 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConQueR: Query Contrast Voxel-DETR for 3D Object Detection
Dec 14, 2022



Although DETR-based 3D detectors can simplify the detection pipeline and achieve direct sparse predictions, their performance still lags behind dense detectors with post-processing for 3D object detection from point clouds. DETRs usually adopt a larger number of queries than GTs (e.g., 300 queries v.s. 40 objects in Waymo) in a scene, which inevitably incur many false positives during inference. In this paper, we propose a simple yet effective sparse 3D detector, named Query Contrast Voxel-DETR (ConQueR), to eliminate the challenging false positives, and achieve more accurate and sparser predictions. We observe that most false positives are highly overlapping in local regions, caused by the lack of explicit supervision to discriminate locally similar queries. We thus propose a Query Contrast mechanism to explicitly enhance queries towards their best-matched GTs over all unmatched query predictions. This is achieved by the construction of positive and negative GT-query pairs for each GT, and a contrastive loss to enhance positive GT-query pairs against negative ones based on feature similarities. ConQueR closes the gap of sparse and dense 3D detectors, and reduces up to ~60% false positives. Our single-frame ConQueR achieves new state-of-the-art (sota) 71.6 mAPH/L2 on the challenging Waymo Open Dataset validation set, outperforming previous sota methods (e.g., PV-RCNN++) by over 2.0 mAPH/L2.
CAGroup3D: Class-Aware Grouping for 3D Object Detection on Point Clouds
Oct 09, 2022
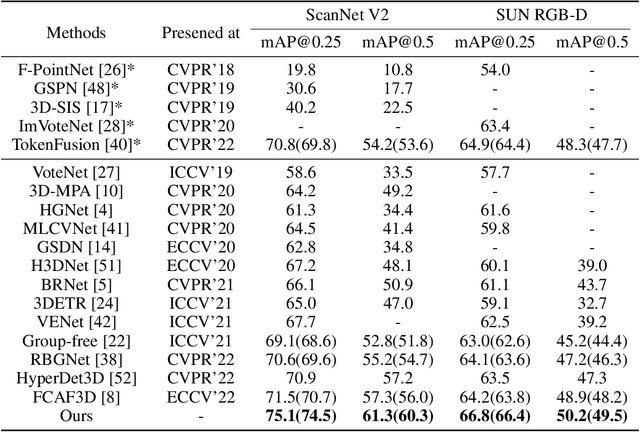
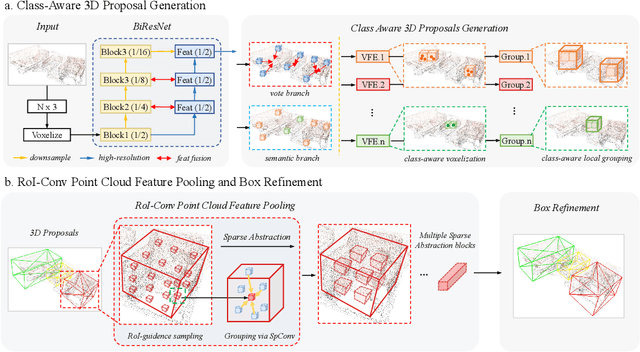

We present a novel two-stage fully sparse convolutional 3D object detection framework, named CAGroup3D. Our proposed method first generates some high-quality 3D proposals by leveraging the class-aware local group strategy on the object surface voxels with the same semantic predictions, which considers semantic consistency and diverse locality abandoned in previous bottom-up approaches. Then, to recover the features of missed voxels due to incorrect voxel-wise segmentation, we build a fully sparse convolutional RoI pooling module to directly aggregate fine-grained spatial information from backbone for further proposal refinement. It is memory-and-computation efficient and can better encode the geometry-specific features of each 3D proposal. Our model achieves state-of-the-art 3D detection performance with remarkable gains of +\textit{3.6\%} on ScanNet V2 and +\textit{2.6}\% on SUN RGB-D in term of mAP@0.25. Code will be available at https://github.com/Haiyang-W/CAGroup3D.
Motion Transformer with Global Intention Localization and Local Movement Refinement
Sep 27, 2022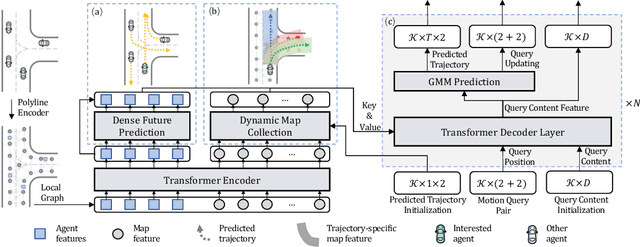
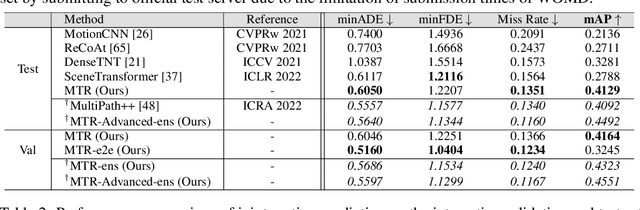
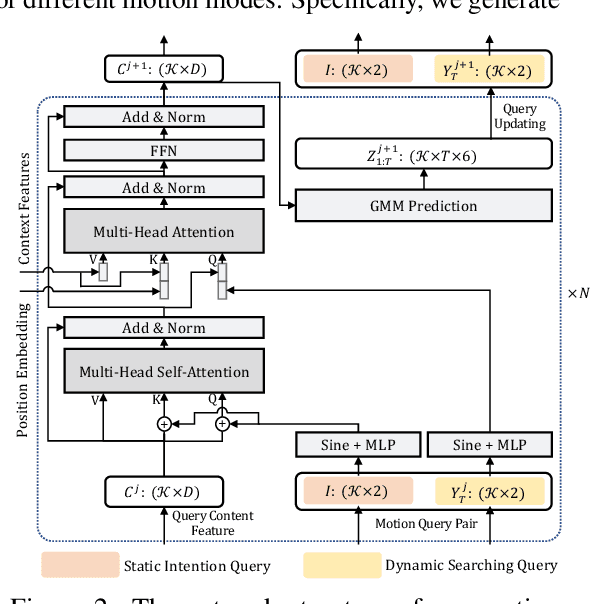
Predicting multimodal future behavior of traffic participants is essential for robotic vehicles to make safe decisions. Existing works explore to directly predict future trajectories based on latent features or utilize dense goal candidates to identify agent's destinations, where the former strategy converges slowly since all motion modes are derived from the same feature while the latter strategy has efficiency issue since its performance highly relies on the density of goal candidates. In this paper, we propose Motion TRansformer (MTR) framework that models motion prediction as the joint optimization of global intention localization and local movement refinement. Instead of using goal candidates, MTR incorporates spatial intention priors by adopting a small set of learnable motion query pairs. Each motion query pair takes charge of trajectory prediction and refinement for a specific motion mode, which stabilizes the training process and facilitates better multimodal predictions. Experiments show that MTR achieves state-of-the-art performance on both the marginal and joint motion prediction challenges, ranking 1st on the leaderboards of Waymo Open Motion Dataset. Code will be available at https://github.com/sshaoshuai/MTR.
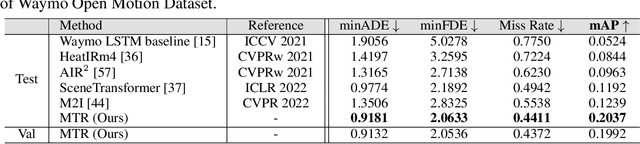
MTR-A: 1st Place Solution for 2022 Waymo Open Dataset Challenge -- Motion Prediction
Sep 20, 2022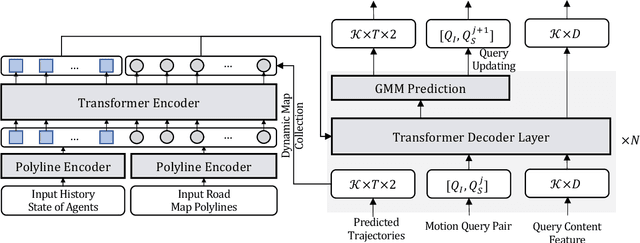
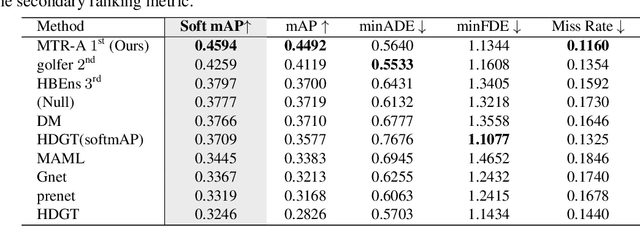
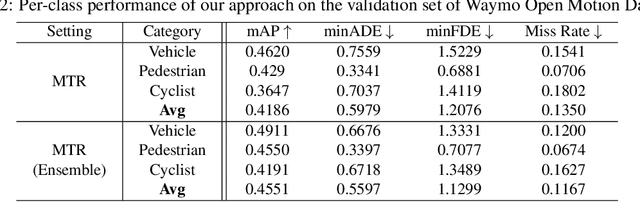
In this report, we present the 1st place solution for motion prediction track in 2022 Waymo Open Dataset Challenges. We propose a novel Motion Transformer framework for multimodal motion prediction, which introduces a small set of novel motion query pairs for generating better multimodal future trajectories by jointly performing the intention localization and iterative motion refinement. A simple model ensemble strategy with non-maximum-suppression is adopted to further boost the final performance. Our approach achieves the 1st place on the motion prediction leaderboard of 2022 Waymo Open Dataset Challenges, outperforming other methods with remarkable margins. Code will be available at https://github.com/sshaoshuai/MTR.
3D Object Detection for Autonomous Driving: A Review and New Outlooks
Jun 19, 2022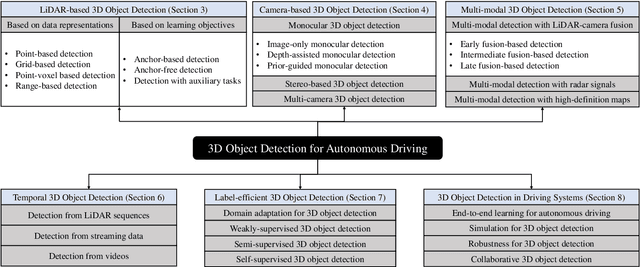
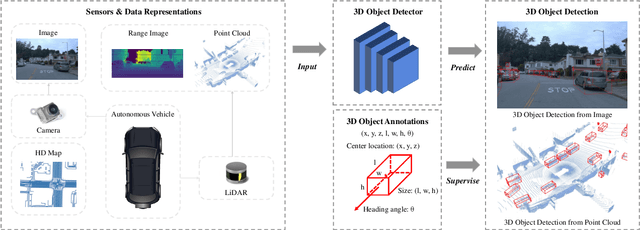
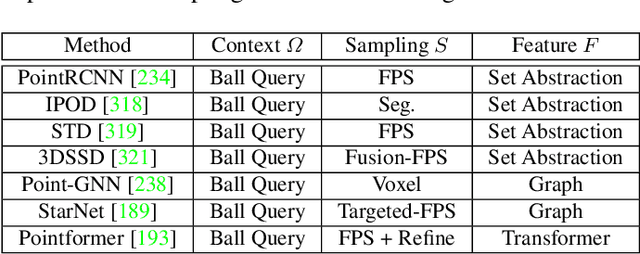
Autonomous driving, in recent years, has been receiving increasing attention for its potential to relieve drivers' burdens and improve the safety of driving. In modern autonomous driving pipelines, the perception system is an indispensable component, aiming to accurately estimate the status of surrounding environments and provide reliable observations for prediction and planning. 3D object detection, which intelligently predicts the locations, sizes, and categories of the critical 3D objects near an autonomous vehicle, is an important part of a perception system. This paper reviews the advances in 3D object detection for autonomous driving. First, we introduce the background of 3D object detection and discuss the challenges in this task. Second, we conduct a comprehensive survey of the progress in 3D object detection from the aspects of models and sensory inputs, including LiDAR-based, camera-based, and multi-modal detection approaches. We also provide an in-depth analysis of the potentials and challenges in each category of methods. Additionally, we systematically investigate the applications of 3D object detection in driving systems. Finally, we conduct a performance analysis of the 3D object detection approaches, and we further summarize the research trends over the years and prospect the future directions of this area.
Towards Efficient 3D Object Detection with Knowledge Distillation
May 30, 2022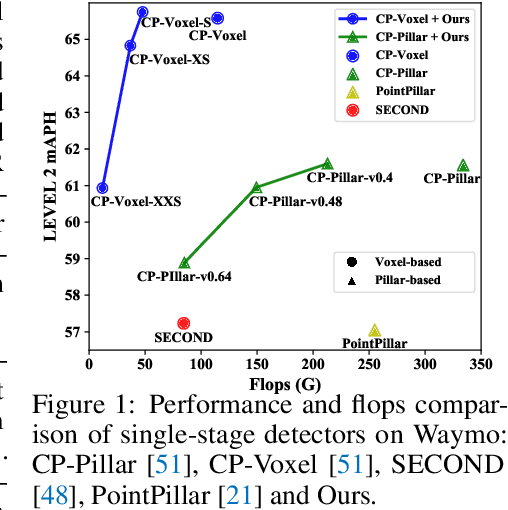
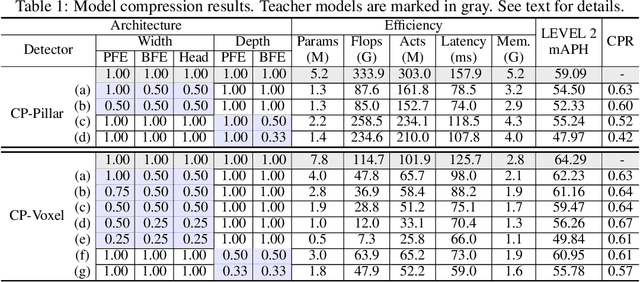

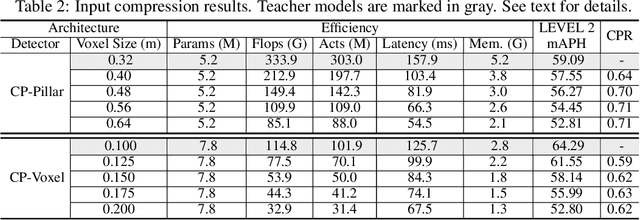
Despite substantial progress in 3D object detection, advanced 3D detectors often suffer from heavy computation overheads. To this end, we explore the potential of knowledge distillation (KD) for developing efficient 3D object detectors, focusing on popular pillar- and voxel-based detectors.Without well-developed teacher-student pairs, we first study how to obtain student models with good trade offs between accuracy and efficiency from the perspectives of model compression and input resolution reduction. Then, we build a benchmark to assess existing KD methods developed in the 2D domain for 3D object detection upon six well-constructed teacher-student pairs. Further, we propose an improved KD pipeline incorporating an enhanced logit KD method that performs KD on only a few pivotal positions determined by teacher classification response, and a teacher-guided student model initialization to facilitate transferring teacher model's feature extraction ability to students through weight inheritance. Finally, we conduct extensive experiments on the Waymo dataset. Our best performing model achieves $65.75\%$ LEVEL 2 mAPH, surpassing its teacher model and requiring only $44\%$ of teacher flops. Our most efficient model runs 51 FPS on an NVIDIA A100, which is $2.2\times$ faster than PointPillar with even higher accuracy. Code will be available.
MPPNet: Multi-Frame Feature Intertwining with Proxy Points for 3D Temporal Object Detection
May 12, 2022
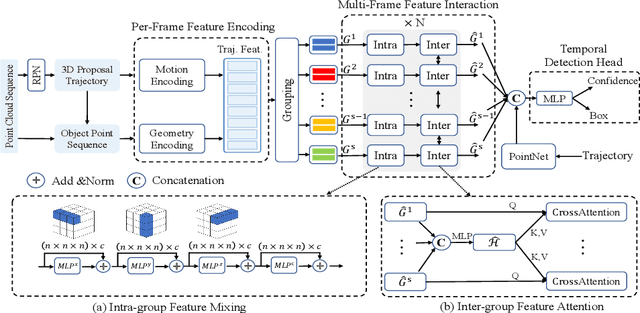
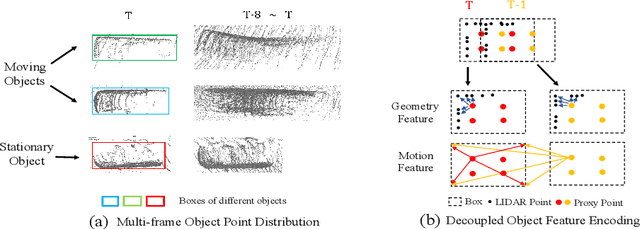
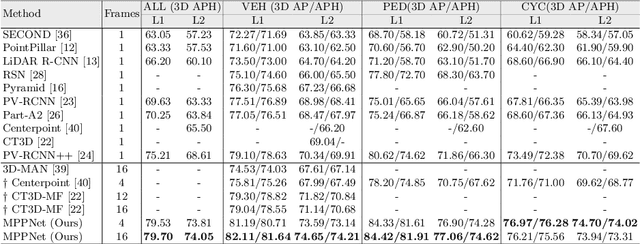
Accurate and reliable 3D detection is vital for many applications including autonomous driving vehicles and service robots. In this paper, we present a flexible and high-performance 3D detection framework, named MPPNet, for 3D temporal object detection with point cloud sequences. We propose a novel three-hierarchy framework with proxy points for multi-frame feature encoding and interactions to achieve better detection. The three hierarchies conduct per-frame feature encoding, short-clip feature fusion, and whole-sequence feature aggregation, respectively. To enable processing long-sequence point clouds with reasonable computational resources, intra-group feature mixing and inter-group feature attention are proposed to form the second and third feature encoding hierarchies, which are recurrently applied for aggregating multi-frame trajectory features. The proxy points not only act as consistent object representations for each frame, but also serve as the courier to facilitate feature interaction between frames. The experiments on largeWaymo Open dataset show that our approach outperforms state-of-the-art methods with large margins when applied to both short (e.g., 4-frame) and long (e.g., 16-frame) point cloud sequences. Specifically, MPPNet achieves 74.21%, 74.62% and 73.31% for vehicle, pedestrian and cyclist classes on the LEVEL 2 mAPH metric with 16-frame input.
RBGNet: Ray-based Grouping for 3D Object Detection
Apr 05, 2022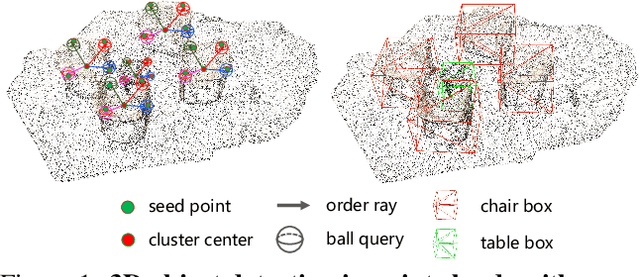

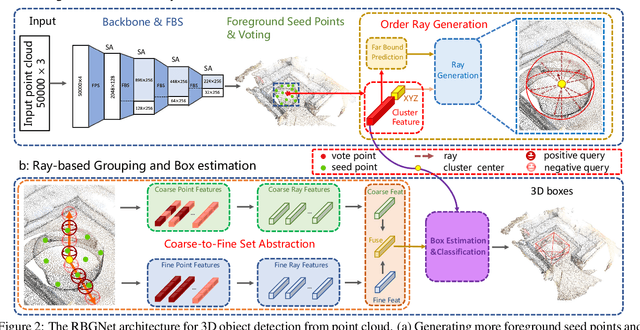
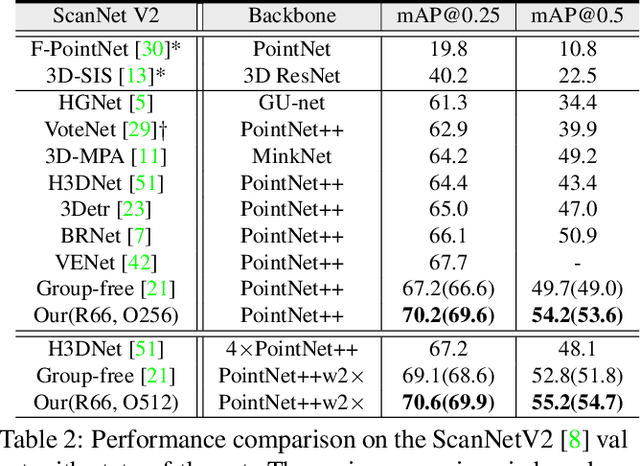
As a fundamental problem in computer vision, 3D object detection is experiencing rapid growth. To extract the point-wise features from the irregularly and sparsely distributed points, previous methods usually take a feature grouping module to aggregate the point features to an object candidate. However, these methods have not yet leveraged the surface geometry of foreground objects to enhance grouping and 3D box generation. In this paper, we propose the RBGNet framework, a voting-based 3D detector for accurate 3D object detection from point clouds. In order to learn better representations of object shape to enhance cluster features for predicting 3D boxes, we propose a ray-based feature grouping module, which aggregates the point-wise features on object surfaces using a group of determined rays uniformly emitted from cluster centers. Considering the fact that foreground points are more meaningful for box estimation, we design a novel foreground biased sampling strategy in downsample process to sample more points on object surfaces and further boost the detection performance. Our model achieves state-of-the-art 3D detection performance on ScanNet V2 and SUN RGB-D with remarkable performance gains. Code will be available at https://github.com/Haiyang-W/RBGNet.
Guided Point Contrastive Learning for Semi-supervised Point Cloud Semantic Segmentation
Oct 15, 2021
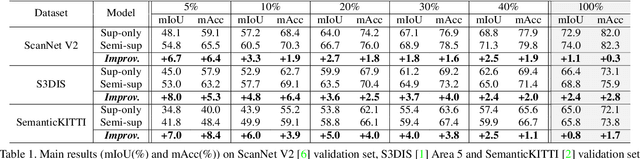
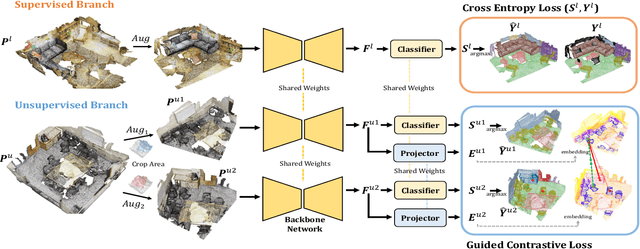
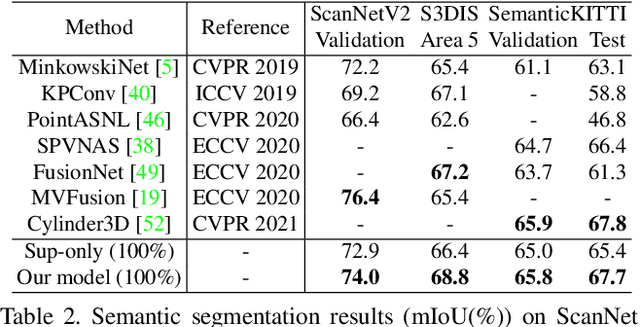
Rapid progress in 3D semantic segmentation is inseparable from the advances of deep network models, which highly rely on large-scale annotated data for training. To address the high cost and challenges of 3D point-level labeling, we present a method for semi-supervised point cloud semantic segmentation to adopt unlabeled point clouds in training to boost the model performance. Inspired by the recent contrastive loss in self-supervised tasks, we propose the guided point contrastive loss to enhance the feature representation and model generalization ability in semi-supervised setting. Semantic predictions on unlabeled point clouds serve as pseudo-label guidance in our loss to avoid negative pairs in the same category. Also, we design the confidence guidance to ensure high-quality feature learning. Besides, a category-balanced sampling strategy is proposed to collect positive and negative samples to mitigate the class imbalance problem. Extensive experiments on three datasets (ScanNet V2, S3DIS, and SemanticKITTI) show the effectiveness of our semi-supervised method to improve the prediction quality with unlabeled data.
LIGA-Stereo: Learning LiDAR Geometry Aware Representations for Stereo-based 3D Detector
Aug 18, 2021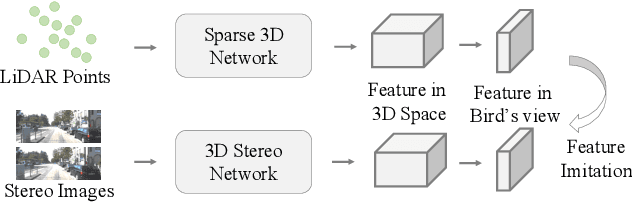
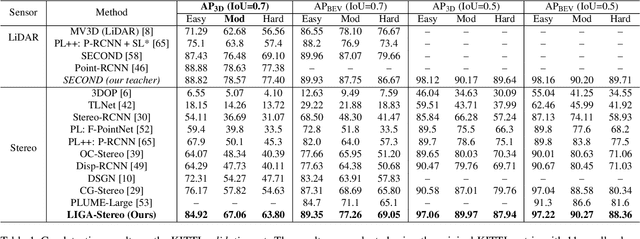
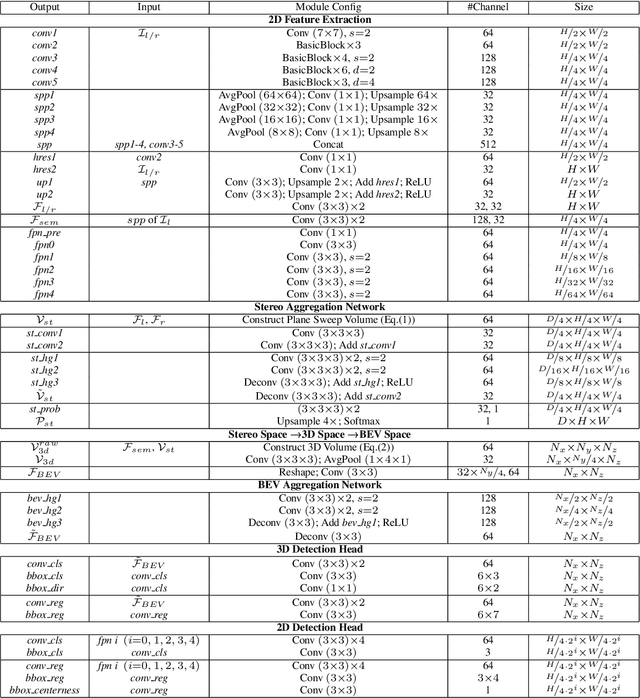
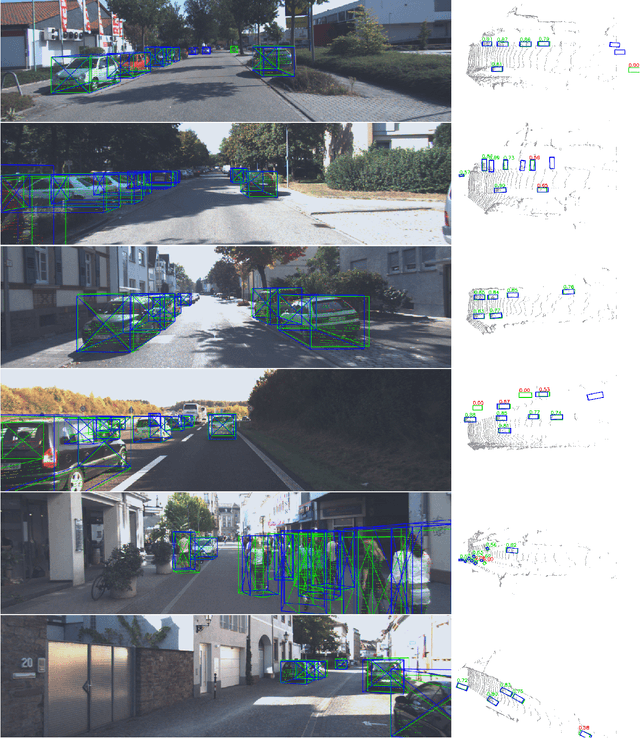
Stereo-based 3D detection aims at detecting 3D object bounding boxes from stereo images using intermediate depth maps or implicit 3D geometry representations, which provides a low-cost solution for 3D perception. However, its performance is still inferior compared with LiDAR-based detection algorithms. To detect and localize accurate 3D bounding boxes, LiDAR-based models can encode accurate object boundaries and surface normal directions from LiDAR point clouds. However, the detection results of stereo-based detectors are easily affected by the erroneous depth features due to the limitation of stereo matching. To solve the problem, we propose LIGA-Stereo (LiDAR Geometry Aware Stereo Detector) to learn stereo-based 3D detectors under the guidance of high-level geometry-aware representations of LiDAR-based detection models. In addition, we found existing voxel-based stereo detectors failed to learn semantic features effectively from indirect 3D supervisions. We attach an auxiliary 2D detection head to provide direct 2D semantic supervisions. Experiment results show that the above two strategies improved the geometric and semantic representation capabilities. Compared with the state-of-the-art stereo detector, our method has improved the 3D detection performance of cars, pedestrians, cyclists by 10.44%, 5.69%, 5.97% mAP respectively on the official KITTI benchmark. The gap between stereo-based and LiDAR-based 3D detectors is further narrowed.