 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Image Classification for Deep Representation Learning
Jun 20, 2020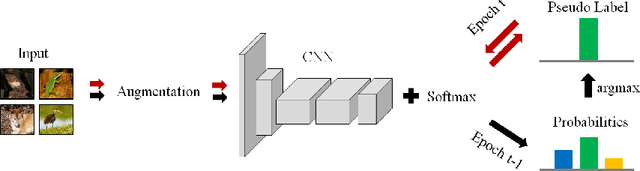
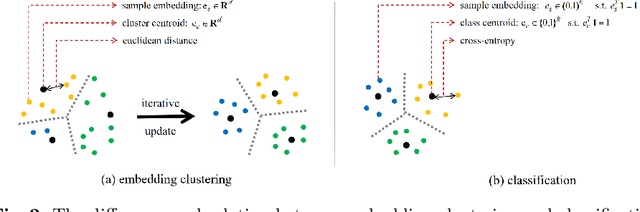
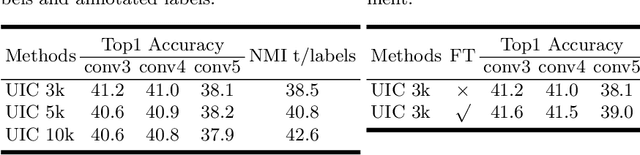

Deep clustering against self-supervised learning is a very important and promising direction for unsupervised visual representation learning since it requires little domain knowledge to design pretext tasks. However, the key component, embedding clustering, limits its extension to the extremely large-scale dataset due to its prerequisite to save the global latent embedding of the entire dataset. In this work, we aim to make this framework more simple and elegant without performance decline. We propose an unsupervised image classification framework without using embedding clustering, which is very similar to standard supervised training manner. For detailed interpretation, we further analyze its relation with deep clustering and contrastive learning. Extensive experiments on ImageNet dataset have been conducted to prove the effectiveness of our method. Furthermore, the experiments on transfer learning benchmarks have verified its generalization to other downstream tasks, including multi-label image classification, object detection, semantic segmentation and few-shot image classification.
TRIE: End-to-End Text Reading and Information Extraction for Document Understanding
May 27, 2020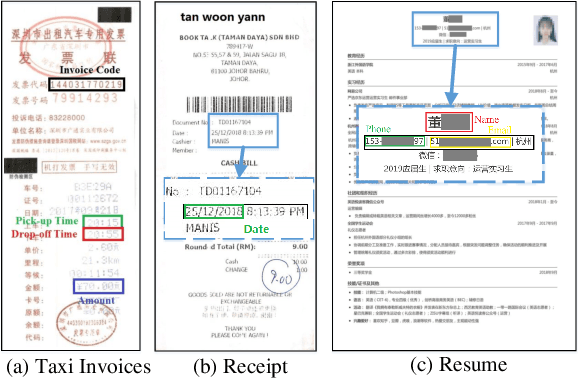
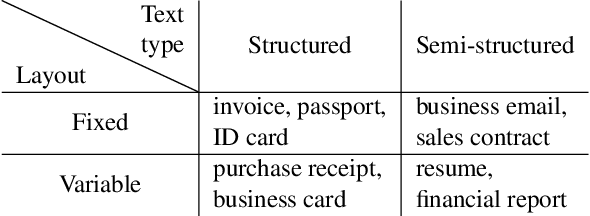
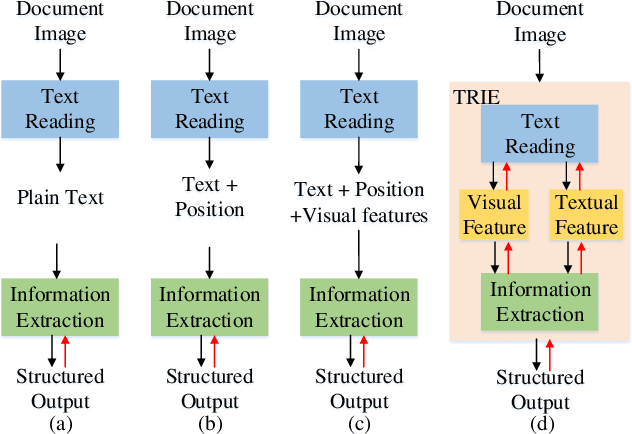
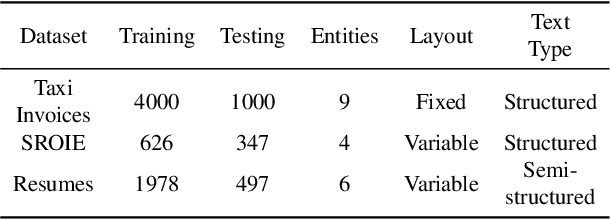
Since real-world ubiquitous documents (e.g., invoices, tickets, resumes and leaflets) contain rich information, automatic document image understanding has become a hot topic. Most existing works decouple the problem into two separate tasks, (1) text reading for detecting and recognizing texts in the images and (2) information extraction for analyzing and extracting key elements from previously extracted plain text. However, they mainly focus on improving information extraction task, while neglecting the fact that text reading and information extraction are mutually correlated. In this paper, we propose a unified end-to-end text reading and information extraction network, where the two tasks can reinforce each other. Specifically, the multimodal visual and textual features of text reading are fused for information extraction and in turn, the semantics in information extraction contribute to the optimization of text reading. On three real-world datasets with diverse document images (from fixed layout to variable layout, from structured text to semi-structured text), our proposed method significantly outperforms the state-of-the-art methods in both efficiency and accuracy.
SPIN: Structure-Preserving Inner Offset Network for Scene Text Recognition
May 27, 2020
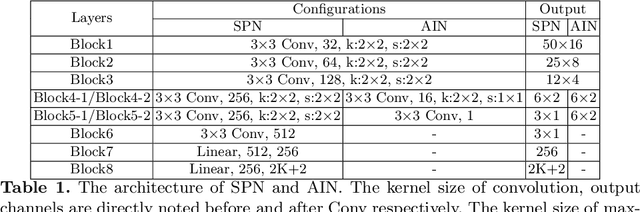
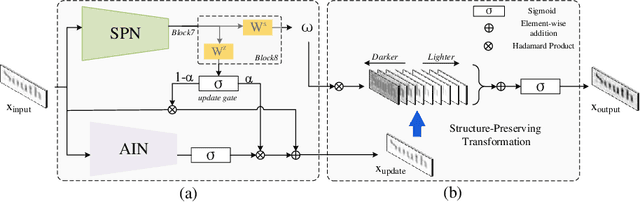
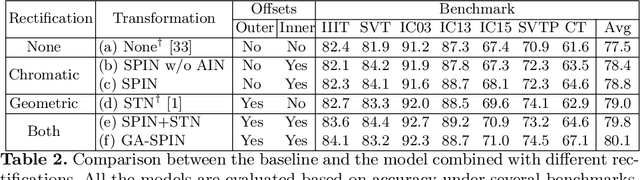
Arbitrary text appearance poses a great challenge in scene text recognition tasks. Existing works mostly handle with the problem in consideration of the shape distortion, including perspective distortions, line curvature or other style variations. Therefore, methods based on spatial transformers are extensively studied. However, chromatic difficulties in complex scenes have not been paid much attention on. In this work, we introduce a new learnable geometric-unrelated module, the Structure-Preserving Inner Offset Network (SPIN), which allows the color manipulation of source data within the network. This differentiable module can be inserted before any recognition architecture to ease the downstream tasks, giving neural networks the ability to actively transform input intensity rather than the existing spatial rectification. It can also serve as a complementary module to known spatial transformations and work in both independent and collaborative ways with them. Extensive experiments show that the use of SPIN results in a significant improvement on multiple text recognition benchmarks compared to the state-of-the-arts.
Object-QA: Towards High Reliable Object Quality Assessment
May 27, 2020
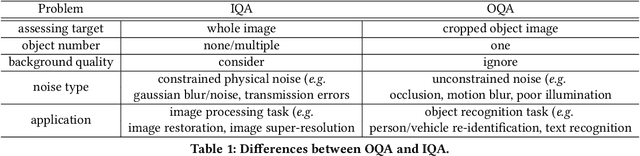
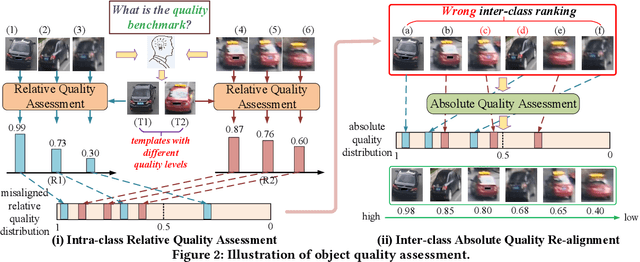
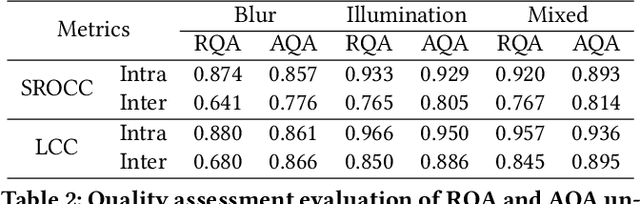
In object recognition applications, object images usually appear with different quality levels. Practically, it is very important to indicate object image qualities for better application performance, e.g. filtering out low-quality object image frames to maintain robust video object recognition results and speed up inference. However, no previous works are explicitly proposed for addressing the problem. In this paper, we define the problem of object quality assessment for the first time and propose an effective approach named Object-QA to assess high-reliable quality scores for object images. Concretely, Object-QA first employs a well-designed relative quality assessing module that learns the intra-class-level quality scores by referring to the difference between object images and their estimated templates. Then an absolute quality assessing module is designed to generate the final quality scores by aligning the quality score distributions in inter-class. Besides, Object-QA can be implemented with only object-level annotations, and is also easily deployed to a variety of object recognition tasks. To our best knowledge this is the first work to put forward the definition of this problem and conduct quantitative evaluations. Validations on 5 different datasets show that Object-QA can not only assess high-reliable quality scores according with human cognition, but also improve application performance.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020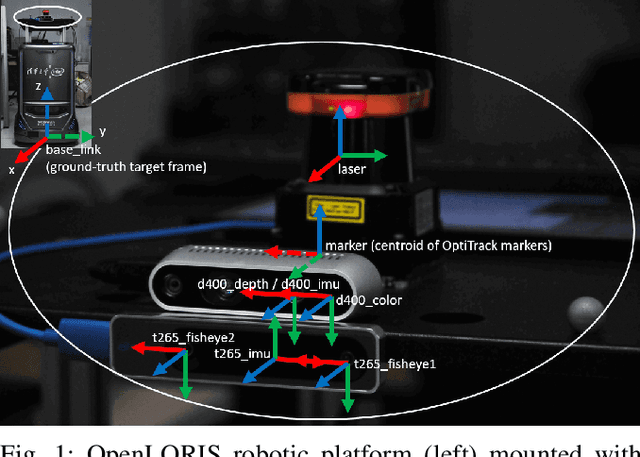


This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
Counterfactual Samples Synthesizing for Robust Visual Question Answering
Mar 14, 2020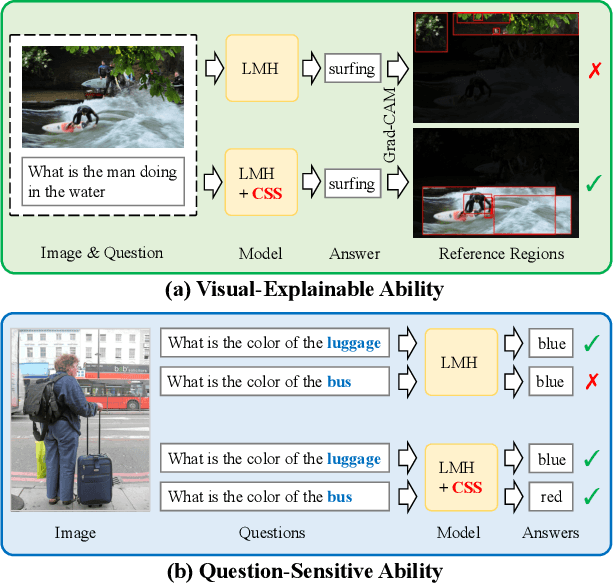
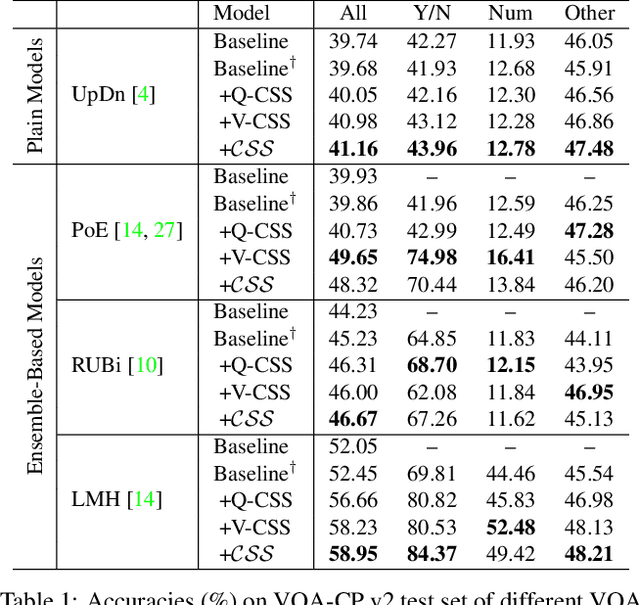

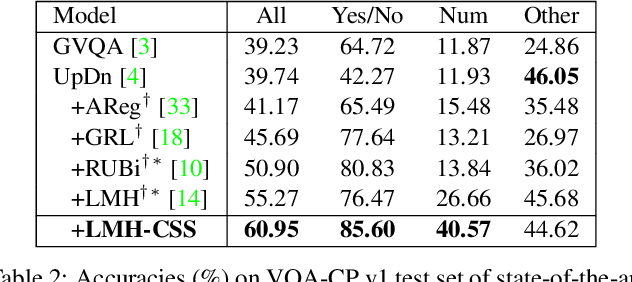
Despite Visual Question Answering (VQA) has realized impressive progress over the last few years, today's VQA models tend to capture superficial linguistic correlations in the train set and fail to generalize to the test set with different QA distributions. To reduce the language biases, several recent works introduce an auxiliary question-only model to regularize the training of targeted VQA model, and achieve dominating performance on VQA-CP. However, since the complexity of design, current methods are unable to equip the ensemble-based models with two indispensable characteristics of an ideal VQA model: 1) visual-explainable: the model should rely on the right visual regions when making decisions. 2) question-sensitive: the model should be sensitive to the linguistic variations in question. To this end, we propose a model-agnostic Counterfactual Samples Synthesizing (CSS) training scheme. The CSS generates numerous counterfactual training samples by masking critical objects in images or words in questions, and assigning different ground-truth answers. After training with the complementary samples (ie, the original and generated samples), the VQA models are forced to focus on all critical objects and words, which significantly improves both visual-explainable and question-sensitive abilities. In return, the performance of these models is further boosted. Extensive ablations have shown the effectiveness of CSS. Particularly, by building on top of the model LMH, we achieve a record-breaking performance of 58.95% on VQA-CP v2, with 6.5% gains.
Neural Inheritance Relation Guided One-Shot Layer Assignment Search
Feb 28, 2020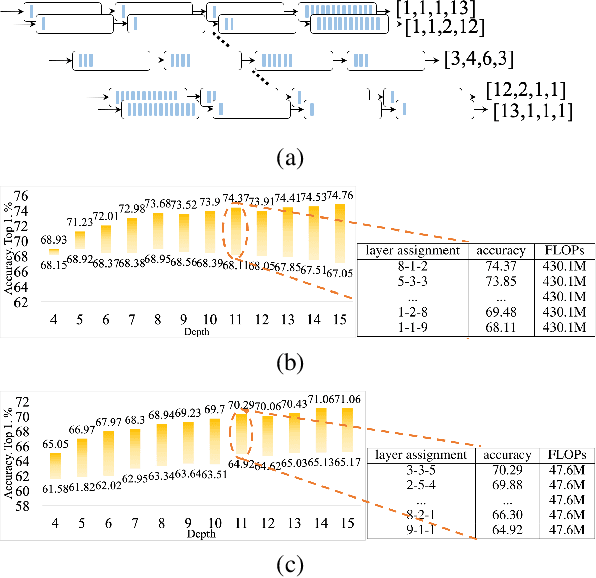
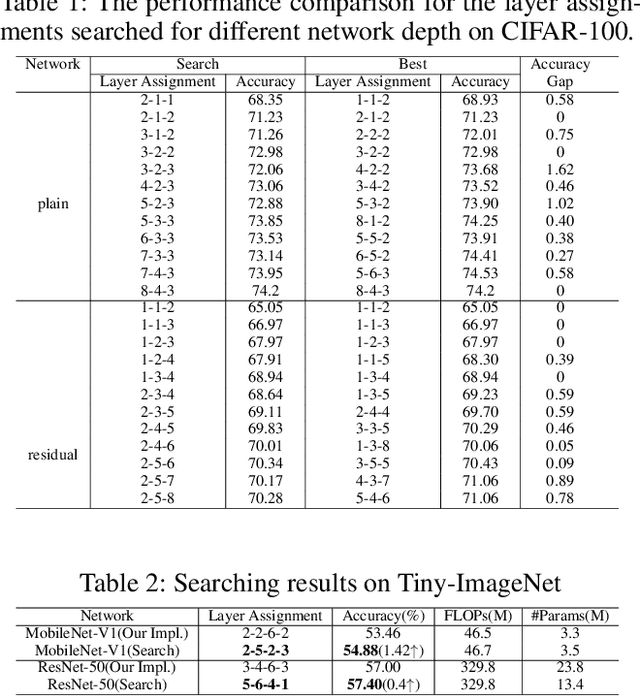
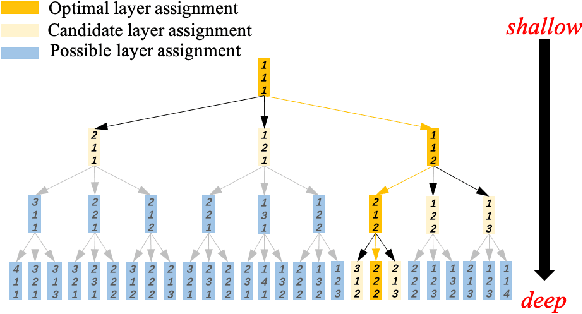
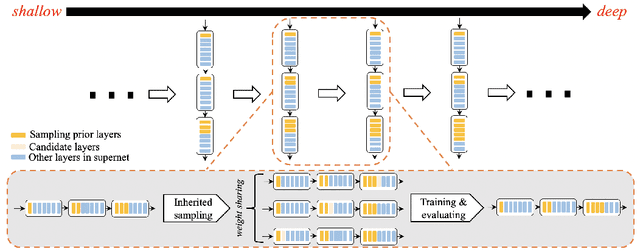
Layer assignment is seldom picked out as an independent research topic in neural architecture search. In this paper, for the first time, we systematically investigate the impact of different layer assignments to the network performance by building an architecture dataset of layer assignment on CIFAR-100. Through analyzing this dataset, we discover a neural inheritance relation among the networks with different layer assignments, that is, the optimal layer assignments for deeper networks always inherit from those for shallow networks. Inspired by this neural inheritance relation, we propose an efficient one-shot layer assignment search approach via inherited sampling. Specifically, the optimal layer assignment searched in the shallow network can be provided as a strong sampling priori to train and search the deeper ones in supernet, which extremely reduces the network search space. Comprehensive experiments carried out on CIFAR-100 illustrate the efficiency of our proposed method. Our search results are strongly consistent with the optimal ones directly selected from the architecture dataset. To further confirm the generalization of our proposed method, we also conduct experiments on Tiny-ImageNet and ImageNet. Our searched results are remarkably superior to the handcrafted ones under the unchanged computational budgets. The neural inheritance relation discovered in this paper can provide insights to the universal neural architecture search.
Refined Gate: A Simple and Effective Gating Mechanism for Recurrent Units
Feb 26, 2020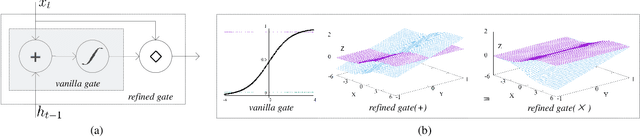
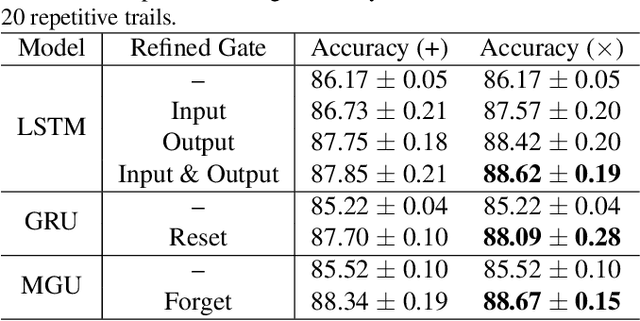
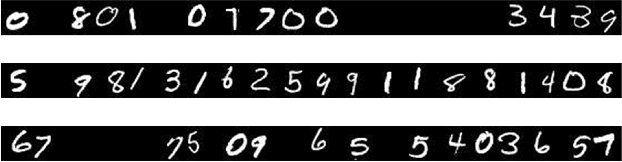
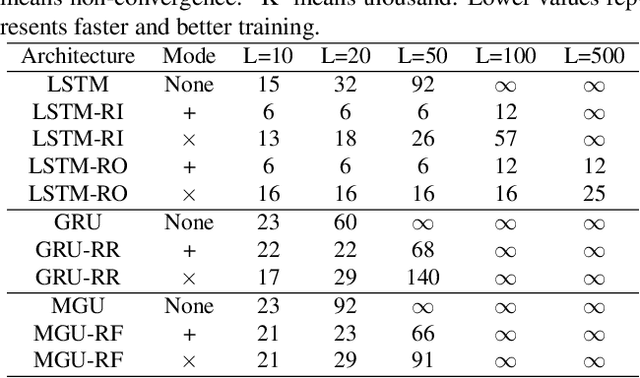
Recurrent neural network (RNN) has been widely studied in sequence learning tasks, while the mainstream models (e.g., LSTM and GRU) rely on the gating mechanism (in control of how information flows between hidden states). However, the vanilla gates in RNN (e.g. the input gate in LSTM) suffer from the problem of gate undertraining mainly due to the saturating activation functions, which may result in failures of learning gating roles and thus the weak performance. In this paper, we propose a new gating mechanism within general gated recurrent neural networks to handle this issue. Specifically, the proposed gates directly short connect the extracted input features to the outputs of vanilla gates, denoted as refined gates. The refining mechanism allows enhancing gradient back-propagation as well as extending the gating activation scope, which, although simple, can guide RNN to reach possibly deeper minima. We verify the proposed gating mechanism on three popular types of gated RNNs including LSTM, GRU and MGU. Extensive experiments on 3 synthetic tasks, 3 language modeling tasks and 5 scene text recognition benchmarks demonstrate the effectiveness of our method.
Text Perceptron: Towards End-to-End Arbitrary-Shaped Text Spotting
Feb 17, 2020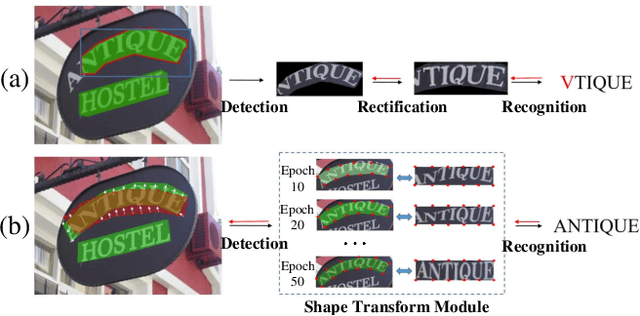
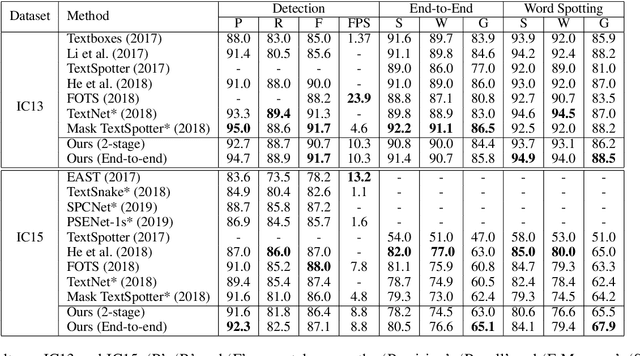
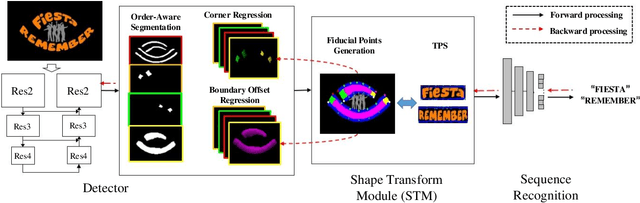
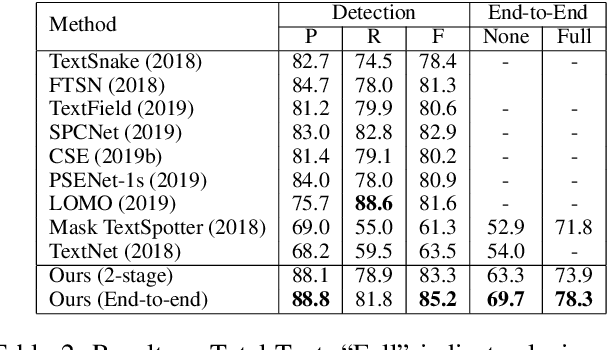
Many approaches have recently been proposed to detect irregular scene text and achieved promising results. However, their localization results may not well satisfy the following text recognition part mainly because of two reasons: 1) recognizing arbitrary shaped text is still a challenging task, and 2) prevalent non-trainable pipeline strategies between text detection and text recognition will lead to suboptimal performances. To handle this incompatibility problem, in this paper we propose an end-to-end trainable text spotting approach named Text Perceptron. Concretely, Text Perceptron first employs an efficient segmentation-based text detector that learns the latent text reading order and boundary information. Then a novel Shape Transform Module (abbr. STM) is designed to transform the detected feature regions into regular morphologies without extra parameters. It unites text detection and the following recognition part into a whole framework, and helps the whole network achieve global optimization. Experiments show that our method achieves competitive performance on two standard text benchmarks, i.e., ICDAR 2013 and ICDAR 2015, and also obviously outperforms existing methods on irregular text benchmarks SCUT-CTW1500 and Total-Text.
An End-to-End Audio Classification System based on Raw Waveforms and Mix-Training Strategy
Nov 21, 2019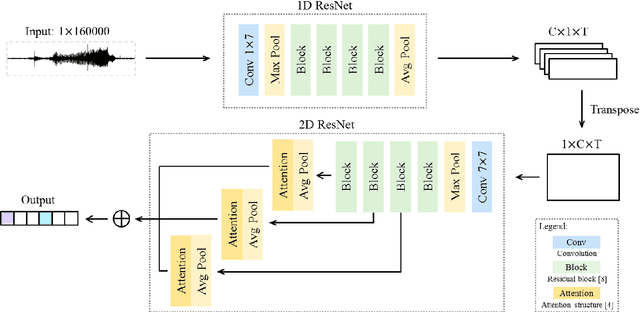

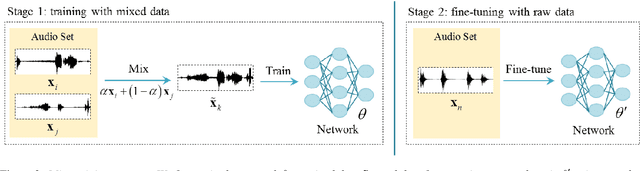

Audio classification can distinguish different kinds of sounds, which is helpful for intelligent applications in daily life. However, it remains a challenging task since the sound events in an audio clip is probably multiple, even overlapping. This paper introduces an end-to-end audio classification system based on raw waveforms and mix-training strategy. Compared to human-designed features which have been widely used in existing research, raw waveforms contain more complete information and are more appropriate for multi-label classification. Taking raw waveforms as input, our network consists of two variants of ResNet structure which can learn a discriminative representation. To explore the information in intermediate layers, a multi-level prediction with attention structure is applied in our model. Furthermore, we design a mix-training strategy to break the performance limitation caused by the amount of training data. Experiments show that the mean average precision of the proposed audio classification system on Audio Set dataset is 37.2%. Without using extra training data, our system exceeds the state-of-the-art multi-level attention model.