 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Expressive Appropriateness of Speech in Rich Contexts
May 10, 2026Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
PhiNet: Speaker Verification with Phonetic Interpretability
Apr 02, 2026Despite remarkable progress, automatic speaker verification (ASV) systems typically lack the transparency required for high-accountability applications. Motivated by how human experts perform forensic speaker comparison (FSC), we propose a speaker verification network with phonetic interpretability, PhiNet, designed to enhance both local and global interpretability by leveraging phonetic evidence in decision-making. For users, PhiNet provides detailed phonetic-level comparisons that enable manual inspection of speaker-specific features and facilitate a more critical evaluation of verification outcomes. For developers, it offers explicit reasoning behind verification decisions, simplifying error tracing and informing hyperparameter selection. In our experiments, we demonstrate PhiNet's interpretability with practical examples, including its application in analyzing the impact of different hyperparameters. We conduct both qualitative and quantitative evaluations of the proposed interpretability methods and assess speaker verification performance across multiple benchmark datasets, including VoxCeleb, SITW, and LibriSpeech. Results show that PhiNet achieves performance comparable to traditional black-box ASV models while offering meaningful, interpretable explanations for its decisions, bridging the gap between ASV and forensic analysis.
Scores Know Bobs Voice: Speaker Impersonation Attack
Mar 03, 2026Advances in deep learning have enabled the widespread deployment of speaker recognition systems (SRSs), yet they remain vulnerable to score-based impersonation attacks. Existing attacks that operate directly on raw waveforms require a large number of queries due to the difficulty of optimizing in high-dimensional audio spaces. Latent-space optimization within generative models offers improved efficiency, but these latent spaces are shaped by data distribution matching and do not inherently capture speaker-discriminative geometry. As a result, optimization trajectories often fail to align with the adversarial direction needed to maximize victim scores. To address this limitation, we propose an inversion-based generative attack framework that explicitly aligns the latent space of the synthesis model with the discriminative feature space of SRSs. We first analyze the requirements of an inverse model for score-based attacks and introduce a feature-aligned inversion strategy that geometrically synchronizes latent representations with speaker embeddings. This alignment ensures that latent updates directly translate into score improvements. Moreover, it enables new attack paradigms, including subspace-projection-based attacks, which were previously infeasible due to the absence of a faithful feature-to-audio mapping. Experiments show that our method significantly improves query efficiency, achieving competitive attack success rates with on average 10x fewer queries than prior approaches. In particular, the enabled subspace-projection-based attack attains up to 91.65% success using only 50 queries. These findings establish feature-aligned inversion as a key tool for evaluating the robustness of modern SRSs against score-based impersonation threats.
WeDefense: A Toolkit to Defend Against Fake Audio
Jan 21, 2026The advances in generative AI have enabled the creation of synthetic audio which is perceptually indistinguishable from real, genuine audio. Although this stellar progress enables many positive applications, it also raises risks of misuse, such as for impersonation, disinformation and fraud. Despite a growing number of open-source fake audio detection codes released through numerous challenges and initiatives, most are tailored to specific competitions, datasets or models. A standardized and unified toolkit that supports the fair benchmarking and comparison of competing solutions with not just common databases, protocols, metrics, but also a shared codebase, is missing. To address this, we propose WeDefense, the first open-source toolkit to support both fake audio detection and localization. Beyond model training, WeDefense emphasizes critical yet often overlooked components: flexible input and augmentation, calibration, score fusion, standardized evaluation metrics, and analysis tools for deeper understanding and interpretation. The toolkit is publicly available at https://github.com/zlin0/wedefense with interactive demos for fake audio detection and localization.
Interpolating Speaker Identities in Embedding Space for Data Expansion
Aug 26, 2025



The success of deep learning-based speaker verification systems is largely attributed to access to large-scale and diverse speaker identity data. However, collecting data from more identities is expensive, challenging, and often limited by privacy concerns. To address this limitation, we propose INSIDE (Interpolating Speaker Identities in Embedding Space), a novel data expansion method that synthesizes new speaker identities by interpolating between existing speaker embeddings. Specifically, we select pairs of nearby speaker embeddings from a pretrained speaker embedding space and compute intermediate embeddings using spherical linear interpolation. These interpolated embeddings are then fed to a text-to-speech system to generate corresponding speech waveforms. The resulting data is combined with the original dataset to train downstream models. Experiments show that models trained with INSIDE-expanded data outperform those trained only on real data, achieving 3.06\% to 5.24\% relative improvements. While INSIDE is primarily designed for speaker verification, we also validate its effectiveness on gender classification, where it yields a 13.44\% relative improvement. Moreover, INSIDE is compatible with other augmentation techniques and can serve as a flexible, scalable addition to existing training pipelines.
Incorporating Contextual Paralinguistic Understanding in Large Speech-Language Models
Aug 10, 2025Current large speech language models (Speech-LLMs) often exhibit limitations in empathetic reasoning, primarily due to the absence of training datasets that integrate both contextual content and paralinguistic cues. In this work, we propose two approaches to incorporate contextual paralinguistic information into model training: (1) an explicit method that provides paralinguistic metadata (e.g., emotion annotations) directly to the LLM, and (2) an implicit method that automatically generates novel training question-answer (QA) pairs using both categorical and dimensional emotion annotations alongside speech transcriptions. Our implicit method boosts performance (LLM-judged) by 38.41% on a human-annotated QA benchmark, reaching 46.02% when combined with the explicit approach, showing effectiveness in contextual paralinguistic understanding. We also validate the LLM judge by demonstrating its correlation with classification metrics, providing support for its reliability.
Contextual Paralinguistic Data Creation for Multi-Modal Speech-LLM: Data Condensation and Spoken QA Generation
May 19, 2025Current speech-LLMs exhibit limited capability in contextual reasoning alongside paralinguistic understanding, primarily due to the lack of Question-Answer (QA) datasets that cover both aspects. We propose a novel framework for dataset generation from in-the-wild speech data, that integrates contextual reasoning with paralinguistic information. It consists of a pseudo paralinguistic label-based data condensation of in-the-wild speech and LLM-based Contextual Paralinguistic QA (CPQA) generation. The effectiveness is validated by a strong correlation in evaluations of the Qwen2-Audio-7B-Instruct model on a dataset created by our framework and human-generated CPQA dataset. The results also reveal the speech-LLM's limitations in handling empathetic reasoning tasks, highlighting the need for such datasets and more robust models. The proposed framework is first of its kind and has potential in training more robust speech-LLMs with paralinguistic reasoning capabilities.
Nes2Net: A Lightweight Nested Architecture for Foundation Model Driven Speech Anti-spoofing
Apr 08, 2025Speech foundation models have significantly advanced various speech-related tasks by providing exceptional representation capabilities. However, their high-dimensional output features often create a mismatch with downstream task models, which typically require lower-dimensional inputs. A common solution is to apply a dimensionality reduction (DR) layer, but this approach increases parameter overhead, computational costs, and risks losing valuable information. To address these issues, we propose Nested Res2Net (Nes2Net), a lightweight back-end architecture designed to directly process high-dimensional features without DR layers. The nested structure enhances multi-scale feature extraction, improves feature interaction, and preserves high-dimensional information. We first validate Nes2Net on CtrSVDD, a singing voice deepfake detection dataset, and report a 22% performance improvement and an 87% back-end computational cost reduction over the state-of-the-art baseline. Additionally, extensive testing across four diverse datasets: ASVspoof 2021, ASVspoof 5, PartialSpoof, and In-the-Wild, covering fully spoofed speech, adversarial attacks, partial spoofing, and real-world scenarios, consistently highlights Nes2Net's superior robustness and generalization capabilities. The code package and pre-trained models are available at https://github.com/Liu-Tianchi/Nes2Net.
Audio-FLAN: A Preliminary Release
Feb 23, 2025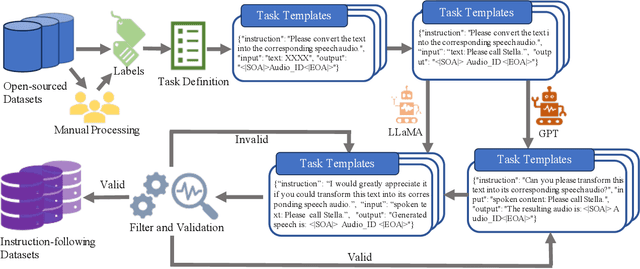

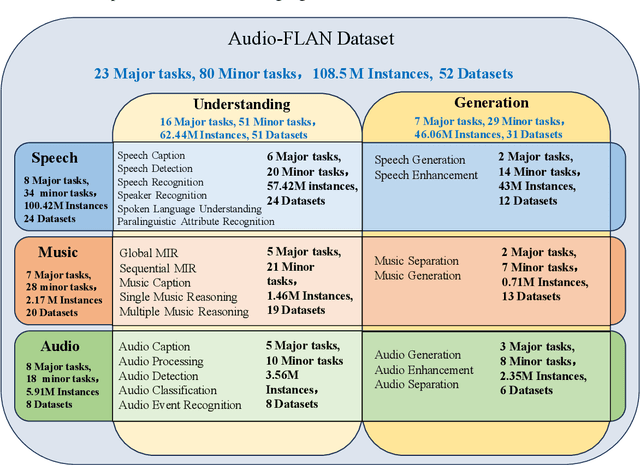

Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.
ExPO: Explainable Phonetic Trait-Oriented Network for Speaker Verification
Jan 14, 2025



In speaker verification, we use computational method to verify if an utterance matches the identity of an enrolled speaker. This task is similar to the manual task of forensic voice comparison, where linguistic analysis is combined with auditory measurements to compare and evaluate voice samples. Despite much success, we have yet to develop a speaker verification system that offers explainable results comparable to those from manual forensic voice comparison. A novel approach, Explainable Phonetic Trait-Oriented (ExPO) network, is proposed in this paper to introduce the speaker's phonetic trait which describes the speaker's characteristics at the phonetic level, resembling what forensic comparison does. ExPO not only generates utterance-level speaker embeddings but also allows for fine-grained analysis and visualization of phonetic traits, offering an explainable speaker verification process. Furthermore, we investigate phonetic traits from within-speaker and between-speaker variation perspectives to determine which trait is most effective for speaker verification, marking an important step towards explainable speaker verification. Our code is available at https://github.com/mmmmayi/ExPO.