 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegVoxelNet: Exploring Semantic Context and Depth-aware Features for 3D Vehicle Detection from Point Cloud
Paper and Code
Feb 13, 2020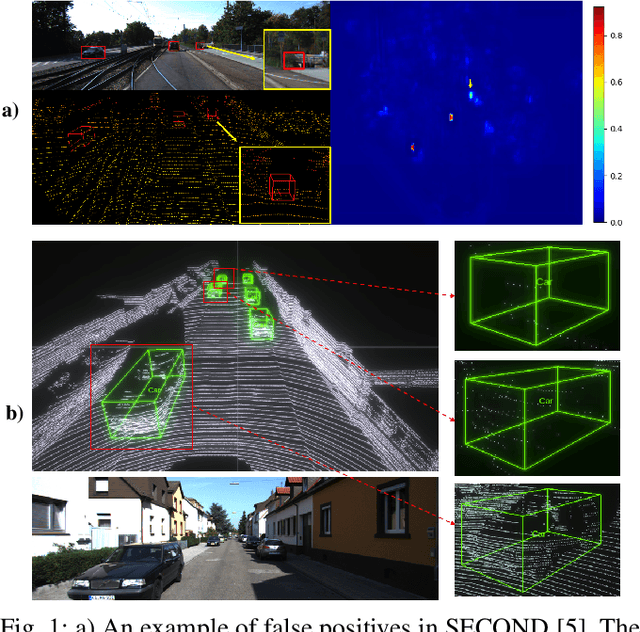
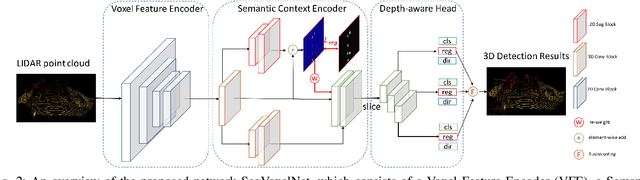


3D vehicle detection based on point cloud is a challenging task in real-world applications such as autonomous driving. Despite significant progress has been made, we observe two aspects to be further improved. First, the semantic context information in LiDAR is seldom explored in previous works, which may help identify ambiguous vehicles. Second, the distribution of point cloud on vehicles varies continuously with increasing depths, which may not be well modeled by a single model. In this work, we propose a unified model SegVoxelNet to address the above two problems. A semantic context encoder is proposed to leverage the free-of-charge semantic segmentation masks in the bird's eye view. Suspicious regions could be highlighted while noisy regions are suppressed by this module. To better deal with vehicles at different depths, a novel depth-aware head is designed to explicitly model the distribution differences and each part of the depth-aware head is made to focus on its own target detection range. Extensive experiments on the KITTI dataset show that the proposed method outperforms the state-of-the-art alternatives in both accuracy and efficiency with point cloud as input only.