowledge Graph
Dec 01, 2021
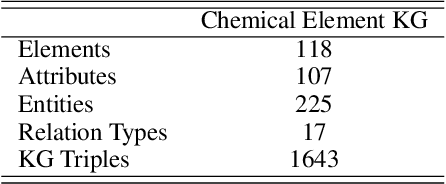
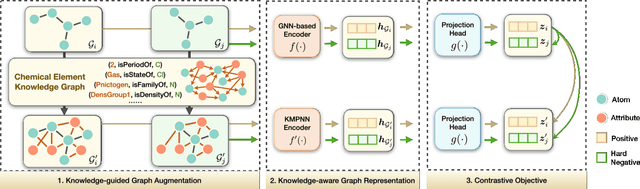
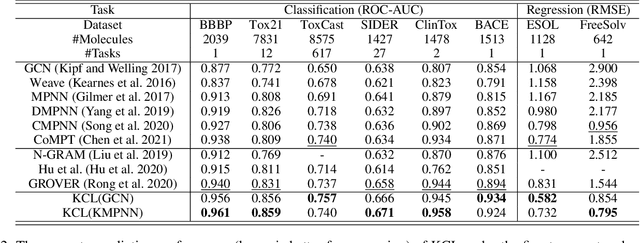
Molecular representation learning contributes to multiple downstream tasks such as molecular property prediction and drug design. To properly represent molecules, graph contrastive learning is a promising paradigm as it utilizes self-supervision signals and has no requirements for human annotations. However, prior works fail to incorporate fundamental domain knowledge into graph semantics and thus ignore the correlations between atoms that have common attributes but are not directly connected by bonds. To address these issues, we construct a Chemical Element Knowledge Graph (KG) to summarize microscopic associations between elements and propose a novel Knowledge-enhanced Contrastive Learning (KCL) framework for molecular representation learning. KCL framework consists of three modules. The first module, knowledge-guided graph augmentation, augments the original molecular graph based on the Chemical Element KG. The second module, knowledge-aware graph representation, extracts molecular representations with a common graph encoder for the original molecular graph and a Knowledge-aware Message Passing Neural Network (KMPNN) to encode complex information in the augmented molecular graph. The final module is a contrastive objective, where we maximize agreement between these two views of molecular graphs. Extensive experiments demonstrated that KCL obtained superior performances against state-of-the-art baselines on eight molecular datasets. Visualization experiments properly interpret what KCL has learned from atoms and attributes in the augmented molecular graphs. Our codes and data are available in supplementary materials.
Learning to Ask for Data-Efficient Event Argument Extraction
Oct 01, 2021
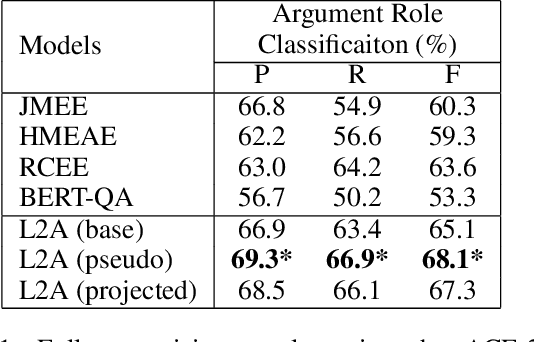
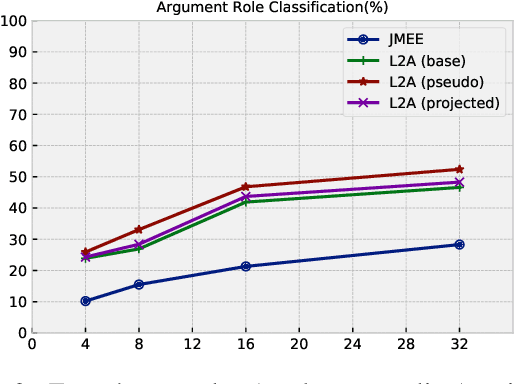
Event argument extraction (EAE) is an important task for information extraction to discover specific argument roles. In this study, we cast EAE as a question-based cloze task and empirically analyze fixed discrete token template performance. As generating human-annotated question templates is often time-consuming and labor-intensive, we further propose a novel approach called "Learning to Ask," which can learn optimized question templates for EAE without human annotations. Experiments using the ACE-2005 dataset demonstrate that our method based on optimized questions achieves state-of-the-art performance in both the few-shot and supervised settings.
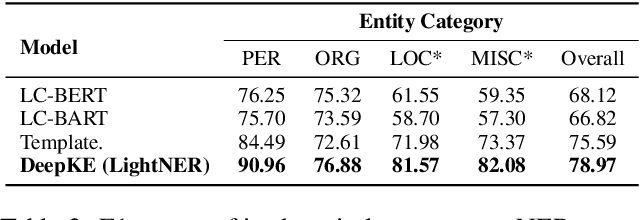
LightNER: A Lightweight Generative Framework with Prompt-guided Attention for Low-resource NER
Sep 09, 2021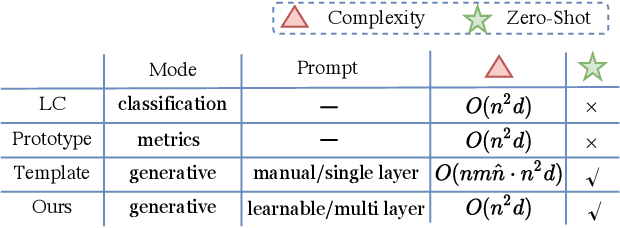
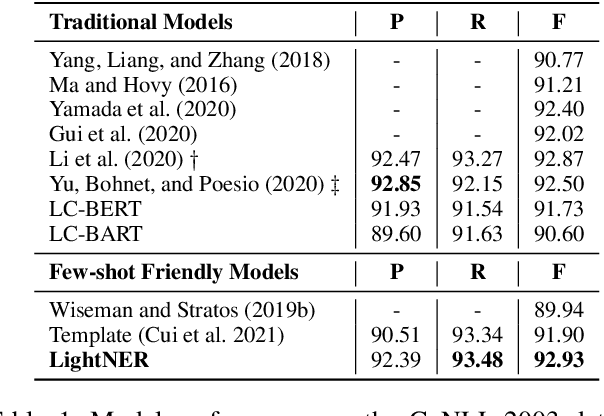
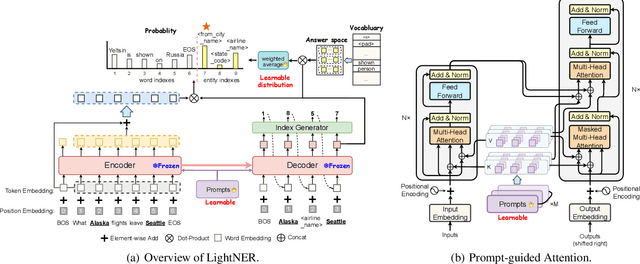
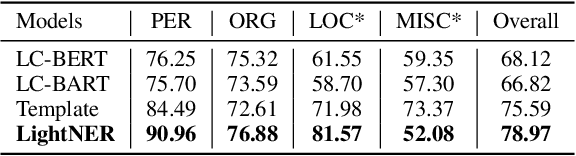
Most existing NER methods rely on extensive labeled data for model training, which struggles in the low-resource scenarios with limited training data. Recently, prompt-tuning methods for pre-trained language models have achieved remarkable performance in few-shot learning by exploiting prompts as task guidance to reduce the gap between training progress and downstream tuning. Inspired by prompt learning, we propose a novel lightweight generative framework with prompt-guided attention for low-resource NER (LightNER). Specifically, we construct the semantic-aware answer space of entity categories for prompt learning to generate the entity span sequence and entity categories without any label-specific classifiers. We further propose prompt-guided attention by incorporating continuous prompts into the self-attention layer to re-modulate the attention and adapt pre-trained weights. Note that we only tune those continuous prompts with the whole parameter of the pre-trained language model fixed, thus, making our approach lightweight and flexible for low-resource scenarios and can better transfer knowledge across domains. Experimental results show that LightNER can obtain comparable performance in the standard supervised setting and outperform strong baselines in low-resource settings by tuning only a small part of the parameters.