 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaS2S: Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction
Nov 11, 2025Speech-to-Speech (S2S) models have shown promising dialogue capabilities, but their ability to handle paralinguistic cues--such as emotion, tone, and speaker attributes--and to respond appropriately in both content and style remains underexplored. Progress is further hindered by the scarcity of high-quality and expressive demonstrations. To address this, we introduce a novel reinforcement learning (RL) framework for paralinguistic-aware S2S, ParaS2S, which evaluates and optimizes both content and speaking style directly at the waveform level. We first construct ParaS2SBench, a benchmark comprehensively evaluates S2S models' output for content and style appropriateness from diverse and challenging input queries. It scores the fitness of input-output pairs and aligns well with human judgments, serving as an automatic judge for model outputs. With this scalable scoring feedback, we enable the model to explore and learn from diverse unlabeled speech via Group Relative Policy Optimization (GRPO). Experiments show that existing S2S models fail to respond appropriately to paralinguistic attributes, performing no better than pipeline-based baselines. Our RL approach achieves a 11% relative improvement in response content and style's appropriateness on ParaS2SBench over supervised fine-tuning (SFT), surpassing all prior models while requiring substantially fewer warm-up annotations than pure SFT.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
A Large-Scale Evaluation of Speech Foundation Models
Apr 15, 2024The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
SUPERB @ SLT 2022: Challenge on Generalization and Efficiency of Self-Supervised Speech Representation Learning
Oct 16, 2022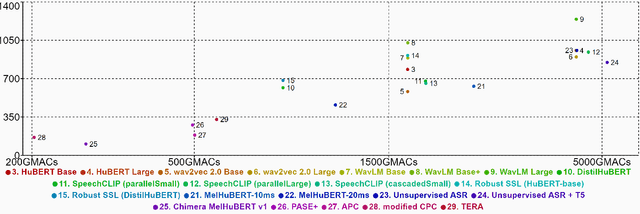
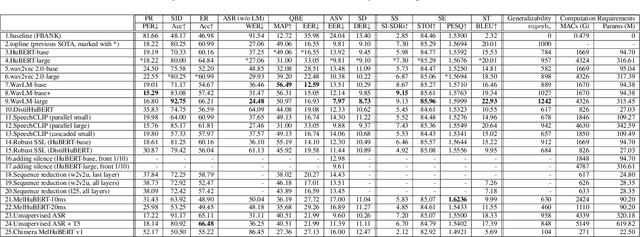
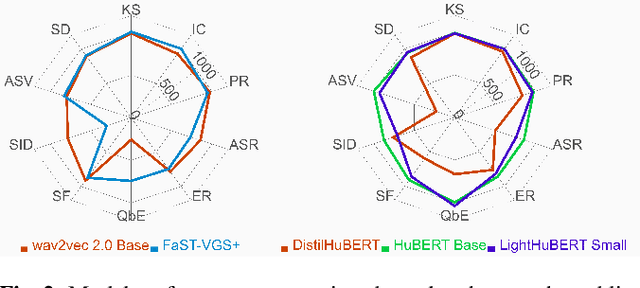
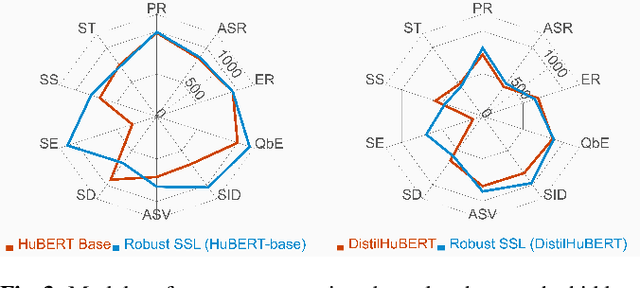
We present the SUPERB challenge at SLT 2022, which aims at learning self-supervised speech representation for better performance, generalization, and efficiency. The challenge builds upon the SUPERB benchmark and implements metrics to measure the computation requirements of self-supervised learning (SSL) representation and to evaluate its generalizability and performance across the diverse SUPERB tasks. The SUPERB benchmark provides comprehensive coverage of popular speech processing tasks, from speech and speaker recognition to audio generation and semantic understanding. As SSL has gained interest in the speech community and showed promising outcomes, we envision the challenge to uplevel the impact of SSL techniques by motivating more practical designs of techniques beyond task performance. We summarize the results of 14 submitted models in this paper. We also discuss the main findings from those submissions and the future directions of SSL research.
DUAL: Discrete Spoken Unit Adaptive Learning for Textless Spoken Question Answering
Mar 26, 2022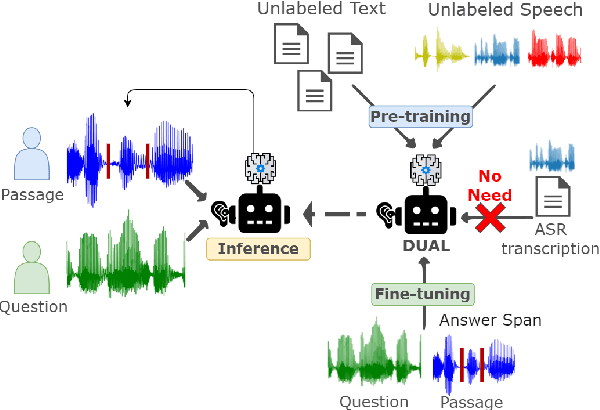
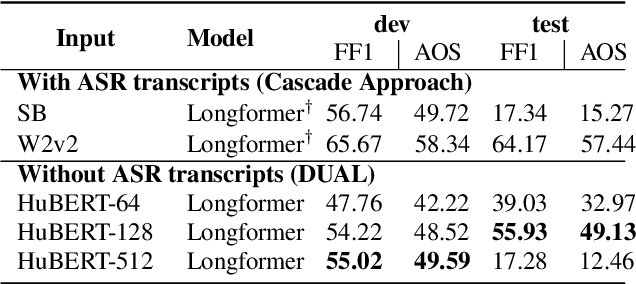
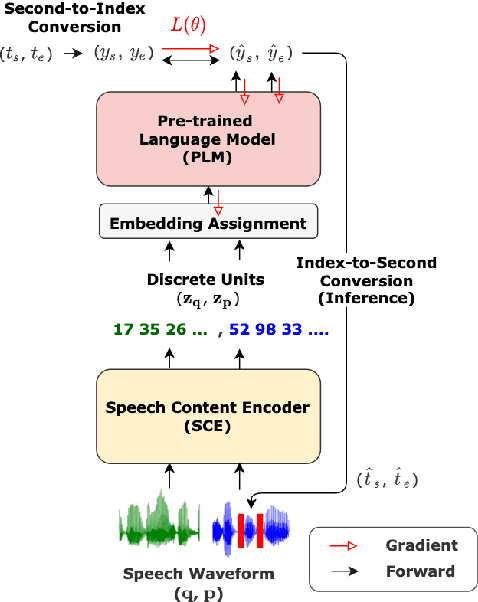
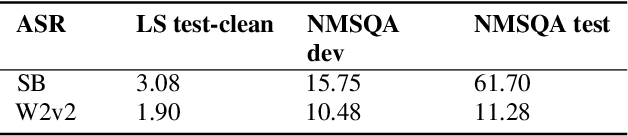
Spoken Question Answering (SQA) is to find the answer from a spoken document given a question, which is crucial for personal assistants when replying to the queries from the users. Existing SQA methods all rely on Automatic Speech Recognition (ASR) transcripts. Not only does ASR need to be trained with massive annotated data that are time and cost-prohibitive to collect for low-resourced languages, but more importantly, very often the answers to the questions include name entities or out-of-vocabulary words that cannot be recognized correctly. Also, ASR aims to minimize recognition errors equally over all words, including many function words irrelevant to the SQA task. Therefore, SQA without ASR transcripts (textless) is always highly desired, although known to be very difficult. This work proposes Discrete Spoken Unit Adaptive Learning (DUAL), leveraging unlabeled data for pre-training and fine-tuned by the SQA downstream task. The time intervals of spoken answers can be directly predicted from spoken documents. We also release a new SQA benchmark corpus, NMSQA, for data with more realistic scenarios. We empirically showed that DUAL yields results comparable to those obtained by cascading ASR and text QA model and robust to real-world data. Our code and model will be open-sourced.
Investigating self-supervised learning for speech enhancement and separation
Mar 15, 2022
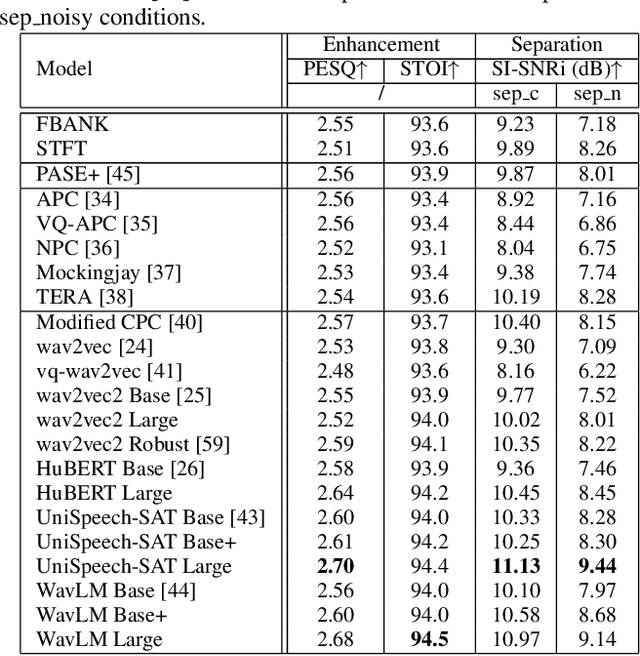
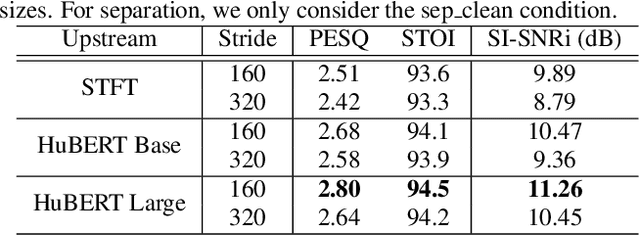
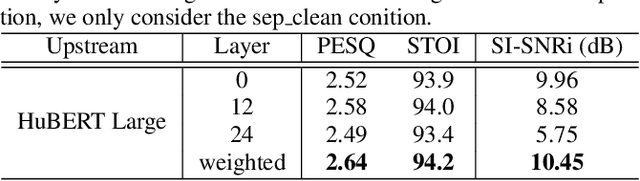
Speech enhancement and separation are two fundamental tasks for robust speech processing. Speech enhancement suppresses background noise while speech separation extracts target speech from interfering speakers. Despite a great number of supervised learning-based enhancement and separation methods having been proposed and achieving good performance, studies on applying self-supervised learning (SSL) to enhancement and separation are limited. In this paper, we evaluate 13 SSL upstream methods on speech enhancement and separation downstream tasks. Our experimental results on Voicebank-DEMAND and Libri2Mix show that some SSL representations consistently outperform baseline features including the short-time Fourier transform (STFT) magnitude and log Mel filterbank (FBANK). Furthermore, we analyze the factors that make existing SSL frameworks difficult to apply to speech enhancement and separation and discuss the representation properties desired for both tasks. Our study is included as the official speech enhancement and separation downstreams for SUPERB.
SUPERB-SG: Enhanced Speech processing Universal PERformance Benchmark for Semantic and Generative Capabilities
Mar 14, 2022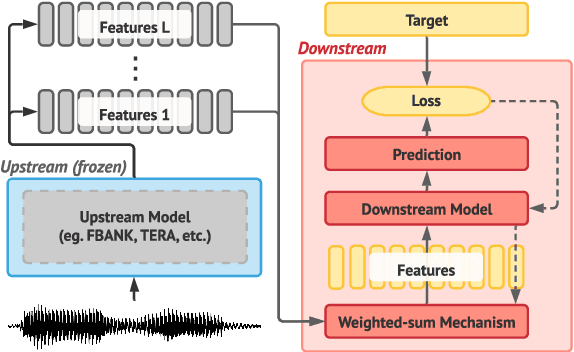
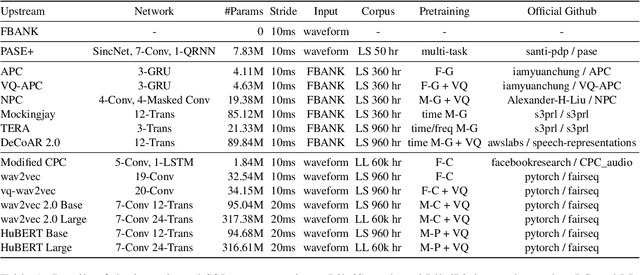
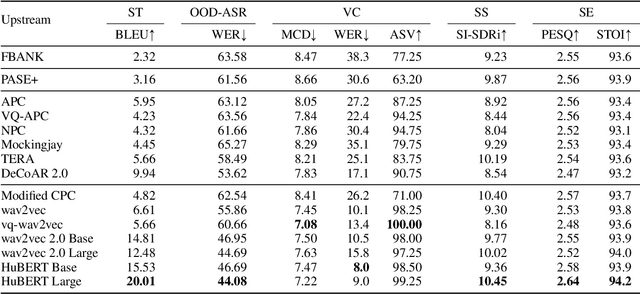
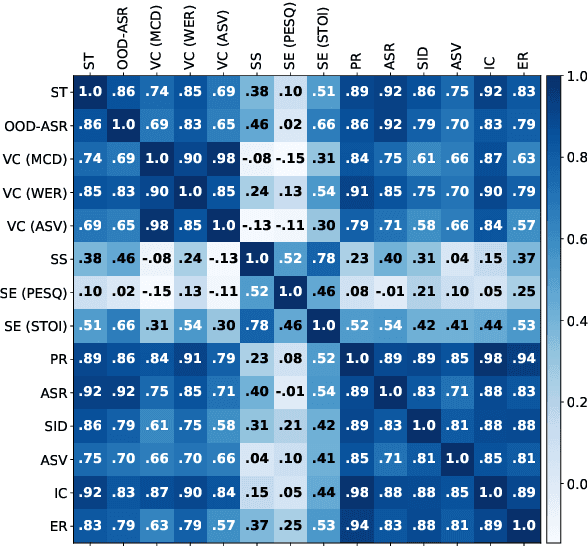
Transfer learning has proven to be crucial in advancing the state of speech and natural language processing research in recent years. In speech, a model pre-trained by self-supervised learning transfers remarkably well on multiple tasks. However, the lack of a consistent evaluation methodology is limiting towards a holistic understanding of the efficacy of such models. SUPERB was a step towards introducing a common benchmark to evaluate pre-trained models across various speech tasks. In this paper, we introduce SUPERB-SG, a new benchmark focused on evaluating the semantic and generative capabilities of pre-trained models by increasing task diversity and difficulty over SUPERB. We use a lightweight methodology to test the robustness of representations learned by pre-trained models under shifts in data domain and quality across different types of tasks. It entails freezing pre-trained model parameters, only using simple task-specific trainable heads. The goal is to be inclusive of all researchers, and encourage efficient use of computational resources. We also show that the task diversity of SUPERB-SG coupled with limited task supervision is an effective recipe for evaluating the generalizability of model representation.
Speech Representation Learning Through Self-supervised Pretraining And Multi-task Finetuning
Oct 18, 2021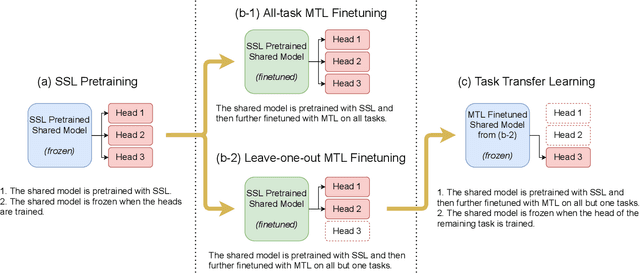
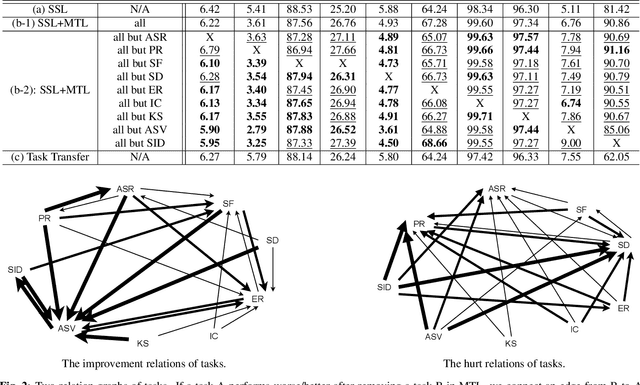
Speech representation learning plays a vital role in speech processing. Among them, self-supervised learning (SSL) has become an important research direction. It has been shown that an SSL pretraining model can achieve excellent performance in various downstream tasks of speech processing. On the other hand, supervised multi-task learning (MTL) is another representation learning paradigm, which has been proven effective in computer vision (CV) and natural language processing (NLP). However, there is no systematic research on the general representation learning model trained by supervised MTL in speech processing. In this paper, we show that MTL finetuning can further improve SSL pretraining. We analyze the generalizability of supervised MTL finetuning to examine if the speech representation learned by MTL finetuning can generalize to unseen new tasks.
An Exploration of Self-Supervised Pretrained Representations for End-to-End Speech Recognition
Oct 09, 2021
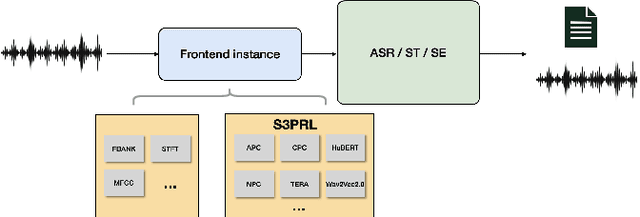
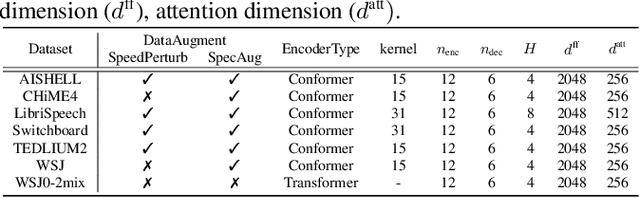
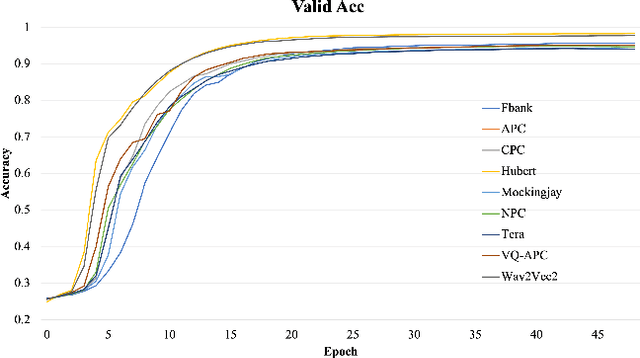
Self-supervised pretraining on speech data has achieved a lot of progress. High-fidelity representation of the speech signal is learned from a lot of untranscribed data and shows promising performance. Recently, there are several works focusing on evaluating the quality of self-supervised pretrained representations on various tasks without domain restriction, e.g. SUPERB. However, such evaluations do not provide a comprehensive comparison among many ASR benchmark corpora. In this paper, we focus on the general applications of pretrained speech representations, on advanced end-to-end automatic speech recognition (E2E-ASR) models. We select several pretrained speech representations and present the experimental results on various open-source and publicly available corpora for E2E-ASR. Without any modification of the back-end model architectures or training strategy, some of the experiments with pretrained representations, e.g., WSJ, WSJ0-2mix with HuBERT, reach or outperform current state-of-the-art (SOTA) recognition performance. Moreover, we further explore more scenarios for whether the pretraining representations are effective, such as the cross-language or overlapped speech. The scripts, configuratons and the trained models have been released in ESPnet to let the community reproduce our experiments and improve them.