 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning
Aug 07, 2023



StarCraft II is one of the most challenging simulated reinforcement learning environments; it is partially observable, stochastic, multi-agent, and mastering StarCraft II requires strategic planning over long time horizons with real-time low-level execution. It also has an active professional competitive scene. StarCraft II is uniquely suited for advancing offline RL algorithms, both because of its challenging nature and because Blizzard has released a massive dataset of millions of StarCraft II games played by human players. This paper leverages that and establishes a benchmark, called AlphaStar Unplugged, introducing unprecedented challenges for offline reinforcement learning. We define a dataset (a subset of Blizzard's release), tools standardizing an API for machine learning methods, and an evaluation protocol. We also present baseline agents, including behavior cloning, offline variants of actor-critic and MuZero. We improve the state of the art of agents using only offline data, and we achieve 90% win rate against previously published AlphaStar behavior cloning agent.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
Regularized Behavior Value Estimation
Mar 17, 2021
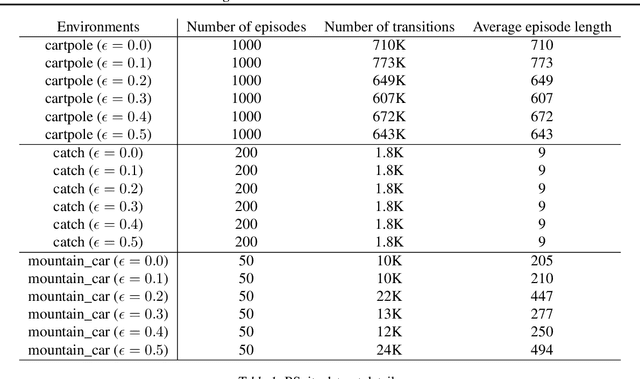
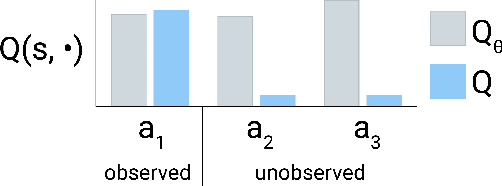
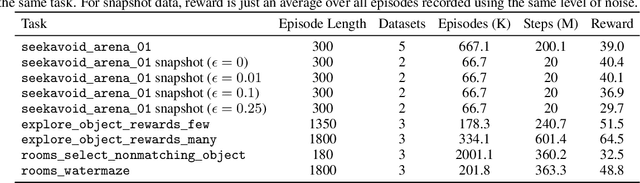
Offline reinforcement learning restricts the learning process to rely only on logged-data without access to an environment. While this enables real-world applications, it also poses unique challenges. One important challenge is dealing with errors caused by the overestimation of values for state-action pairs not well-covered by the training data. Due to bootstrapping, these errors get amplified during training and can lead to divergence, thereby crippling learning. To overcome this challenge, we introduce Regularized Behavior Value Estimation (R-BVE). Unlike most approaches, which use policy improvement during training, R-BVE estimates the value of the behavior policy during training and only performs policy improvement at deployment time. Further, R-BVE uses a ranking regularisation term that favours actions in the dataset that lead to successful outcomes. We provide ample empirical evidence of R-BVE's effectiveness, including state-of-the-art performance on the RL Unplugged ATARI dataset. We also test R-BVE on new datasets, from bsuite and a challenging DeepMind Lab task, and show that R-BVE outperforms other state-of-the-art discrete control offline RL methods.
Acme: A Research Framework for Distributed Reinforcement Learning
Jun 01, 2020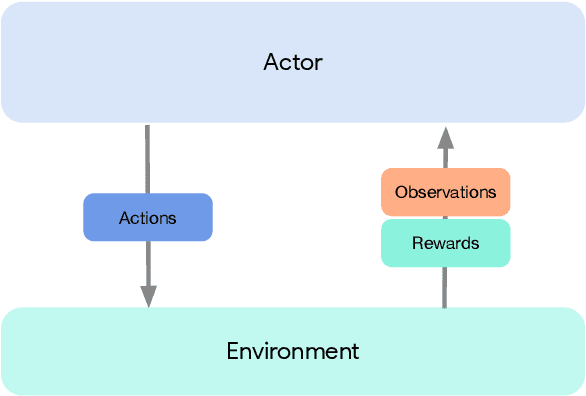
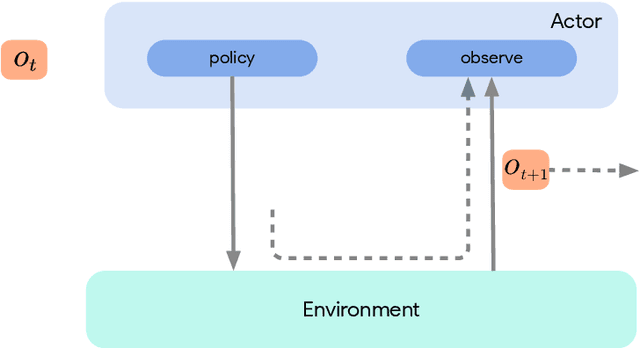
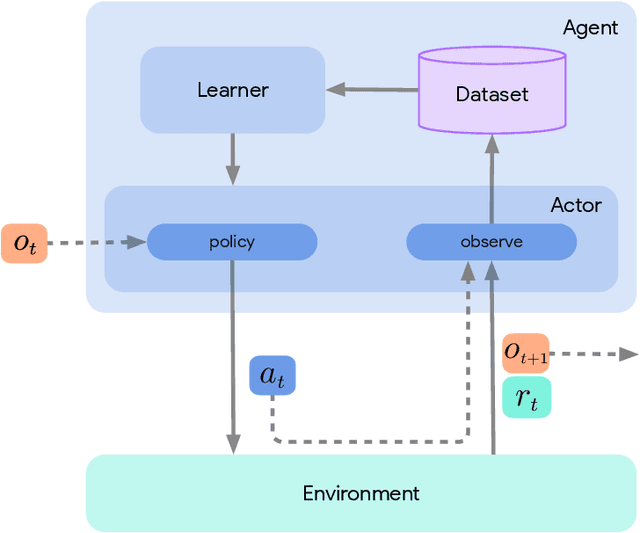
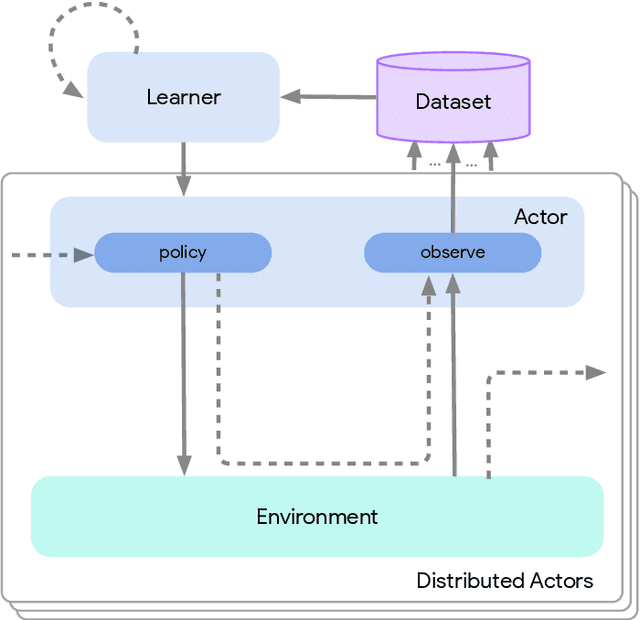
Deep reinforcement learning has led to many recent-and groundbreaking-advancements. However, these advances have often come at the cost of both the scale and complexity of the underlying RL algorithms. Increases in complexity have in turn made it more difficult for researchers to reproduce published RL algorithms or rapidly prototype ideas. To address this, we introduce Acme, a tool to simplify the development of novel RL algorithms that is specifically designed to enable simple agent implementations that can be run at various scales of execution. Our aim is also to make the results of various RL algorithms developed in academia and industrial labs easier to reproduce and extend. To this end we are releasing baseline implementations of various algorithms, created using our framework. In this work we introduce the major design decisions behind Acme and show how these are used to construct these baselines. We also experiment with these agents at different scales of both complexity and computation-including distributed versions. Ultimately, we show that the design decisions behind Acme lead to agents that can be scaled both up and down and that, for the most part, greater levels of parallelization result in agents with equivalent performance, just faster.
A Framework for Data-Driven Robotics
Sep 26, 2019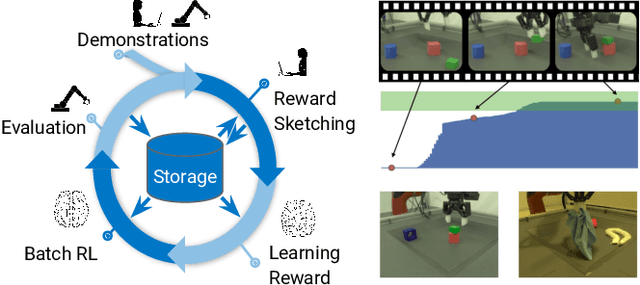
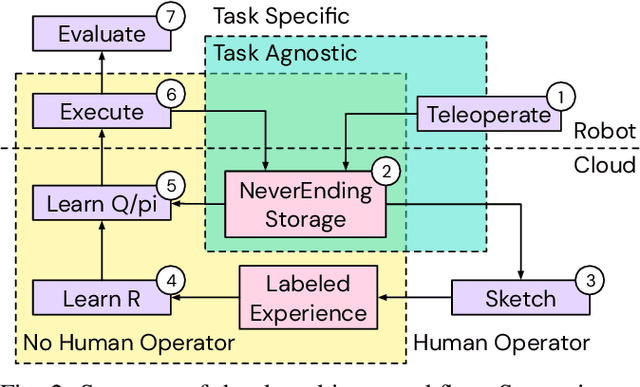
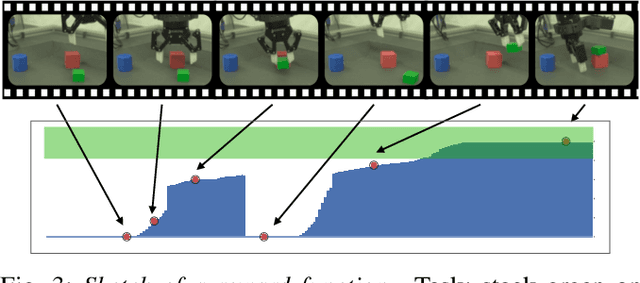
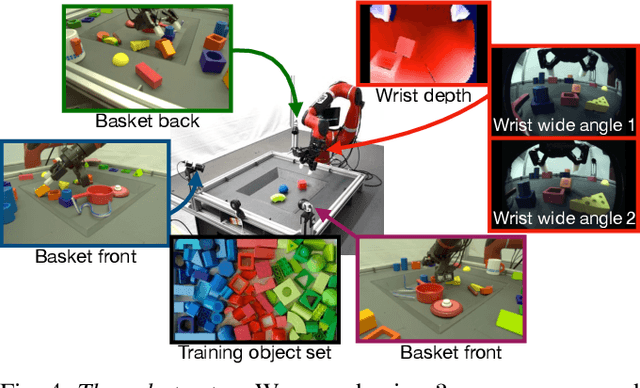
We present a framework for data-driven robotics that makes use of a large dataset of recorded robot experience and scales to several tasks using learned reward functions. We show how to apply this framework to accomplish three different object manipulation tasks on a real robot platform. Given demonstrations of a task together with task-agnostic recorded experience, we use a special form of human annotation as supervision to learn a reward function, which enables us to deal with real-world tasks where the reward signal cannot be acquired directly. Learned rewards are used in combination with a large dataset of experience from different tasks to learn a robot policy offline using batch RL. We show that using our approach it is possible to train agents to perform a variety of challenging manipulation tasks including stacking rigid objects and handling cloth.
TF-Replicator: Distributed Machine Learning for Researchers
Feb 01, 2019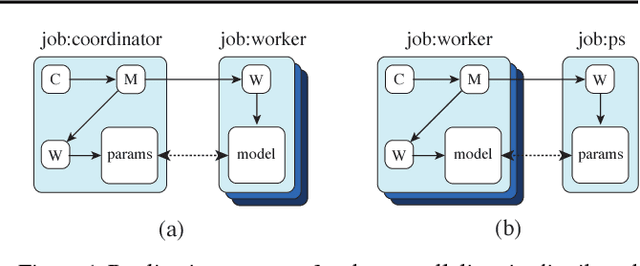

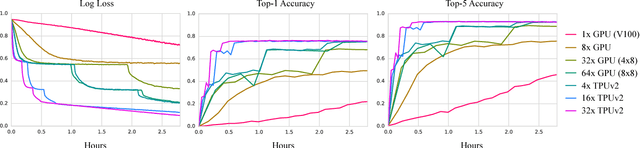
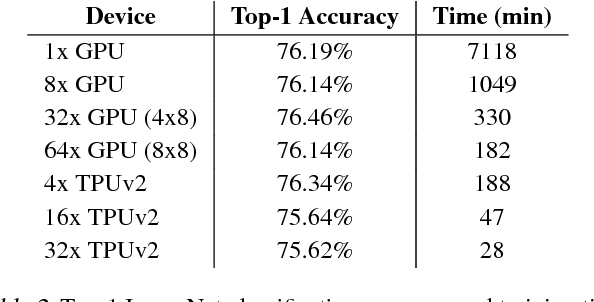
We describe TF-Replicator, a framework for distributed machine learning designed for DeepMind researchers and implemented as an abstraction over TensorFlow. TF-Replicator simplifies writing data-parallel and model-parallel research code. The same models can be effortlessly deployed to different cluster architectures (i.e. one or many machines containing CPUs, GPUs or TPU accelerators) using synchronous or asynchronous training regimes. To demonstrate the generality and scalability of TF-Replicator, we implement and benchmark three very different models: (1) A ResNet-50 for ImageNet classification, (2) a SN-GAN for class-conditional ImageNet image generation, and (3) a D4PG reinforcement learning agent for continuous control. Our results show strong scalability performance without demanding any distributed systems expertise of the user. The TF-Replicator programming model will be open-sourced as part of TensorFlow 2.0 (see https://github.com/tensorflow/community/pull/25).
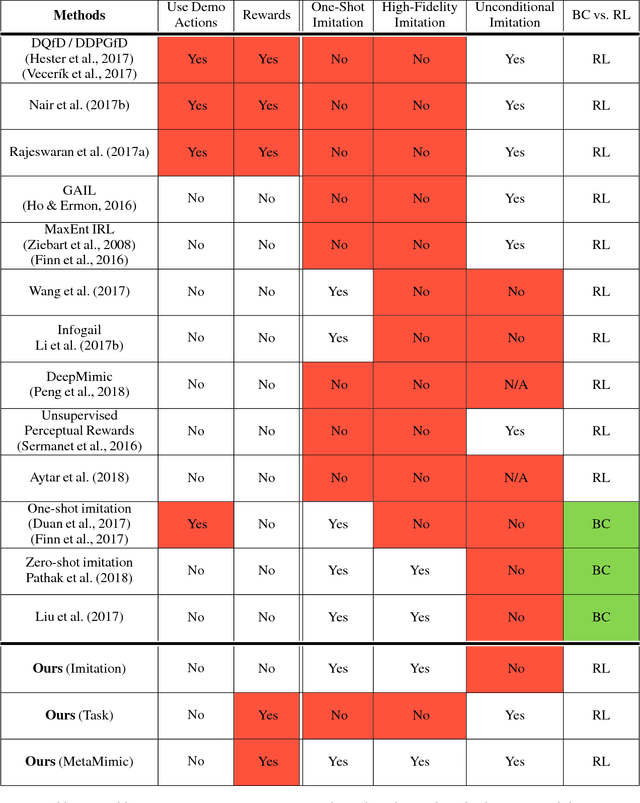
One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets with RL
Oct 11, 2018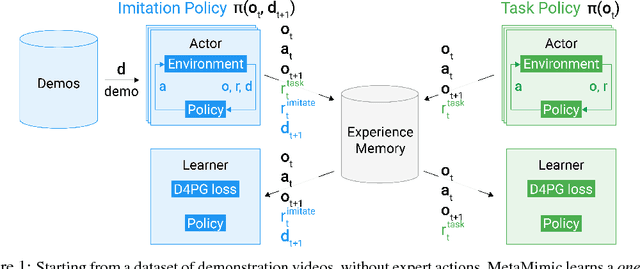
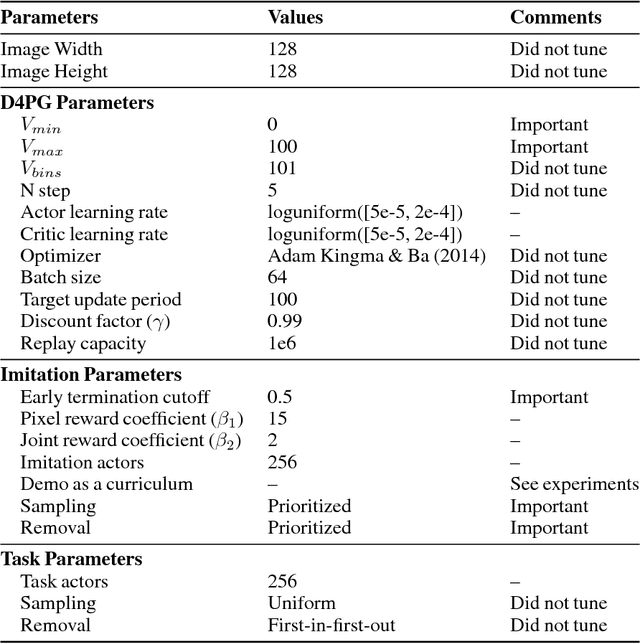
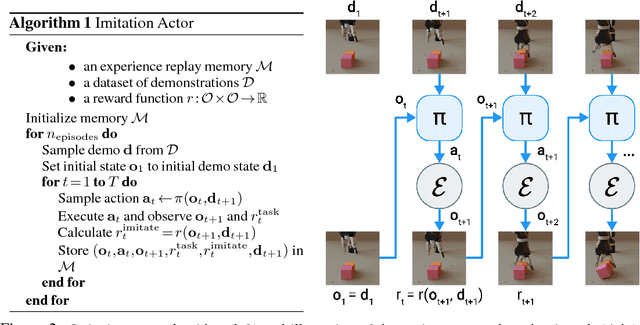
Humans are experts at high-fidelity imitation -- closely mimicking a demonstration, often in one attempt. Humans use this ability to quickly solve a task instance, and to bootstrap learning of new tasks. Achieving these abilities in autonomous agents is an open problem. In this paper, we introduce an off-policy RL algorithm (MetaMimic) to narrow this gap. MetaMimic can learn both (i) policies for high-fidelity one-shot imitation of diverse novel skills, and (ii) policies that enable the agent to solve tasks more efficiently than the demonstrators. MetaMimic relies on the principle of storing all experiences in a memory and replaying these to learn massive deep neural network policies by off-policy RL. This paper introduces, to the best of our knowledge, the largest existing neural networks for deep RL and shows that larger networks with normalization are needed to achieve one-shot high-fidelity imitation on a challenging manipulation task. The results also show that both types of policy can be learned from vision, in spite of the task rewards being sparse, and without access to demonstrator actions.
Learning Awareness Models
Apr 17, 2018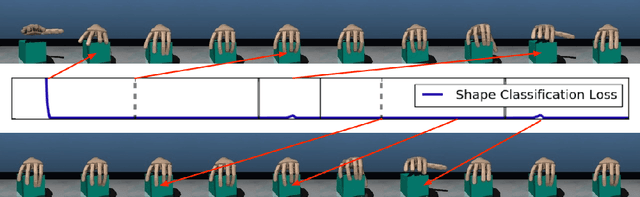

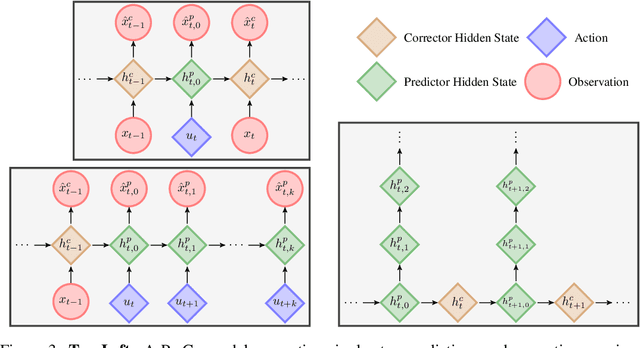
We consider the setting of an agent with a fixed body interacting with an unknown and uncertain external world. We show that models trained to predict proprioceptive information about the agent's body come to represent objects in the external world. In spite of being trained with only internally available signals, these dynamic body models come to represent external objects through the necessity of predicting their effects on the agent's own body. That is, the model learns holistic persistent representations of objects in the world, even though the only training signals are body signals. Our dynamics model is able to successfully predict distributions over 132 sensor readings over 100 steps into the future and we demonstrate that even when the body is no longer in contact with an object, the latent variables of the dynamics model continue to represent its shape. We show that active data collection by maximizing the entropy of predictions about the body---touch sensors, proprioception and vestibular information---leads to learning of dynamic models that show superior performance when used for control. We also collect data from a real robotic hand and show that the same models can be used to answer questions about properties of objects in the real world. Videos with qualitative results of our models are available at https://goo.gl/mZuqAV.
The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously
Jul 11, 2017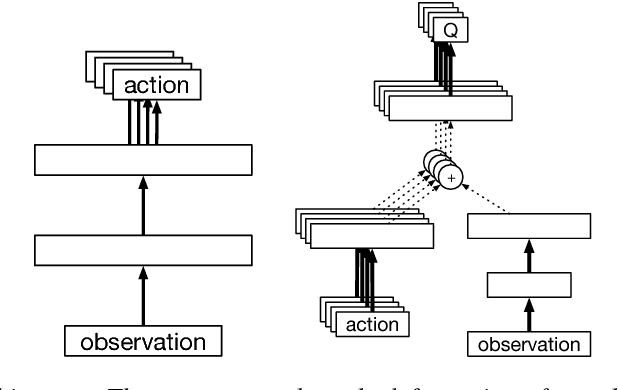

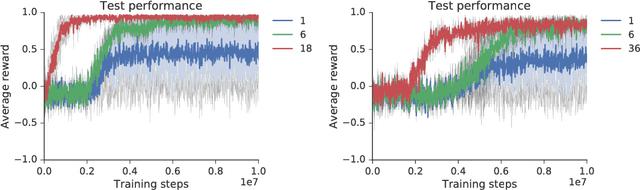
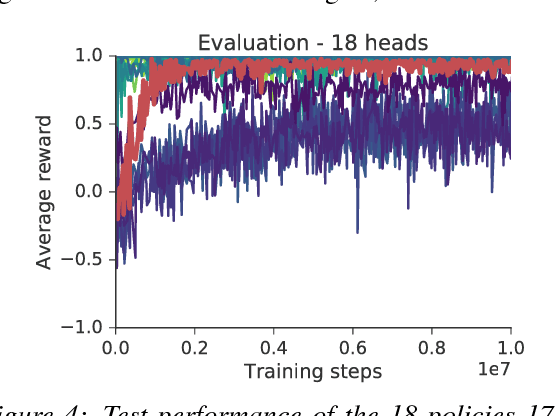
This paper introduces the Intentional Unintentional (IU) agent. This agent endows the deep deterministic policy gradients (DDPG) agent for continuous control with the ability to solve several tasks simultaneously. Learning to solve many tasks simultaneously has been a long-standing, core goal of artificial intelligence, inspired by infant development and motivated by the desire to build flexible robot manipulators capable of many diverse behaviours. We show that the IU agent not only learns to solve many tasks simultaneously but it also learns faster than agents that target a single task at-a-time. In some cases, where the single task DDPG method completely fails, the IU agent successfully solves the task. To demonstrate this, we build a playroom environment using the MuJoCo physics engine, and introduce a grounded formal language to automatically generate tasks.