 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Road Map to Strong Intelligence
Feb 20, 2020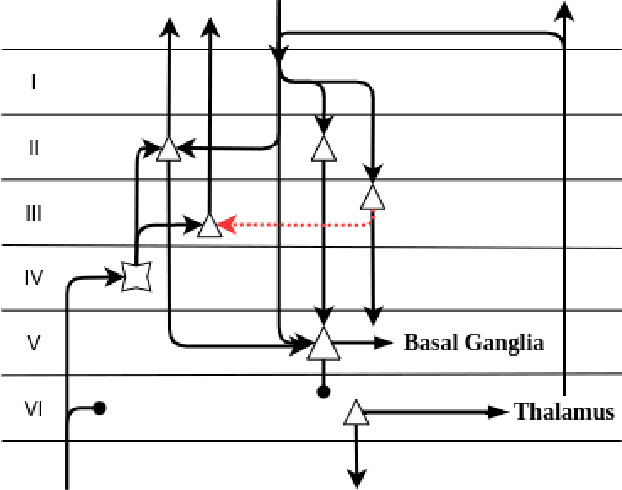
I wrote this paper because technology can really improve people's lives. With it, we can live longer in a healthy body, save time through increased efficiency and automation, and make better decisions. To get to the next level, we need to start looking at intelligence from a much broader perspective, and promote international interdisciplinary collaborations. Section 1 of this paper delves into sociology and social psychology to explain that the mechanisms underlying intelligence are inherently social. Section 2 proposes a method to classify intelligence, and describes the differences between weak and strong intelligence. Section 3 examines the Chinese Room argument from a different perspective. It demonstrates that a Turing-complete machine cannot have strong intelligence, and considers the modifications necessary for a computer to be intelligent and have understanding. Section 4 argues that the existential risk caused by the technological explosion of a single agent should not be of serious concern. Section 5 looks at the AI control problem and argues that it is impossible to build a super-intelligent machine that will do what it creators want. By using insights from biology, it also proposes a solution to the control problem. Section 6 discusses some of the implications of strong intelligence. Section 7 lists the main challenges with deep learning, and asserts that radical changes will be required to reach strong intelligence. Section 8 examines a neuroscience framework that could help explain how a cortical column works. Section 9 lays out the broad strokes of a road map towards strong intelligence. Finally, section 10 analyzes the impacts and the challenges of greater intelligence.
No Press Diplomacy: Modeling Multi-Agent Gameplay
Sep 04, 2019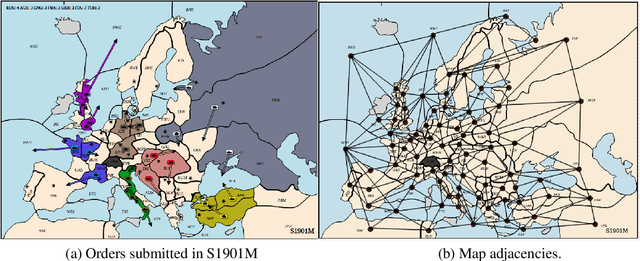
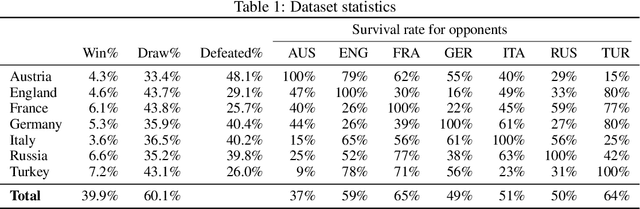
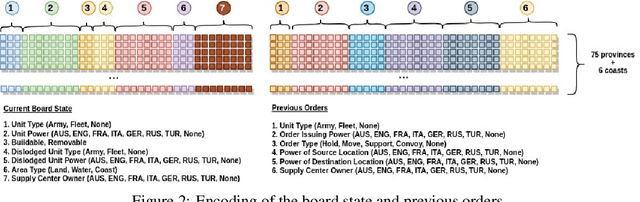
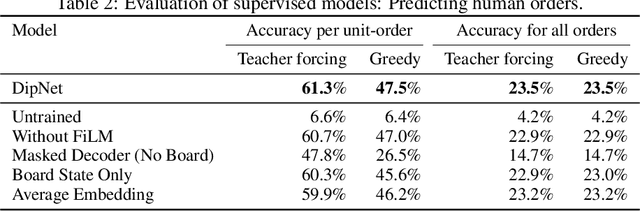
Diplomacy is a seven-player non-stochastic, non-cooperative game, where agents acquire resources through a mix of teamwork and betrayal. Reliance on trust and coordination makes Diplomacy the first non-cooperative multi-agent benchmark for complex sequential social dilemmas in a rich environment. In this work, we focus on training an agent that learns to play the No Press version of Diplomacy where there is no dedicated communication channel between players. We present DipNet, a neural-network-based policy model for No Press Diplomacy. The model was trained on a new dataset of more than 150,000 human games. Our model is trained by supervised learning (SL) from expert trajectories, which is then used to initialize a reinforcement learning (RL) agent trained through self-play. Both the SL and RL agents demonstrate state-of-the-art No Press performance by beating popular rule-based bots.