 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Meta-Learning with Shrinkage
Sep 12, 2019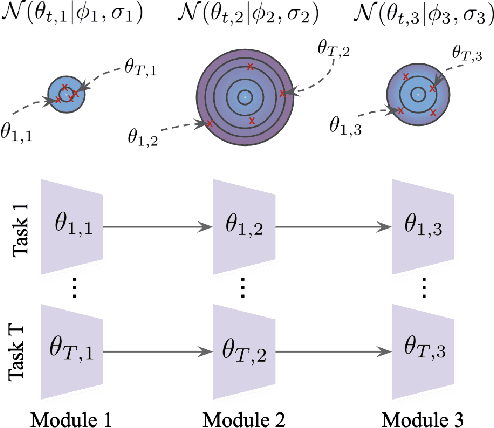
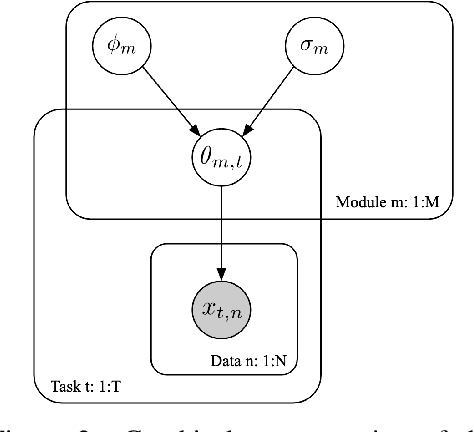
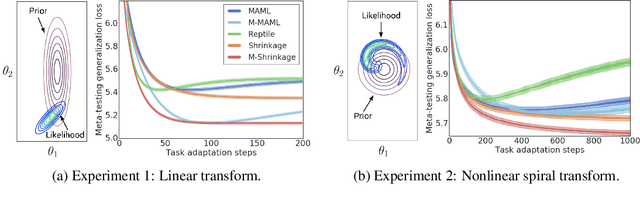
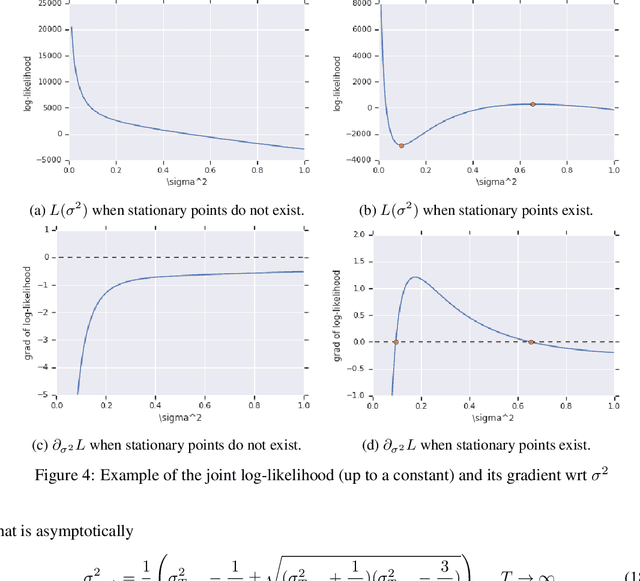
Most gradient-based approaches to meta-learning do not explicitly account for the fact that different parts of the underlying model adapt by different amounts when applied to a new task. For example, the input layers of an image classification convnet typically adapt very little, while the output layers can change significantly. This can cause parts of the model to begin to overfit while others underfit. To address this, we introduce a hierarchical Bayesian model with per-module shrinkage parameters, which we propose to learn by maximizing an approximation of the predictive likelihood using implicit differentiation. Our algorithm subsumes Reptile and outperforms variants of MAML on two synthetic few-shot meta-learning problems.
Large-Scale Visual Speech Recognition
Oct 01, 2018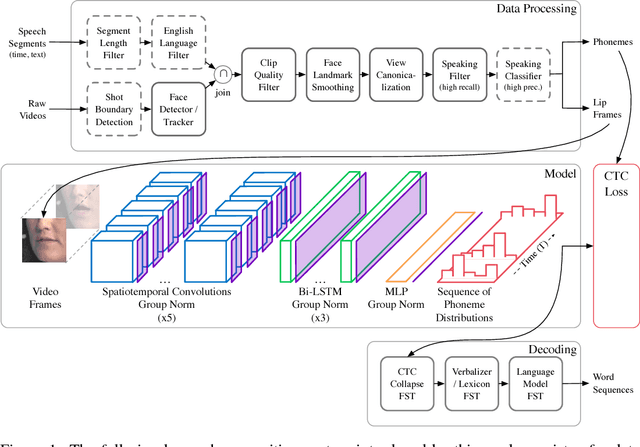
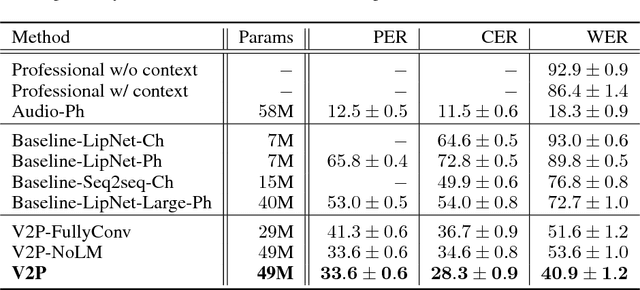


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.
Distributed Distributional Deterministic Policy Gradients
Apr 23, 2018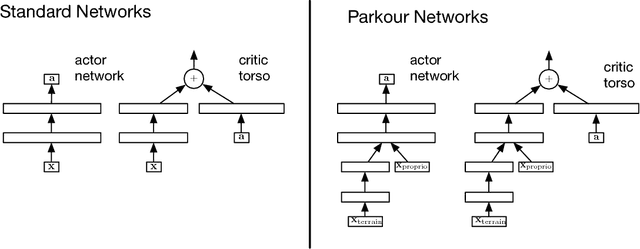
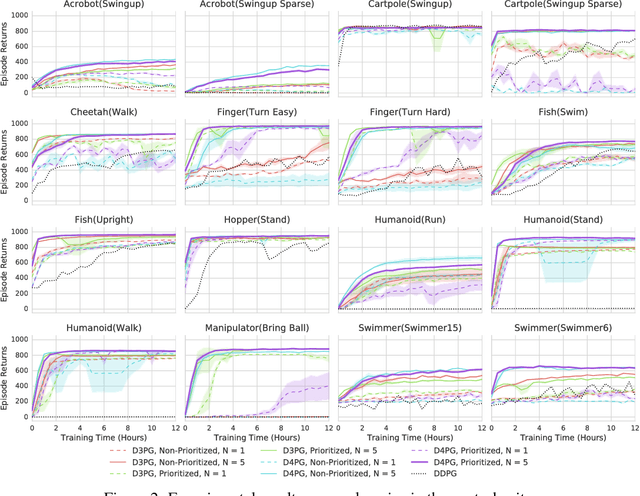
This work adopts the very successful distributional perspective on reinforcement learning and adapts it to the continuous control setting. We combine this within a distributed framework for off-policy learning in order to develop what we call the Distributed Distributional Deep Deterministic Policy Gradient algorithm, D4PG. We also combine this technique with a number of additional, simple improvements such as the use of $N$-step returns and prioritized experience replay. Experimentally we examine the contribution of each of these individual components, and show how they interact, as well as their combined contributions. Our results show that across a wide variety of simple control tasks, difficult manipulation tasks, and a set of hard obstacle-based locomotion tasks the D4PG algorithm achieves state of the art performance.
Learned Optimizers that Scale and Generalize
Sep 07, 2017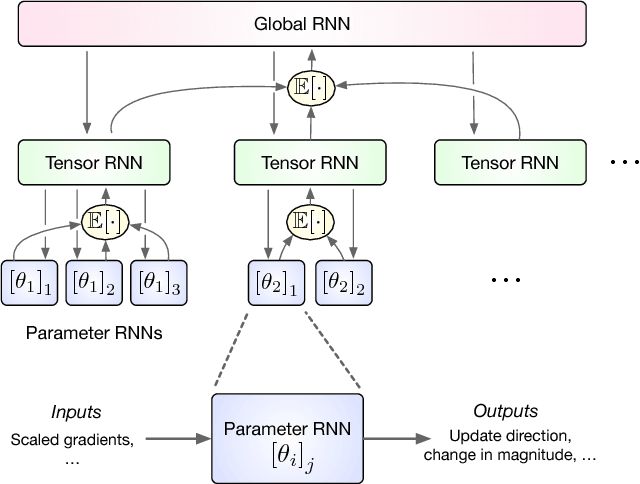
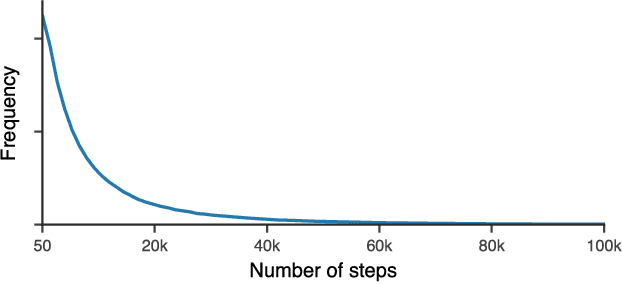
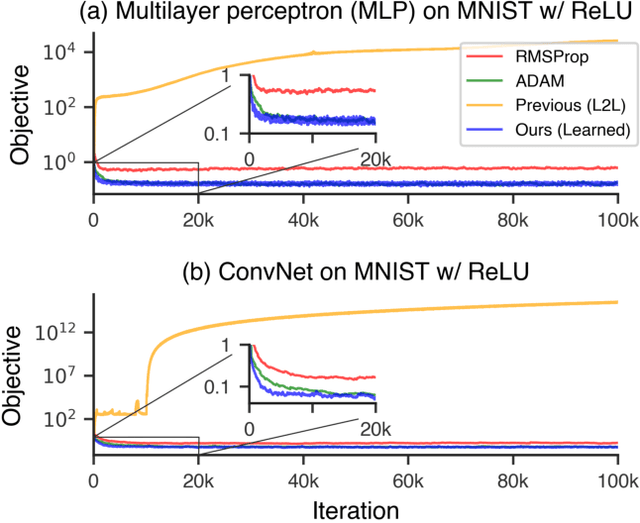
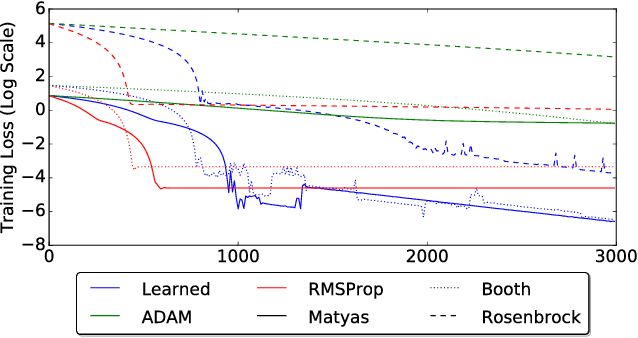
Learning to learn has emerged as an important direction for achieving artificial intelligence. Two of the primary barriers to its adoption are an inability to scale to larger problems and a limited ability to generalize to new tasks. We introduce a learned gradient descent optimizer that generalizes well to new tasks, and which has significantly reduced memory and computation overhead. We achieve this by introducing a novel hierarchical RNN architecture, with minimal per-parameter overhead, augmented with additional architectural features that mirror the known structure of optimization tasks. We also develop a meta-training ensemble of small, diverse optimization tasks capturing common properties of loss landscapes. The optimizer learns to outperform RMSProp/ADAM on problems in this corpus. More importantly, it performs comparably or better when applied to small convolutional neural networks, despite seeing no neural networks in its meta-training set. Finally, it generalizes to train Inception V3 and ResNet V2 architectures on the ImageNet dataset for thousands of steps, optimization problems that are of a vastly different scale than those it was trained on. We release an open source implementation of the meta-training algorithm.
The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously
Jul 11, 2017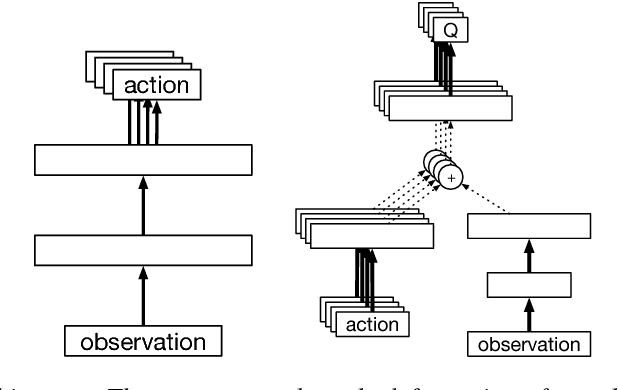

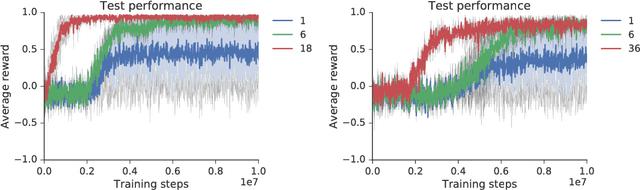
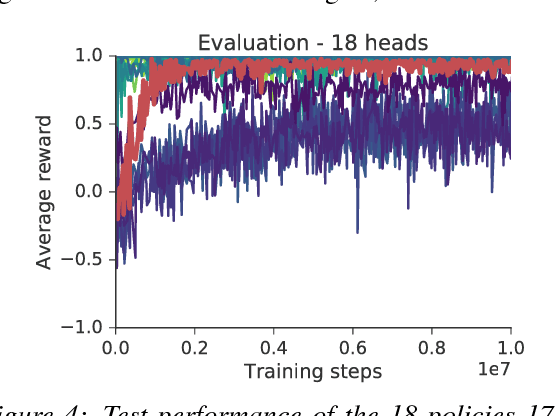
This paper introduces the Intentional Unintentional (IU) agent. This agent endows the deep deterministic policy gradients (DDPG) agent for continuous control with the ability to solve several tasks simultaneously. Learning to solve many tasks simultaneously has been a long-standing, core goal of artificial intelligence, inspired by infant development and motivated by the desire to build flexible robot manipulators capable of many diverse behaviours. We show that the IU agent not only learns to solve many tasks simultaneously but it also learns faster than agents that target a single task at-a-time. In some cases, where the single task DDPG method completely fails, the IU agent successfully solves the task. To demonstrate this, we build a playroom environment using the MuJoCo physics engine, and introduce a grounded formal language to automatically generate tasks.
Learning to Learn without Gradient Descent by Gradient Descent
Jun 12, 2017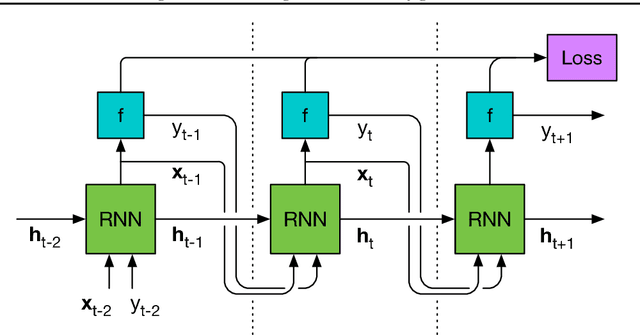
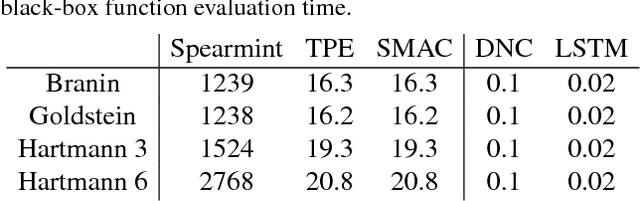
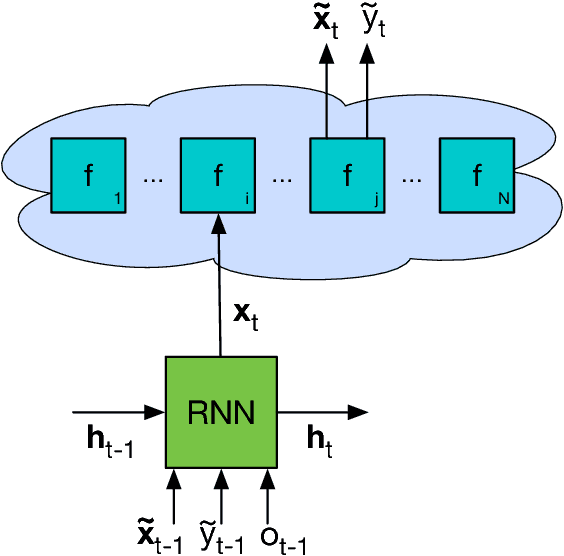
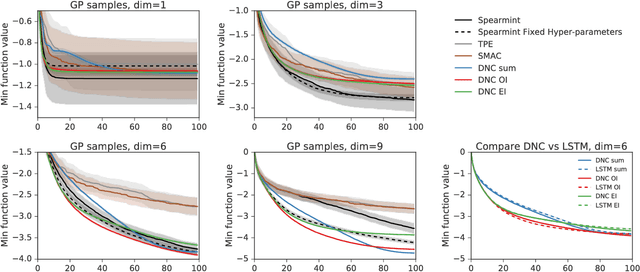
We learn recurrent neural network optimizers trained on simple synthetic functions by gradient descent. We show that these learned optimizers exhibit a remarkable degree of transfer in that they can be used to efficiently optimize a broad range of derivative-free black-box functions, including Gaussian process bandits, simple control objectives, global optimization benchmarks and hyper-parameter tuning tasks. Up to the training horizon, the learned optimizers learn to trade-off exploration and exploitation, and compare favourably with heavily engineered Bayesian optimization packages for hyper-parameter tuning.
Learning to learn by gradient descent by gradient descent
Nov 30, 2016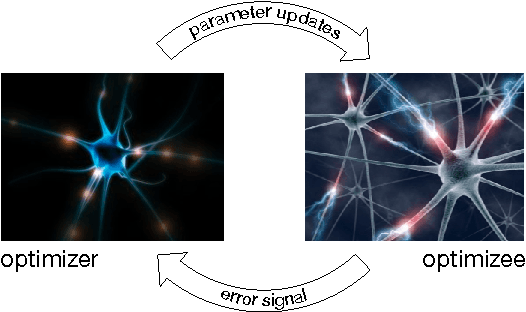
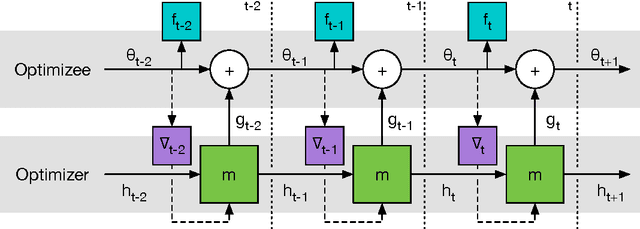
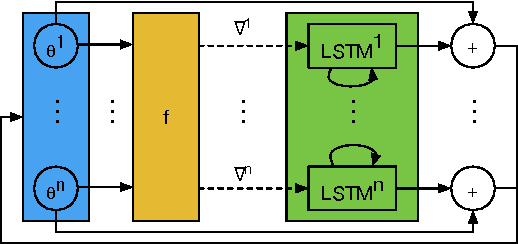
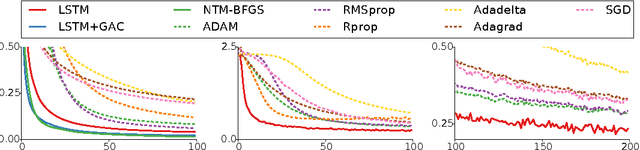
The move from hand-designed features to learned features in machine learning has been wildly successful. In spite of this, optimization algorithms are still designed by hand. In this paper we show how the design of an optimization algorithm can be cast as a learning problem, allowing the algorithm to learn to exploit structure in the problems of interest in an automatic way. Our learned algorithms, implemented by LSTMs, outperform generic, hand-designed competitors on the tasks for which they are trained, and also generalize well to new tasks with similar structure. We demonstrate this on a number of tasks, including simple convex problems, training neural networks, and styling images with neural art.
A General Framework for Constrained Bayesian Optimization using Information-based Search
Sep 04, 2016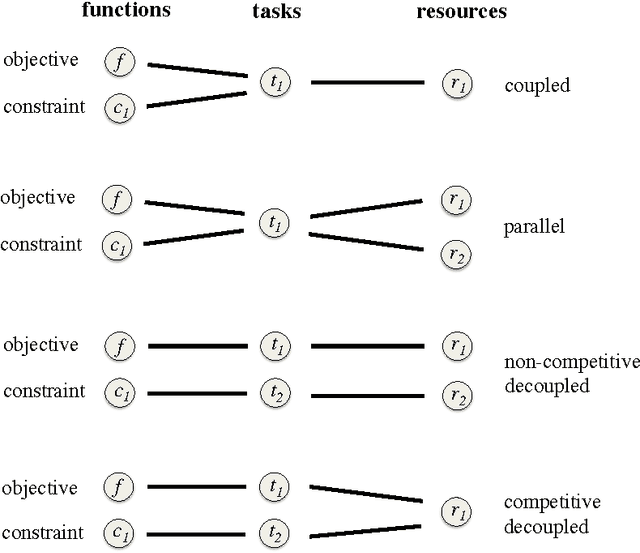
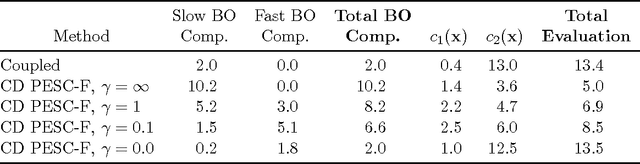
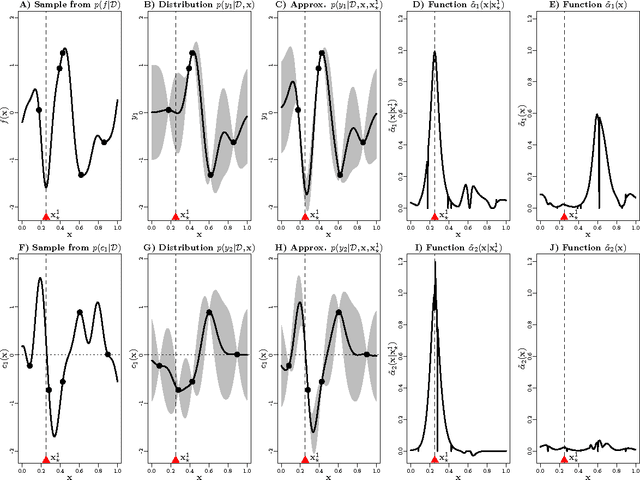
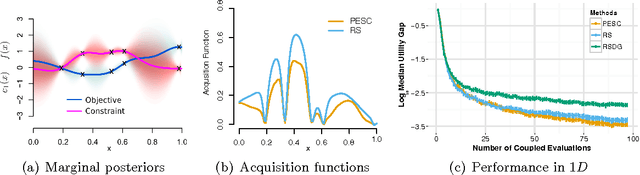
We present an information-theoretic framework for solving global black-box optimization problems that also have black-box constraints. Of particular interest to us is to efficiently solve problems with decoupled constraints, in which subsets of the objective and constraint functions may be evaluated independently. For example, when the objective is evaluated on a CPU and the constraints are evaluated independently on a GPU. These problems require an acquisition function that can be separated into the contributions of the individual function evaluations. We develop one such acquisition function and call it Predictive Entropy Search with Constraints (PESC). PESC is an approximation to the expected information gain criterion and it compares favorably to alternative approaches based on improvement in several synthetic and real-world problems. In addition to this, we consider problems with a mix of functions that are fast and slow to evaluate. These problems require balancing the amount of time spent in the meta-computation of PESC and in the actual evaluation of the target objective. We take a bounded rationality approach and develop partial update for PESC which trades off accuracy against speed. We then propose a method for adaptively switching between the partial and full updates for PESC. This allows us to interpolate between versions of PESC that are efficient in terms of function evaluations and those that are efficient in terms of wall-clock time. Overall, we demonstrate that PESC is an effective algorithm that provides a promising direction towards a unified solution for constrained Bayesian optimization.
Predictive Entropy Search for Bayesian Optimization with Unknown Constraints
Jul 15, 2015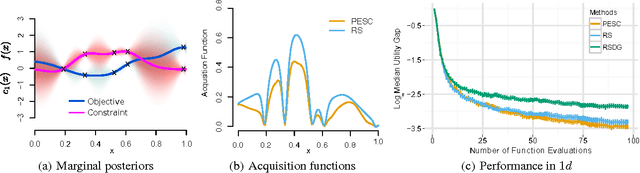
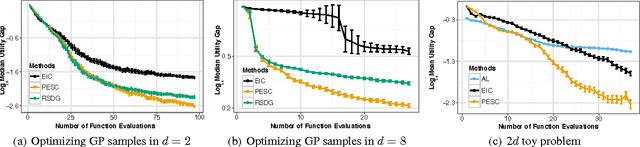
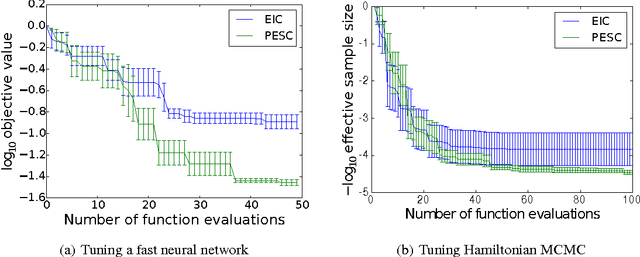
Unknown constraints arise in many types of expensive black-box optimization problems. Several methods have been proposed recently for performing Bayesian optimization with constraints, based on the expected improvement (EI) heuristic. However, EI can lead to pathologies when used with constraints. For example, in the case of decoupled constraints---i.e., when one can independently evaluate the objective or the constraints---EI can encounter a pathology that prevents exploration. Additionally, computing EI requires a current best solution, which may not exist if none of the data collected so far satisfy the constraints. By contrast, information-based approaches do not suffer from these failure modes. In this paper, we present a new information-based method called Predictive Entropy Search with Constraints (PESC). We analyze the performance of PESC and show that it compares favorably to EI-based approaches on synthetic and benchmark problems, as well as several real-world examples. We demonstrate that PESC is an effective algorithm that provides a promising direction towards a unified solution for constrained Bayesian optimization.
An Entropy Search Portfolio for Bayesian Optimization
Mar 04, 2015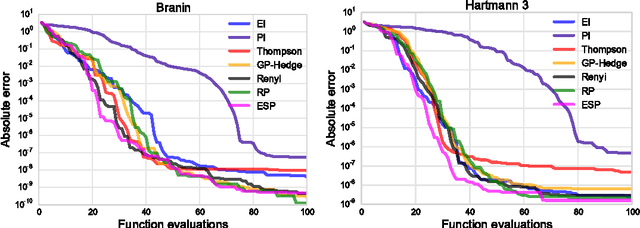
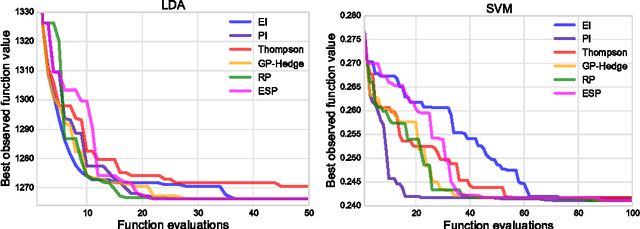
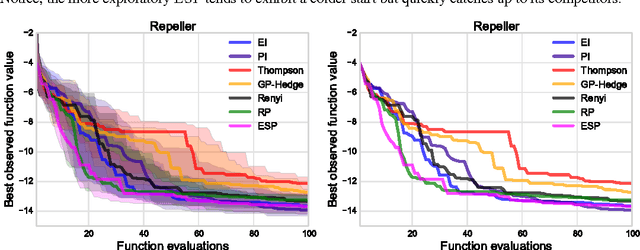
Bayesian optimization is a sample-efficient method for black-box global optimization. How- ever, the performance of a Bayesian optimization method very much depends on its exploration strategy, i.e. the choice of acquisition function, and it is not clear a priori which choice will result in superior performance. While portfolio methods provide an effective, principled way of combining a collection of acquisition functions, they are often based on measures of past performance which can be misleading. To address this issue, we introduce the Entropy Search Portfolio (ESP): a novel approach to portfolio construction which is motivated by information theoretic considerations. We show that ESP outperforms existing portfolio methods on several real and synthetic problems, including geostatistical datasets and simulated control tasks. We not only show that ESP is able to offer performance as good as the best, but unknown, acquisition function, but surprisingly it often gives better performance. Finally, over a wide range of conditions we find that ESP is robust to the inclusion of poor acquisition functions.