 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Invariant Representation for Visible-Infrared Person Re-Identification
Feb 02, 2023



Cross-spectral person re-identification, which aims to associate identities to pedestrians across different spectra, faces a main challenge of the modality discrepancy. In this paper, we address the problem from both image-level and feature-level in an end-to-end hybrid learning framework named robust feature mining network (RFM). In particular, we observe that the reflective intensity of the same surface in photos shot in different wavelengths could be transformed using a linear model. Besides, we show the variable linear factor across the different surfaces is the main culprit which initiates the modality discrepancy. We integrate such a reflection observation into an image-level data augmentation by proposing the linear transformation generator (LTG). Moreover, at the feature level, we introduce a cross-center loss to explore a more compact intra-class distribution and modality-aware spatial attention to take advantage of textured regions more efficiently. Experiment results on two standard cross-spectral person re-identification datasets, i.e., RegDB and SYSU-MM01, have demonstrated state-of-the-art performance.
DAMSL: Domain Agnostic Meta Score-based Learning
Jun 06, 2021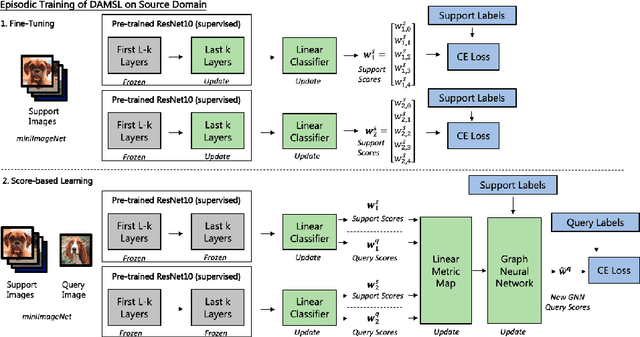
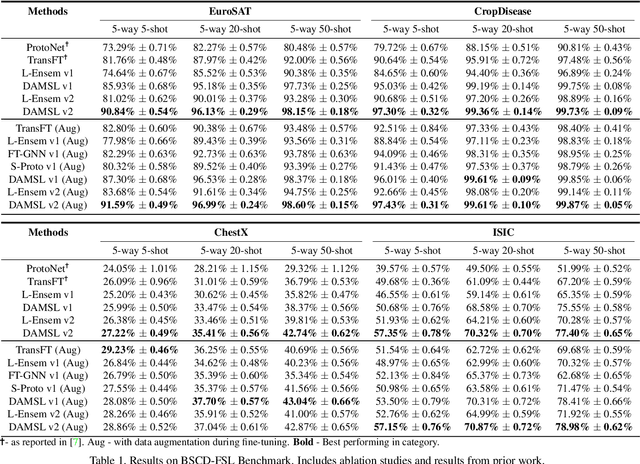
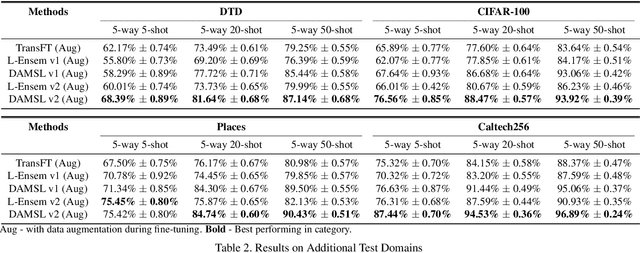
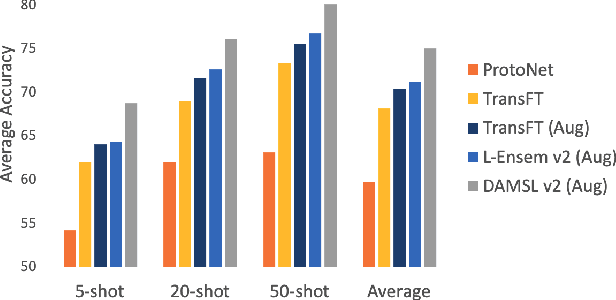
In this paper, we propose Domain Agnostic Meta Score-based Learning (DAMSL), a novel, versatile and highly effective solution that delivers significant out-performance over state-of-the-art methods for cross-domain few-shot learning. We identify key problems in previous meta-learning methods over-fitting to the source domain, and previous transfer-learning methods under-utilizing the structure of the support set. The core idea behind our method is that instead of directly using the scores from a fine-tuned feature encoder, we use these scores to create input coordinates for a domain agnostic metric space. A graph neural network is applied to learn an embedding and relation function over these coordinates to process all information contained in the score distribution of the support set. We test our model on both established CD-FSL benchmarks and new domains and show that our method overcomes the limitations of previous meta-learning and transfer-learning methods to deliver substantial improvements in accuracy across both smaller and larger domain shifts.
Speaker-Utterance Dual Attention for Speaker and Utterance Verification
Aug 20, 2020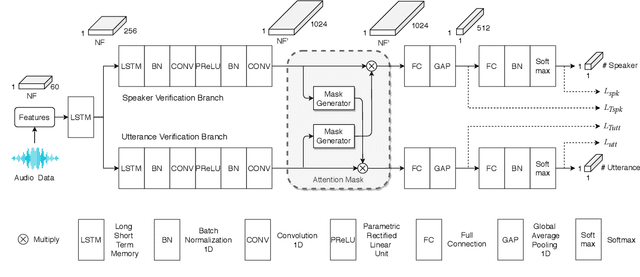
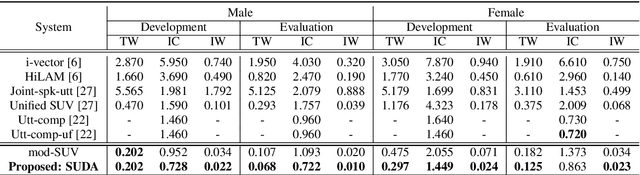
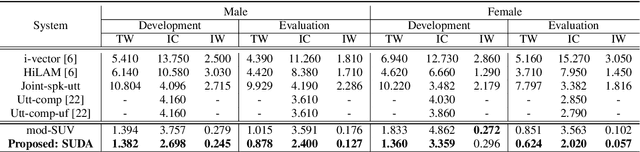
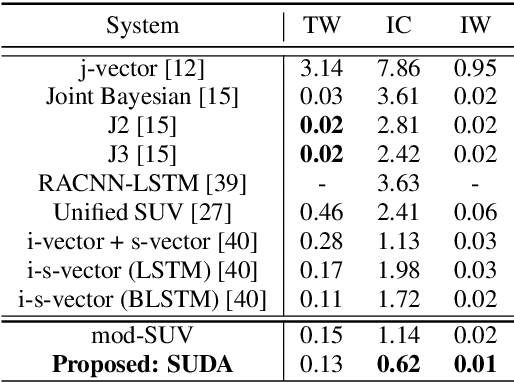
In this paper, we study a novel technique that exploits the interaction between speaker traits and linguistic content to improve both speaker verification and utterance verification performance. We implement an idea of speaker-utterance dual attention (SUDA) in a unified neural network. The dual attention refers to an attention mechanism for the two tasks of speaker and utterance verification. The proposed SUDA features an attention mask mechanism to learn the interaction between the speaker and utterance information streams. This helps to focus only on the required information for respective task by masking the irrelevant counterparts. The studies conducted on RSR2015 corpus confirm that the proposed SUDA outperforms the framework without attention mask as well as several competitive systems for both speaker and utterance verification.
Data Augmentation Imbalance For Imbalanced Attribute Classification
May 21, 2020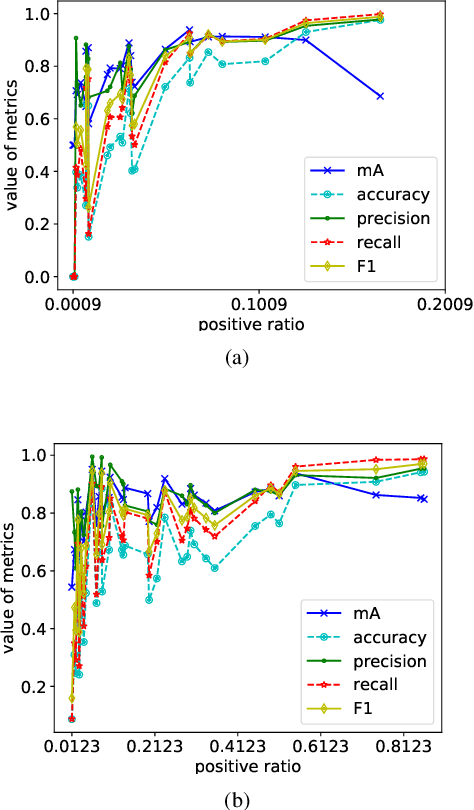
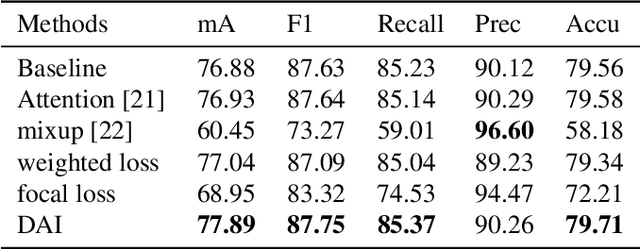
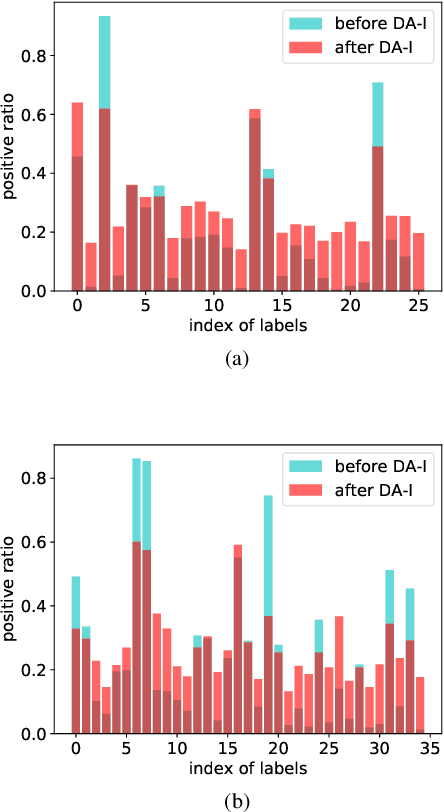
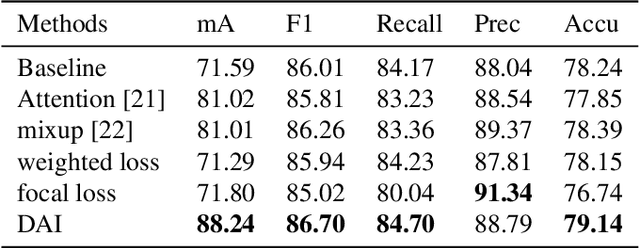
Pedestrian attribute recognition is an important multi-label classification problem. Although the convolutional neural networks are prominent in learning discriminative features from images, the data imbalance in multi-label setting for fine-grained tasks remains an open problem. In this paper, we propose a new re-sampling algorithm called: data augmentation imbalance (DAI) to explicitly enhance the ability to discriminate the fewer attributes via increasing the proportion of labels accounting for a small part. Fundamentally, by applying over-sampling and under-sampling on the multi-label dataset at the same time, the thought of robbing the rich attributes and helping the poor makes a significant contribution to DAI. Extensive empirical evidence shows that our DAI algorithm achieves state-of-the-art results, based on pedestrian attribute datasets, i.e. standard PA-100K and PETA datasets.
Cross-Resolution Face Recognition via Prior-Aided Face Hallucination and Residual Knowledge Distillation
May 26, 2019

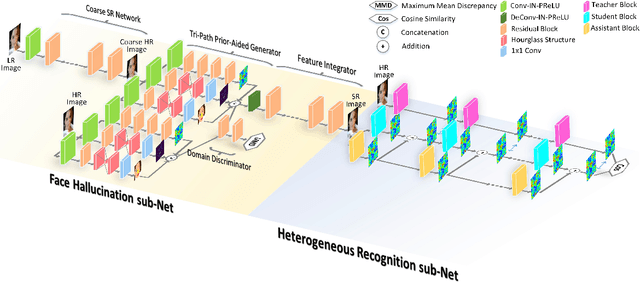
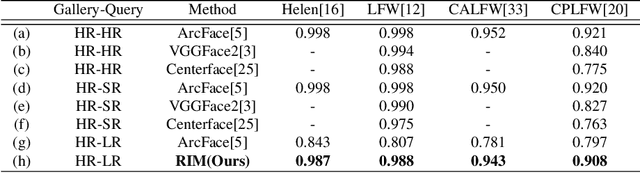
Recent deep learning based face recognition methods have achieved great performance, but it still remains challenging to recognize very low-resolution query face like 28x28 pixels when CCTV camera is far from the captured subject. Such face with very low-resolution is totally out of detail information of the face identity compared to normal resolution in a gallery and hard to find corresponding faces therein. To this end, we propose a Resolution Invariant Model (RIM) for addressing such cross-resolution face recognition problems, with three distinct novelties. First, RIM is a novel and unified deep architecture, containing a Face Hallucination sub-Net (FHN) and a Heterogeneous Recognition sub-Net (HRN), which are jointly learned end to end. Second, FHN is a well-designed tri-path Generative Adversarial Network (GAN) which simultaneously perceives facial structure and geometry prior information, i.e. landmark heatmaps and parsing maps, incorporated with an unsupervised cross-domain adversarial training strategy to super-resolve very low-resolution query image to its 8x larger ones without requiring them to be well aligned. Third, HRN is a generic Convolutional Neural Network (CNN) for heterogeneous face recognition with our proposed residual knowledge distillation strategy for learning discriminative yet generalized feature representation. Quantitative and qualitative experiments on several benchmarks demonstrate the superiority of the proposed model over the state-of-the-arts. Codes and models will be released upon acceptance.
Detecting The Objects on The Road Using Modular Lightweight Network
Nov 16, 2018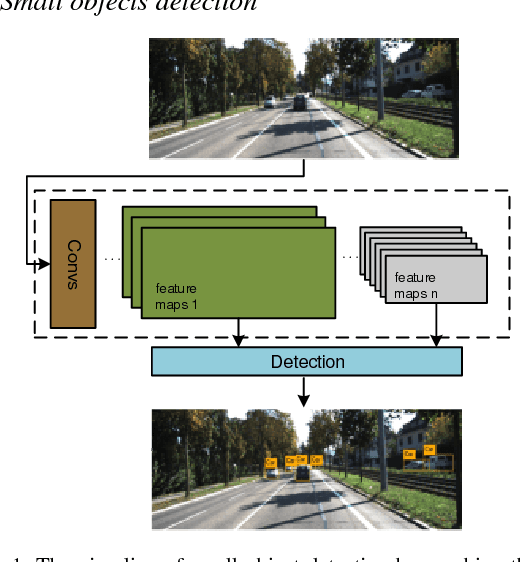

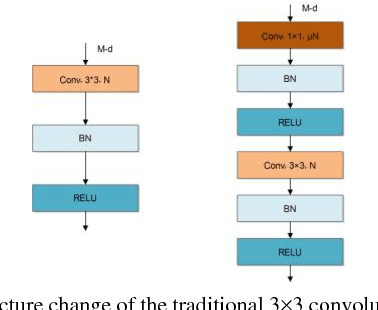
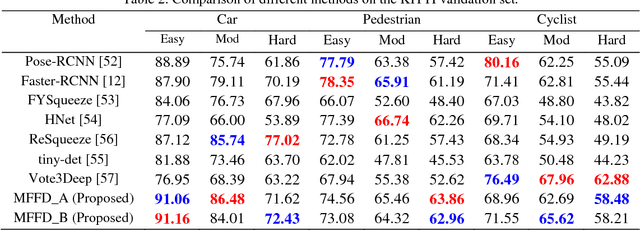
This paper presents a modular lightweight network model for road objects detection, such as car, pedestrian and cyclist, especially when they are far away from the camera and their sizes are small. Great advances have been made for the deep networks, but small objects detection is still a challenging task. In order to solve this problem, majority of existing methods utilize complicated network or bigger image size, which generally leads to higher computation cost. The proposed network model is referred to as modular feature fusion detector (MFFD), using a fast and efficient network architecture for detecting small objects. The contribution lies in the following aspects: 1) Two base modules have been designed for efficient computation: Front module reduce the information loss from raw input images; Tinier module decrease model size and computation cost, while ensuring the detection accuracy. 2) By stacking the base modules, we design a context features fusion framework for multi-scale object detection. 3) The propose method is efficient in terms of model size and computation cost, which is applicable for resource limited devices, such as embedded systems for advanced driver assistance systems (ADAS). Comparisons with the state-of-the-arts on the challenging KITTI dataset reveal the superiority of the proposed method. Especially, 100 fps can be achieved on the embedded GPUs such as Jetson TX2.
Look Across Elapse: Disentangled Representation Learning and Photorealistic Cross-Age Face Synthesis for Age-Invariant Face Recognition
Oct 04, 2018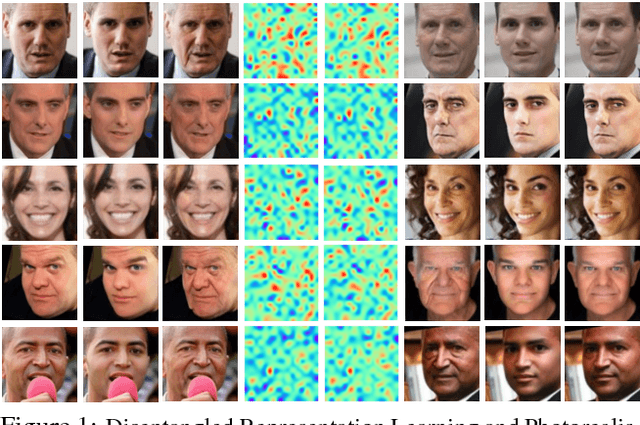
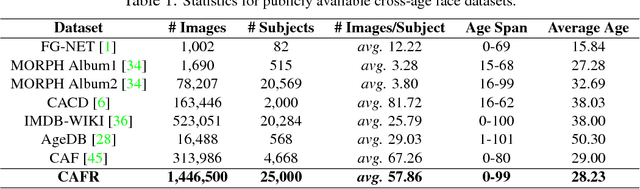
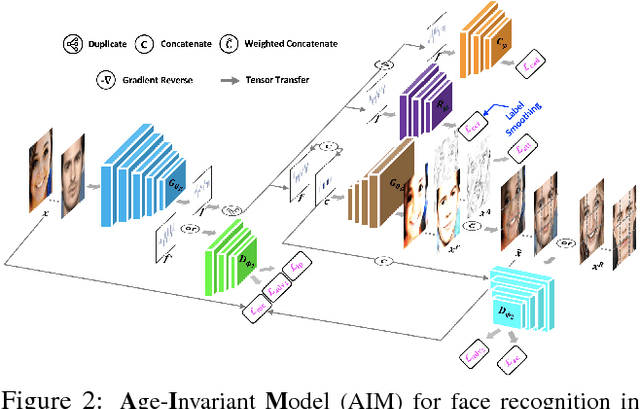
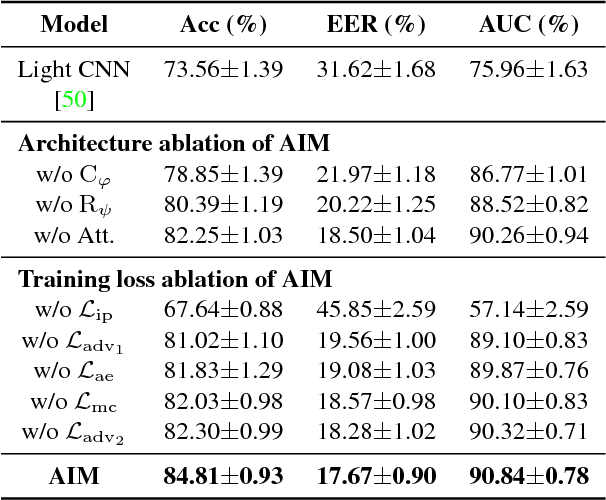
Despite the remarkable progress in face recognition related technologies, reliably recognizing faces across ages still remains a big challenge. The appearance of a human face changes substantially over time, resulting in significant intra-class variations. As opposed to current techniques for age-invariant face recognition, which either directly extract age-invariant features for recognition, or first synthesize a face that matches target age before feature extraction, we argue that it is more desirable to perform both tasks jointly so that they can leverage each other. To this end, we propose a deep Age-Invariant Model (AIM) for face recognition in the wild with three distinct novelties. First, AIM presents a novel unified deep architecture jointly performing cross-age face synthesis and recognition in a mutual boosting way. Second, AIM achieves continuous face rejuvenation/aging with remarkable photorealistic and identity-preserving properties, avoiding the requirement of paired data and the true age of testing samples. Third, we develop effective and novel training strategies for end-to-end learning the whole deep architecture, which generates powerful age-invariant face representations explicitly disentangled from the age variation. Moreover, we propose a new large-scale Cross-Age Face Recognition (CAFR) benchmark dataset to facilitate existing efforts and push the frontiers of age-invariant face recognition research. Extensive experiments on both our CAFR and several other cross-age datasets (MORPH, CACD and FG-NET) demonstrate the superiority of the proposed AIM model over the state-of-the-arts. Benchmarking our model on one of the most popular unconstrained face recognition datasets IJB-C additionally verifies the promising generalizability of AIM in recognizing faces in the wild.
Person re-identification with fusion of hand-crafted and deep pose-based body region features
Mar 27, 2018

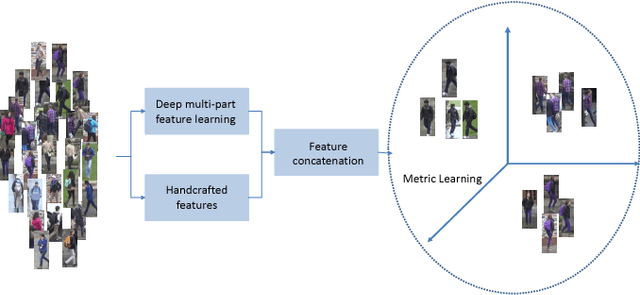
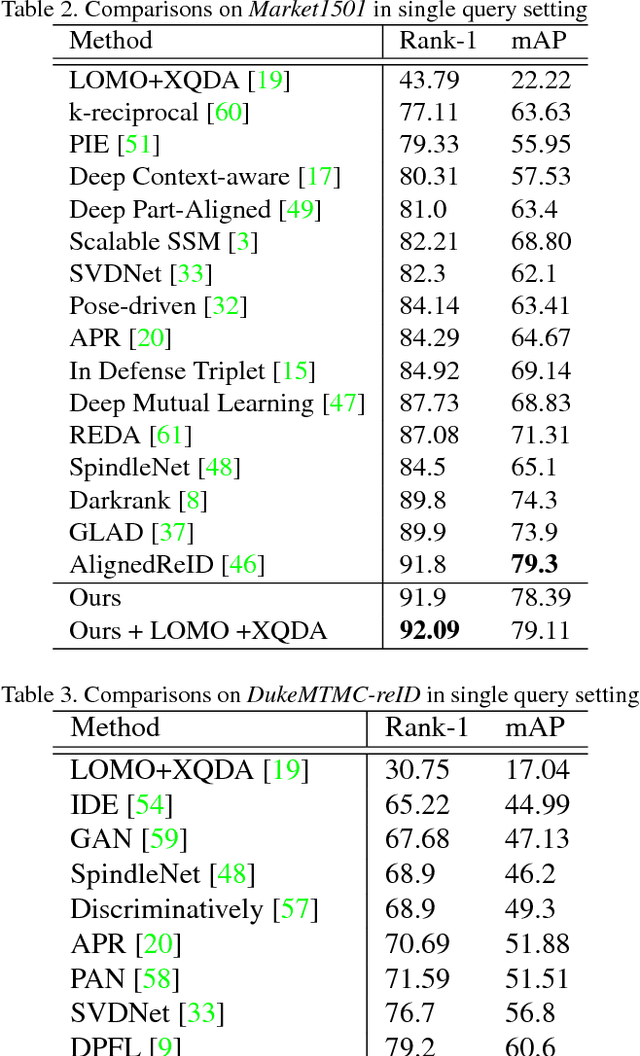
Person re-identification (re-ID) aims to accurately re- trieve a person from a large-scale database of images cap- tured across multiple cameras. Existing works learn deep representations using a large training subset of unique per- sons. However, identifying unseen persons is critical for a good re-ID algorithm. Moreover, the misalignment be- tween person crops to detection errors or pose variations leads to poor feature matching. In this work, we present a fusion of handcrafted features and deep feature representa- tion learned using multiple body parts to complement the global body features that achieves high performance on un- seen test images. Pose information is used to detect body regions that are passed through Convolutional Neural Net- works (CNN) to guide feature learning. Finally, a metric learning step enables robust distance matching on a dis- criminative subspace. Experimental results on 4 popular re-ID benchmark datasets namely VIPer, DukeMTMC-reID, Market-1501 and CUHK03 show that the proposed method achieves state-of-the-art performance in image-based per- son re-identification.
A Good Practice Towards Top Performance of Face Recognition: Transferred Deep Feature Fusion
Feb 09, 2018
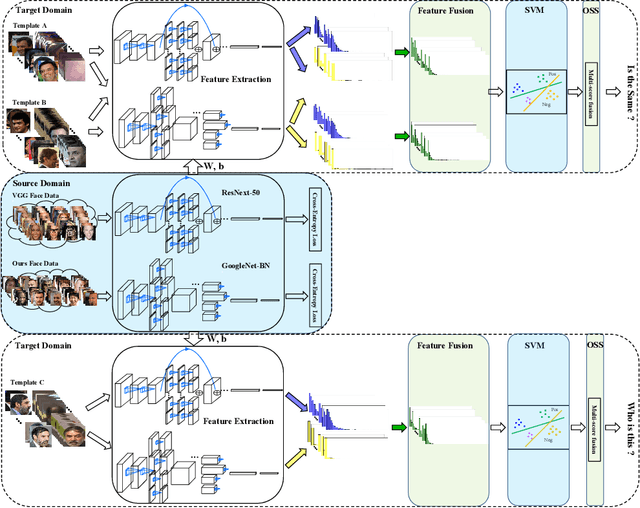
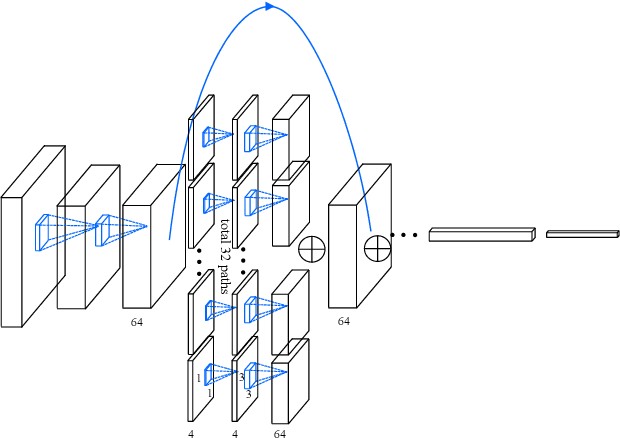
Unconstrained face recognition performance evaluations have traditionally focused on Labeled Faces in the Wild (LFW) dataset for imagery and the YouTubeFaces (YTF) dataset for videos in the last couple of years. Spectacular progress in this field has resulted in saturation on verification and identification accuracies for those benchmark datasets. In this paper, we propose a unified learning framework named Transferred Deep Feature Fusion (TDFF) targeting at the new IARPA Janus Benchmark A (IJB-A) face recognition dataset released by NIST face challenge. The IJB-A dataset includes real-world unconstrained faces from 500 subjects with full pose and illumination variations which are much harder than the LFW and YTF datasets. Inspired by transfer learning, we train two advanced deep convolutional neural networks (DCNN) with two different large datasets in source domain, respectively. By exploring the complementarity of two distinct DCNNs, deep feature fusion is utilized after feature extraction in target domain. Then, template specific linear SVMs is adopted to enhance the discrimination of framework. Finally, multiple matching scores corresponding different templates are merged as the final results. This simple unified framework exhibits excellent performance on IJB-A dataset. Based on the proposed approach, we have submitted our IJB-A results to National Institute of Standards and Technology (NIST) for official evaluation. Moreover, by introducing new data and advanced neural architecture, our method outperforms the state-of-the-art by a wide margin on IJB-A dataset.
Intention-Net: Integrating Planning and Deep Learning for Goal-Directed Autonomous Navigation
Oct 17, 2017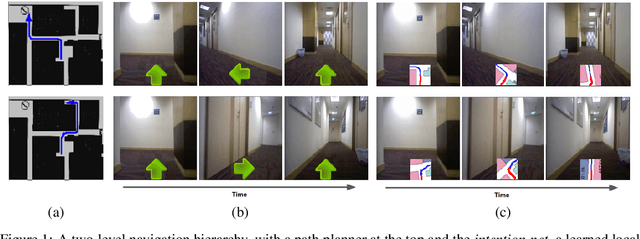
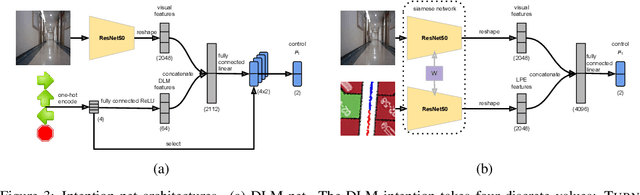
How can a delivery robot navigate reliably to a destination in a new office building, with minimal prior information? To tackle this challenge, this paper introduces a two-level hierarchical approach, which integrates model-free deep learning and model-based path planning. At the low level, a neural-network motion controller, called the intention-net, is trained end-to-end to provide robust local navigation. The intention-net maps images from a single monocular camera and "intentions" directly to robot controls. At the high level, a path planner uses a crude map, e.g., a 2-D floor plan, to compute a path from the robot's current location to the goal. The planned path provides intentions to the intention-net. Preliminary experiments suggest that the learned motion controller is robust against perceptual uncertainty and by integrating with a path planner, it generalizes effectively to new environments and goals.