 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Should an Agent Practice?
Dec 15, 2019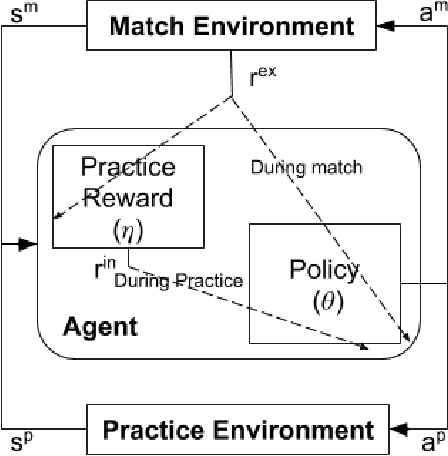
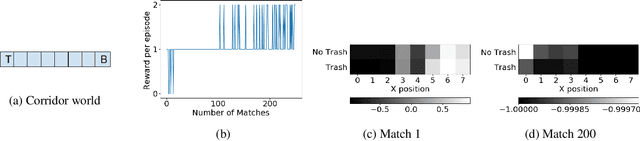
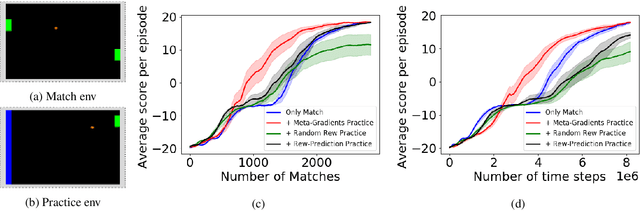
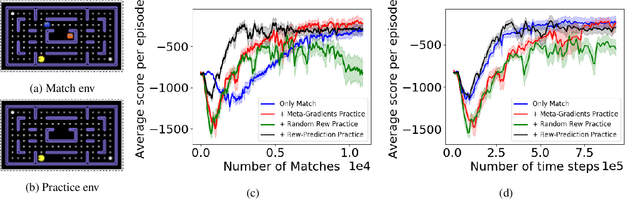
We present a method for learning intrinsic reward functions to drive the learning of an agent during periods of practice in which extrinsic task rewards are not available. During practice, the environment may differ from the one available for training and evaluation with extrinsic rewards. We refer to this setup of alternating periods of practice and objective evaluation as practice-match, drawing an analogy to regimes of skill acquisition common for humans in sports and games. The agent must effectively use periods in the practice environment so that performance improves during matches. In the proposed method the intrinsic practice reward is learned through a meta-gradient approach that adapts the practice reward parameters to reduce the extrinsic match reward loss computed from matches. We illustrate the method on a simple grid world, and evaluate it in two games in which the practice environment differs from match: Pong with practice against a wall without an opponent, and PacMan with practice in a maze without ghosts. The results show gains from learning in practice in addition to match periods over learning in matches only.
What Can Learned Intrinsic Rewards Capture?
Dec 11, 2019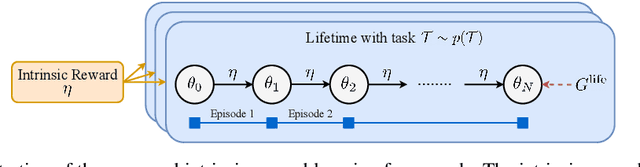
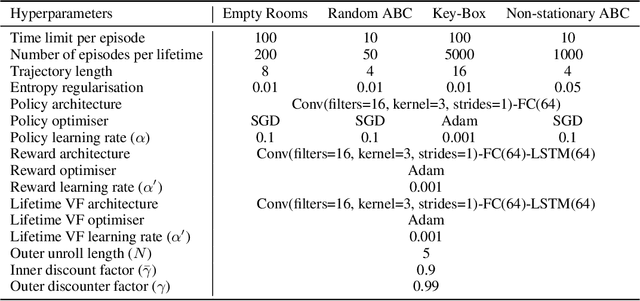
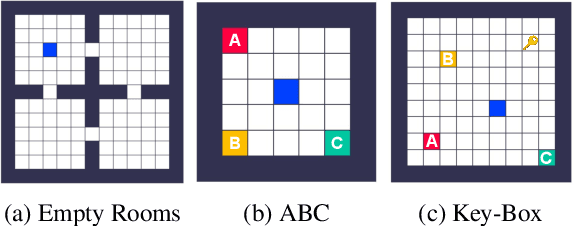
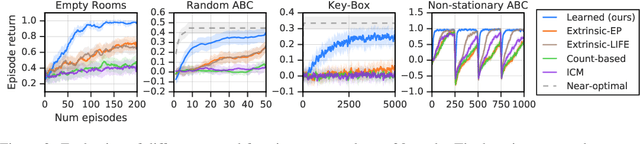
Reinforcement learning agents can include different components, such as policies, value functions, state representations, and environment models. Any or all of these can be the loci of knowledge, i.e., structures where knowledge, whether given or learned, can be deposited and reused. The objective of an agent is to behave so as to maximise the sum of a suitable scalar function of state: the reward. As far as the learning algorithm is concerned, these rewards are typically given and immutable. In this paper we instead consider the proposition that the reward function itself may be a good locus of knowledge. This is consistent with a common use, in the literature, of hand-designed intrinsic rewards to improve the learning dynamics of an agent. We adopt the multi-lifetime setting of the Optimal Rewards Framework, and propose to meta-learn an intrinsic reward function from experience that allows agents to maximise their extrinsic rewards accumulated until the end of their lifetimes. Rewards as a locus of knowledge provide guidance on "what" the agent should strive to do rather than "how" the agent should behave; the latter is more directly captured in policies or value functions for example. Thus, our focus here is on demonstrating the following: (1) that it is feasible to meta-learn good reward functions, (2) that the learned reward functions can capture interesting kinds of "what" knowledge, and (3) that because of the indirectness of this form of knowledge the learned reward functions can generalise to other kinds of agents and to changes in the dynamics of the environment.
Hindsight Credit Assignment
Dec 05, 2019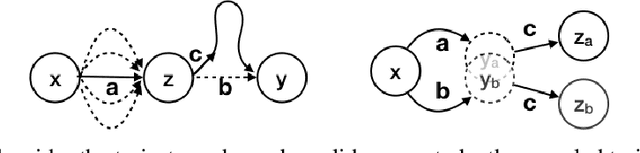

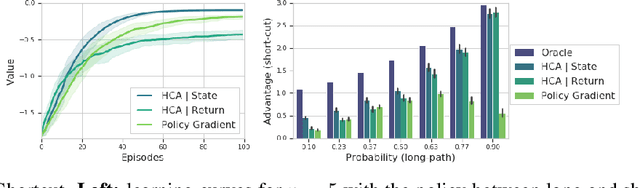
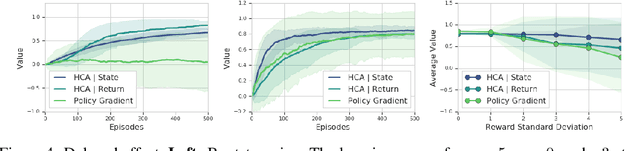
We consider the problem of efficient credit assignment in reinforcement learning. In order to efficiently and meaningfully utilize new data, we propose to explicitly assign credit to past decisions based on the likelihood of them having led to the observed outcome. This approach uses new information in hindsight, rather than employing foresight. Somewhat surprisingly, we show that value functions can be rewritten through this lens, yielding a new family of algorithms. We study the properties of these algorithms, and empirically show that they successfully address important credit assignment challenges, through a set of illustrative tasks.
Deep Reinforcement Learning for Multi-Driver Vehicle Dispatching and Repositioning Problem
Nov 25, 2019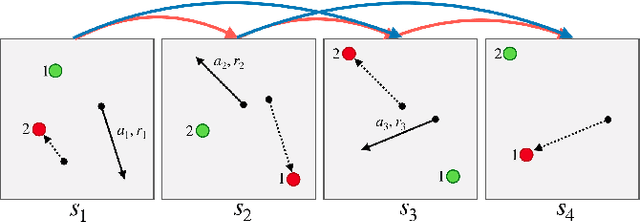
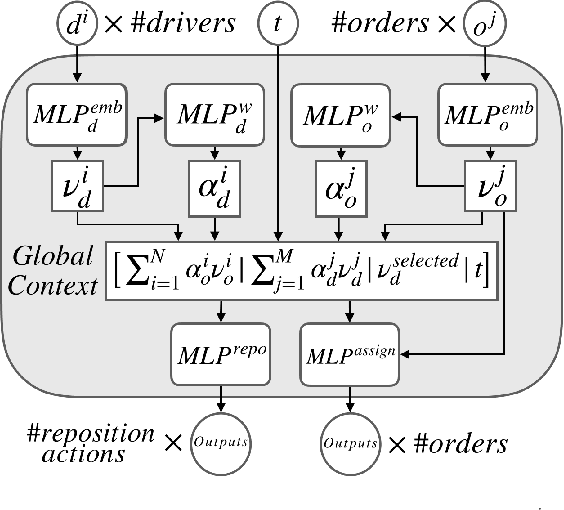
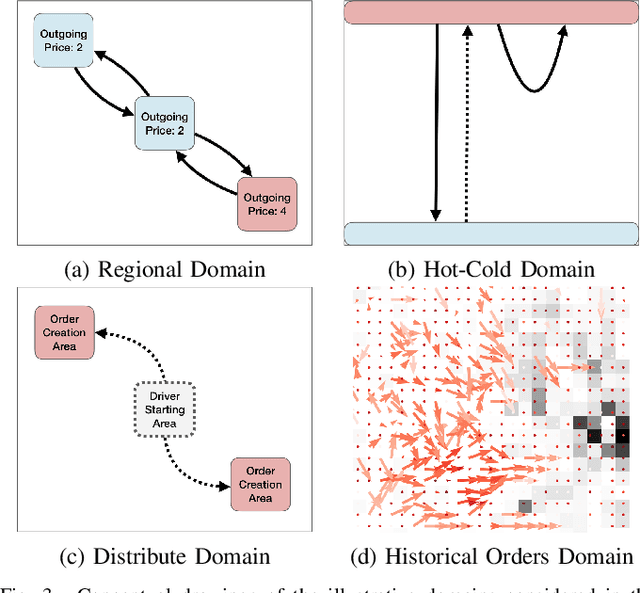
Order dispatching and driver repositioning (also known as fleet management) in the face of spatially and temporally varying supply and demand are central to a ride-sharing platform marketplace. Hand-crafting heuristic solutions that account for the dynamics in these resource allocation problems is difficult, and may be better handled by an end-to-end machine learning method. Previous works have explored machine learning methods to the problem from a high-level perspective, where the learning method is responsible for either repositioning the drivers or dispatching orders, and as a further simplification, the drivers are considered independent agents maximizing their own reward functions. In this paper we present a deep reinforcement learning approach for tackling the full fleet management and dispatching problems. In addition to treating the drivers as individual agents, we consider the problem from a system-centric perspective, where a central fleet management agent is responsible for decision-making for all drivers.
Disentangled Cumulants Help Successor Representations Transfer to New Tasks
Nov 25, 2019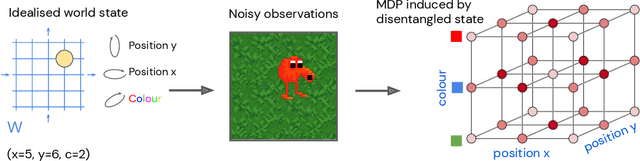
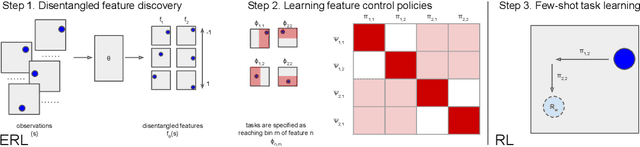
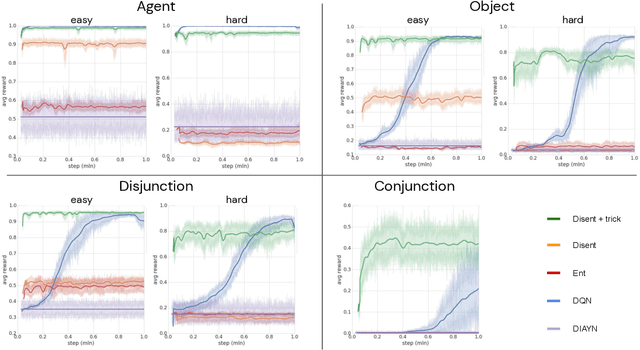
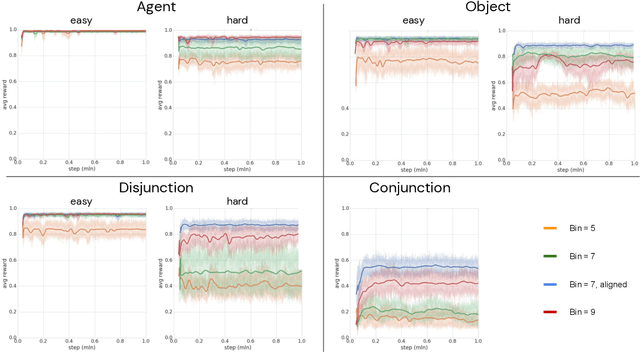
Biological intelligence can learn to solve many diverse tasks in a data efficient manner by re-using basic knowledge and skills from one task to another. Furthermore, many of such skills are acquired without explicit supervision in an intrinsically driven fashion. This is in contrast to the state-of-the-art reinforcement learning agents, which typically start learning each new task from scratch and struggle with knowledge transfer. In this paper we propose a principled way to learn a basis set of policies, which, when recombined through generalised policy improvement, come with guarantees on the coverage of the final task space. In particular, we concentrate on solving goal-based downstream tasks where the execution order of actions is not important. We demonstrate both theoretically and empirically that learning a small number of policies that reach intrinsically specified goal regions in a disentangled latent space can be re-used to quickly achieve a high level of performance on an exponentially larger number of externally specified, often significantly more complex downstream tasks. Our learning pipeline consists of two stages. First, the agent learns to perform intrinsically generated, goal-based tasks in the total absence of environmental rewards. Second, the agent leverages this experience to quickly achieve a high level of performance on numerous diverse externally specified tasks.
Object-oriented state editing for HRL
Oct 31, 2019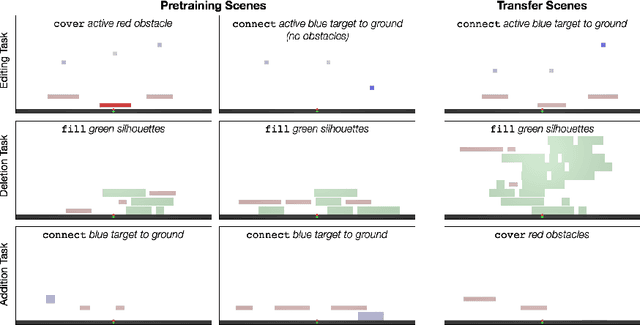
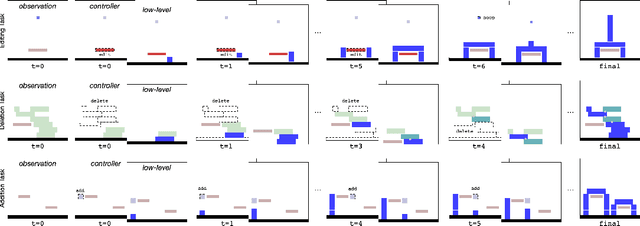
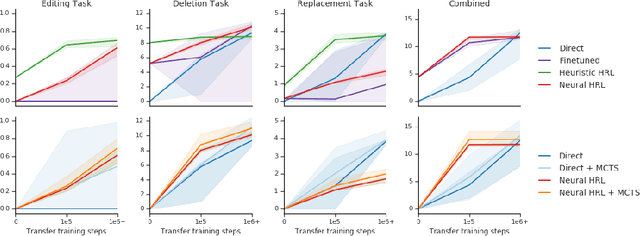

We introduce agents that use object-oriented reasoning to consider alternate states of the world in order to more quickly find solutions to problems. Specifically, a hierarchical controller directs a low-level agent to behave as if objects in the scene were added, deleted, or modified. The actions taken by the controller are defined over a graph-based representation of the scene, with actions corresponding to adding, deleting, or editing the nodes of a graph. We present preliminary results on three environments, demonstrating that our approach can achieve similar levels of reward as non-hierarchical agents, but with better data efficiency.
Sample Complexity of Reinforcement Learning using Linearly Combined Model Ensembles
Oct 23, 2019Reinforcement learning (RL) methods have been shown to be capable of learning intelligent behavior in rich domains. However, this has largely been done in simulated domains without adequate focus on the process of building the simulator. In this paper, we consider a setting where we have access to an ensemble of pre-trained and possibly inaccurate simulators (models). We approximate the real environment using a state-dependent linear combination of the ensemble, where the coefficients are determined by the given state features and some unknown parameters. Our proposed algorithm provably learns a near-optimal policy with a sample complexity polynomial in the number of unknown parameters, and incurs no dependence on the size of the state (or action) space. As an extension, we also consider the more challenging problem of model selection, where the state features are unknown and can be chosen from a large candidate set. We provide exponential lower bounds that illustrate the fundamental hardness of this problem, and develop a provably efficient algorithm under additional natural assumptions.
Discovery of Useful Questions as Auxiliary Tasks
Sep 10, 2019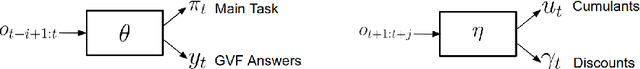

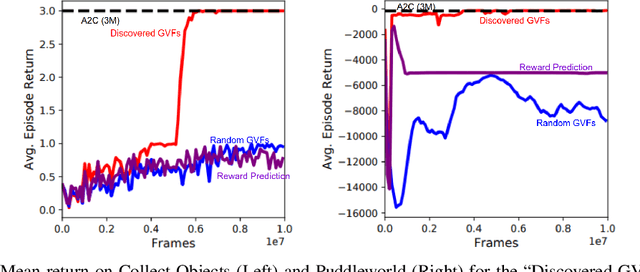
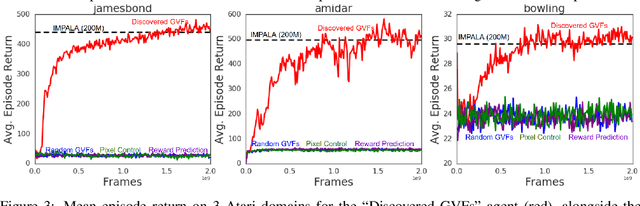
Arguably, intelligent agents ought to be able to discover their own questions so that in learning answers for them they learn unanticipated useful knowledge and skills; this departs from the focus in much of machine learning on agents learning answers to externally defined questions. We present a novel method for a reinforcement learning (RL) agent to discover questions formulated as general value functions or GVFs, a fairly rich form of knowledge representation. Specifically, our method uses non-myopic meta-gradients to learn GVF-questions such that learning answers to them, as an auxiliary task, induces useful representations for the main task faced by the RL agent. We demonstrate that auxiliary tasks based on the discovered GVFs are sufficient, on their own, to build representations that support main task learning, and that they do so better than popular hand-designed auxiliary tasks from the literature. Furthermore, we show, in the context of Atari 2600 videogames, how such auxiliary tasks, meta-learned alongside the main task, can improve the data efficiency of an actor-critic agent.
No Press Diplomacy: Modeling Multi-Agent Gameplay
Sep 04, 2019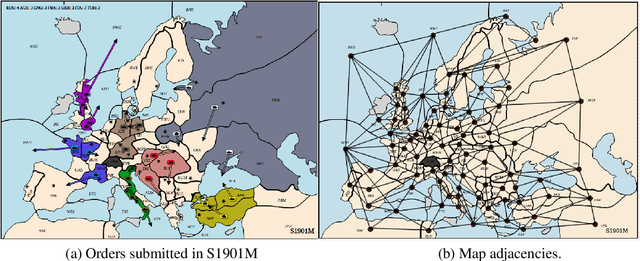
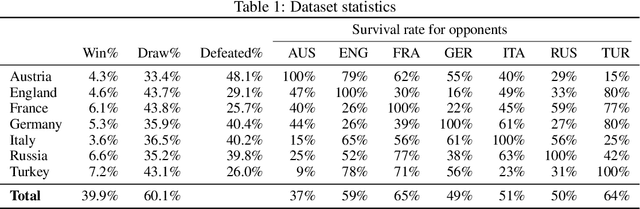
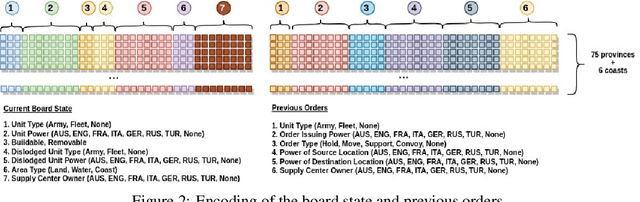
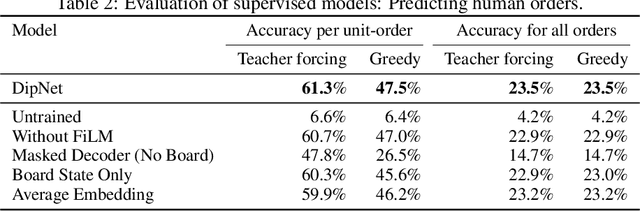
Diplomacy is a seven-player non-stochastic, non-cooperative game, where agents acquire resources through a mix of teamwork and betrayal. Reliance on trust and coordination makes Diplomacy the first non-cooperative multi-agent benchmark for complex sequential social dilemmas in a rich environment. In this work, we focus on training an agent that learns to play the No Press version of Diplomacy where there is no dedicated communication channel between players. We present DipNet, a neural-network-based policy model for No Press Diplomacy. The model was trained on a new dataset of more than 150,000 human games. Our model is trained by supervised learning (SL) from expert trajectories, which is then used to initialize a reinforcement learning (RL) agent trained through self-play. Both the SL and RL agents demonstrate state-of-the-art No Press performance by beating popular rule-based bots.
Behaviour Suite for Reinforcement Learning
Aug 13, 2019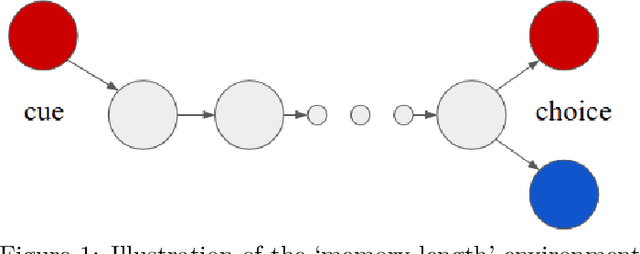
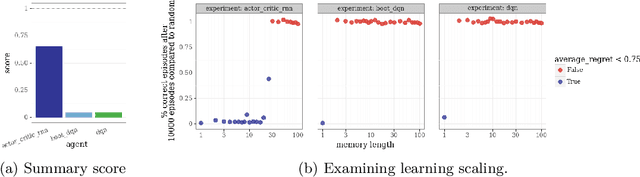
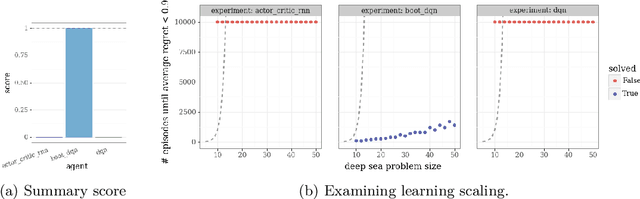
This paper introduces the Behaviour Suite for Reinforcement Learning, or bsuite for short. bsuite is a collection of carefully-designed experiments that investigate core capabilities of reinforcement learning (RL) agents with two objectives. First, to collect clear, informative and scalable problems that capture key issues in the design of general and efficient learning algorithms. Second, to study agent behaviour through their performance on these shared benchmarks. To complement this effort, we open source github.com/deepmind/bsuite, which automates evaluation and analysis of any agent on bsuite. This library facilitates reproducible and accessible research on the core issues in RL, and ultimately the design of superior learning algorithms. Our code is Python, and easy to use within existing projects. We include examples with OpenAI Baselines, Dopamine as well as new reference implementations. Going forward, we hope to incorporate more excellent experiments from the research community, and commit to a periodic review of bsuite from a committee of prominent researchers.