 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework for Efficient Large-scale LLM Trainin
May 29, 2025Reinforcement Learning (RL) has become the most effective post-training approach for improving the capabilities of Large Language Models (LLMs). In practice, because of the high demands on latency and memory, it is particularly challenging to develop an efficient RL framework that reliably manages policy models with hundreds to thousands of billions of parameters. In this paper, we present LlamaRL, a fully distributed, asynchronous RL framework optimized for efficient training of large-scale LLMs with various model sizes (8B, 70B, and 405B parameters) on GPU clusters ranging from a handful to thousands of devices. LlamaRL introduces a streamlined, single-controller architecture built entirely on native PyTorch, enabling modularity, ease of use, and seamless scalability to thousands of GPUs. We also provide a theoretical analysis of LlamaRL's efficiency, including a formal proof that its asynchronous design leads to strict RL speed-up. Empirically, by leveraging best practices such as colocated model offloading, asynchronous off-policy training, and distributed direct memory access for weight synchronization, LlamaRL achieves significant efficiency gains -- up to 10.7x speed-up compared to DeepSpeed-Chat-like systems on a 405B-parameter policy model. Furthermore, the efficiency advantage continues to grow with increasing model scale, demonstrating the framework's suitability for future large-scale RL training.
Spatio-temporal Prediction of Fine-Grained Origin-Destination Matrices with Applications in Ridesharing
Mar 31, 2025Accurate spatial-temporal prediction of network-based travelers' requests is crucial for the effective policy design of ridesharing platforms. Having knowledge of the total demand between various locations in the upcoming time slots enables platforms to proactively prepare adequate supplies, thereby increasing the likelihood of fulfilling travelers' requests and redistributing idle drivers to areas with high potential demand to optimize the global supply-demand equilibrium. This paper delves into the prediction of Origin-Destination (OD) demands at a fine-grained spatial level, especially when confronted with an expansive set of local regions. While this task holds immense practical value, it remains relatively unexplored within the research community. To fill this gap, we introduce a novel prediction model called OD-CED, which comprises an unsupervised space coarsening technique to alleviate data sparsity and an encoder-decoder architecture to capture both semantic and geographic dependencies. Through practical experimentation, OD-CED has demonstrated remarkable results. It achieved an impressive reduction of up to 45% reduction in root-mean-square error and 60% in weighted mean absolute percentage error over traditional statistical methods when dealing with OD matrices exhibiting a sparsity exceeding 90%.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Golfer: Trajectory Prediction with Masked Goal Conditioning MnM Network
Jul 02, 2022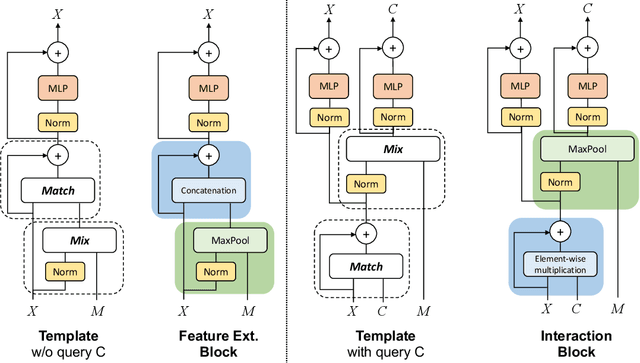
Transformers have enabled breakthroughs in NLP and computer vision, and have recently began to show promising performance in trajectory prediction for Autonomous Vehicle (AV). How to efficiently model the interactive relationships between the ego agent and other road and dynamic objects remains challenging for the standard attention module. In this work we propose a general Transformer-like architectural module MnM network equipped with novel masked goal conditioning training procedures for AV trajectory prediction. The resulted model, named golfer, achieves state-of-the-art performance, winning the 2nd place in the 2022 Waymo Open Dataset Motion Prediction Challenge and ranked 1st place according to minADE.
Reinforcement Learning in the Wild: Scalable RL Dispatching Algorithm Deployed in Ridehailing Marketplace
Feb 10, 2022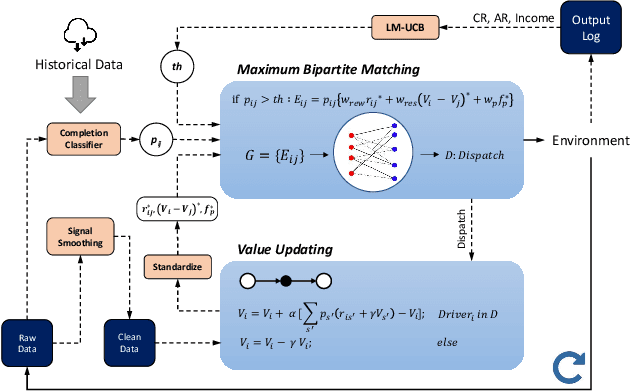
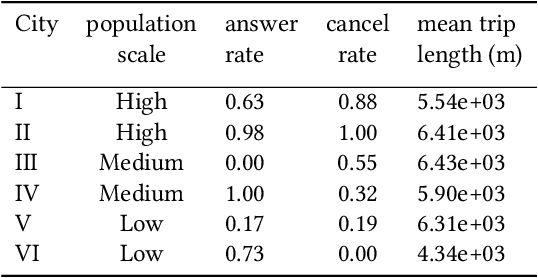
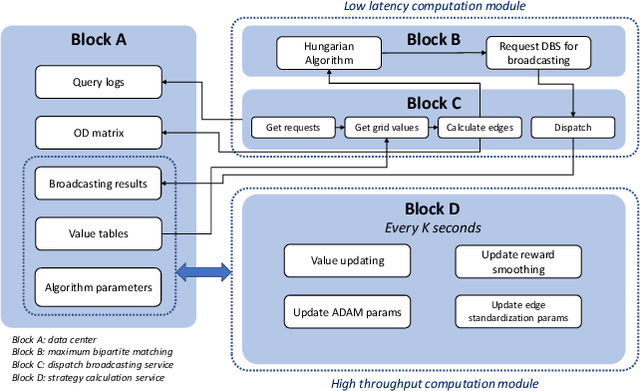
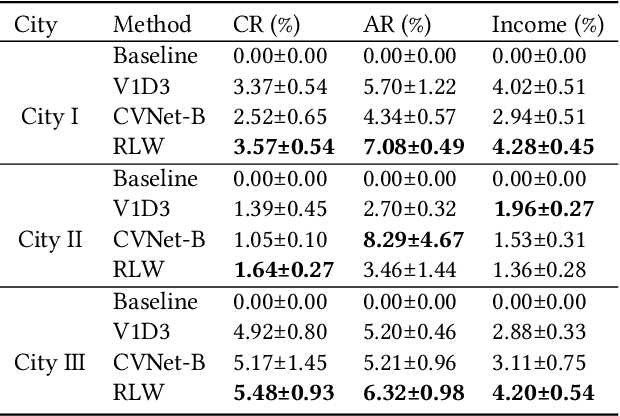
In this study, a real-time dispatching algorithm based on reinforcement learning is proposed and for the first time, is deployed in large scale. Current dispatching methods in ridehailing platforms are dominantly based on myopic or rule-based non-myopic approaches. Reinforcement learning enables dispatching policies that are informed of historical data and able to employ the learned information to optimize returns of expected future trajectories. Previous studies in this field yielded promising results, yet have left room for further improvements in terms of performance gain, self-dependency, transferability, and scalable deployment mechanisms. The present study proposes a standalone RL-based dispatching solution that is equipped with multiple mechanisms to ensure robust and efficient on-policy learning and inference while being adaptable for full-scale deployment. A new form of value updating based on temporal difference is proposed that is more adapted to the inherent uncertainty of the problem. For the driver-order assignment, a customized utility function is proposed that when tuned based on the statistics of the market, results in remarkable performance improvement and interpretability. In addition, for reducing the risk of cancellation after drivers' assignment, an adaptive graph pruning strategy based on the multi-arm bandit problem is introduced. The method is evaluated using offline simulation with real data and yields notable performance improvement. In addition, the algorithm is deployed online in multiple cities under DiDi's operation for A/B testing and is launched in one of the major international markets as the primary mode of dispatch. The deployed algorithm shows over 1.3% improvement in total driver income from A/B testing. In addition, by causal inference analysis, as much as 5.3% improvement in major performance metrics is detected after full-scale deployment.
RANK-NOSH: Efficient Predictor-Based Architecture Search via Non-Uniform Successive Halving
Aug 18, 2021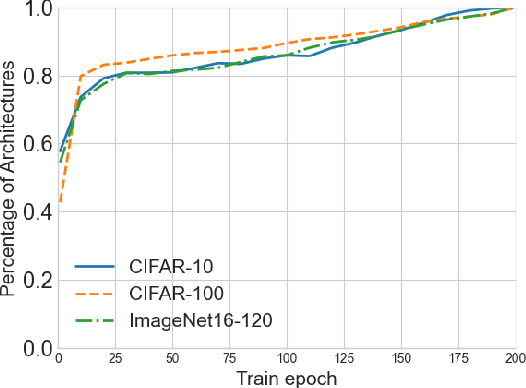
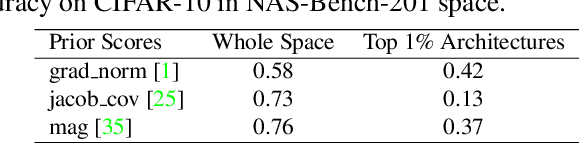
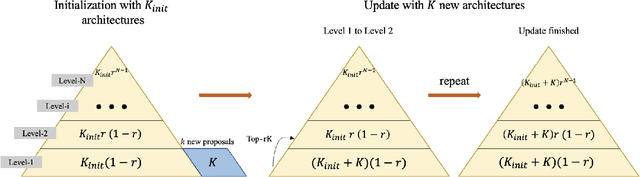
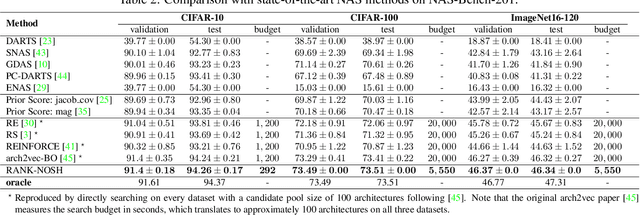
Predictor-based algorithms have achieved remarkable performance in the Neural Architecture Search (NAS) tasks. However, these methods suffer from high computation costs, as training the performance predictor usually requires training and evaluating hundreds of architectures from scratch. Previous works along this line mainly focus on reducing the number of architectures required to fit the predictor. In this work, we tackle this challenge from a different perspective - improve search efficiency by cutting down the computation budget of architecture training. We propose NOn-uniform Successive Halving (NOSH), a hierarchical scheduling algorithm that terminates the training of underperforming architectures early to avoid wasting budget. To effectively leverage the non-uniform supervision signals produced by NOSH, we formulate predictor-based architecture search as learning to rank with pairwise comparisons. The resulting method - RANK-NOSH, reduces the search budget by ~5x while achieving competitive or even better performance than previous state-of-the-art predictor-based methods on various spaces and datasets.
Rethinking Architecture Selection in Differentiable NAS
Aug 10, 2021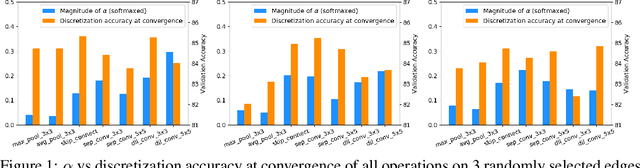
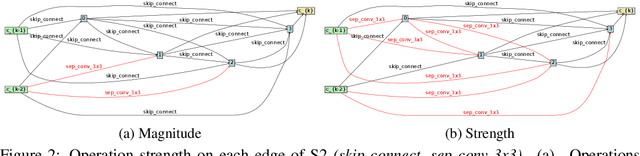
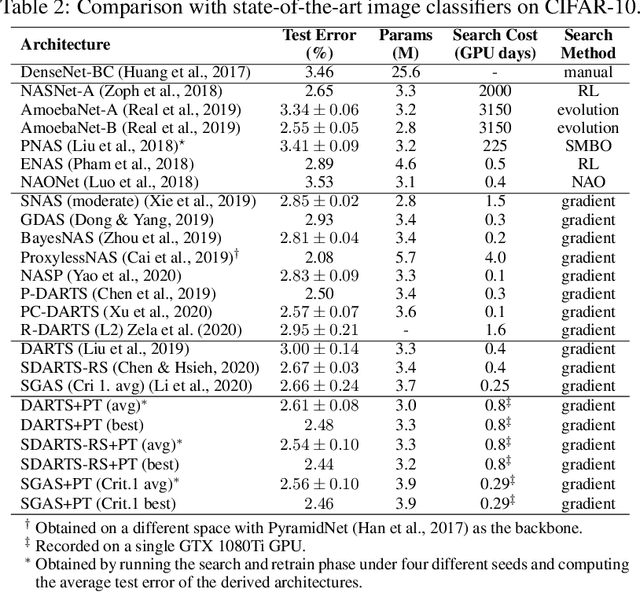

Differentiable Neural Architecture Search is one of the most popular Neural Architecture Search (NAS) methods for its search efficiency and simplicity, accomplished by jointly optimizing the model weight and architecture parameters in a weight-sharing supernet via gradient-based algorithms. At the end of the search phase, the operations with the largest architecture parameters will be selected to form the final architecture, with the implicit assumption that the values of architecture parameters reflect the operation strength. While much has been discussed about the supernet's optimization, the architecture selection process has received little attention. We provide empirical and theoretical analysis to show that the magnitude of architecture parameters does not necessarily indicate how much the operation contributes to the supernet's performance. We propose an alternative perturbation-based architecture selection that directly measures each operation's influence on the supernet. We re-evaluate several differentiable NAS methods with the proposed architecture selection and find that it is able to extract significantly improved architectures from the underlying supernets consistently. Furthermore, we find that several failure modes of DARTS can be greatly alleviated with the proposed selection method, indicating that much of the poor generalization observed in DARTS can be attributed to the failure of magnitude-based architecture selection rather than entirely the optimization of its supernet.
A Deep Value-network Based Approach for Multi-Driver Order Dispatching
Jun 08, 2021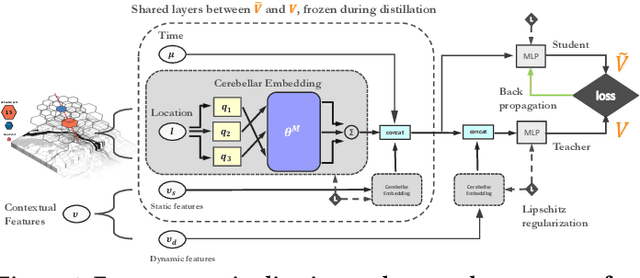
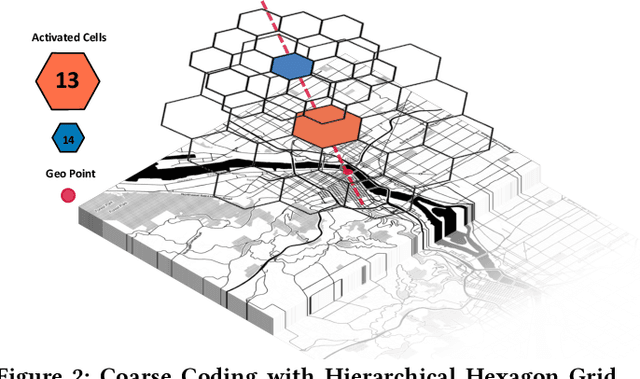
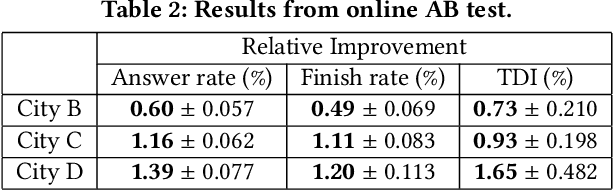
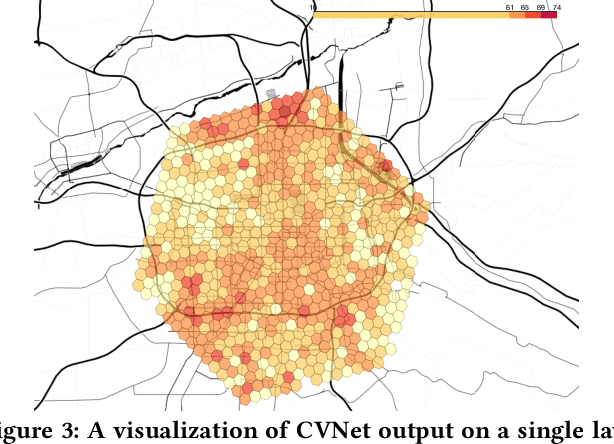
Recent works on ride-sharing order dispatching have highlighted the importance of taking into account both the spatial and temporal dynamics in the dispatching process for improving the transportation system efficiency. At the same time, deep reinforcement learning has advanced to the point where it achieves superhuman performance in a number of fields. In this work, we propose a deep reinforcement learning based solution for order dispatching and we conduct large scale online A/B tests on DiDi's ride-dispatching platform to show that the proposed method achieves significant improvement on both total driver income and user experience related metrics. In particular, we model the ride dispatching problem as a Semi Markov Decision Process to account for the temporal aspect of the dispatching actions. To improve the stability of the value iteration with nonlinear function approximators like neural networks, we propose Cerebellar Value Networks (CVNet) with a novel distributed state representation layer. We further derive a regularized policy evaluation scheme for CVNet that penalizes large Lipschitz constant of the value network for additional robustness against adversarial perturbation and noises. Finally, we adapt various transfer learning methods to CVNet for increased learning adaptability and efficiency across multiple cities. We conduct extensive offline simulations based on real dispatching data as well as online AB tests through the DiDi's platform. Results show that CVNet consistently outperforms other recently proposed dispatching methods. We finally show that the performance can be further improved through the efficient use of transfer learning.
Value Function is All You Need: A Unified Learning Framework for Ride Hailing Platforms
Jun 04, 2021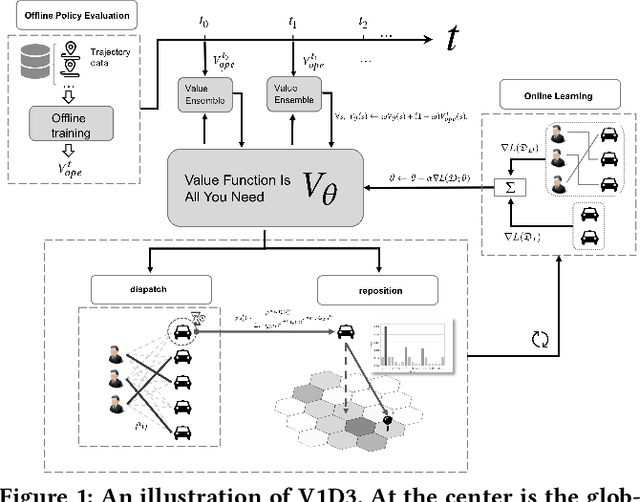
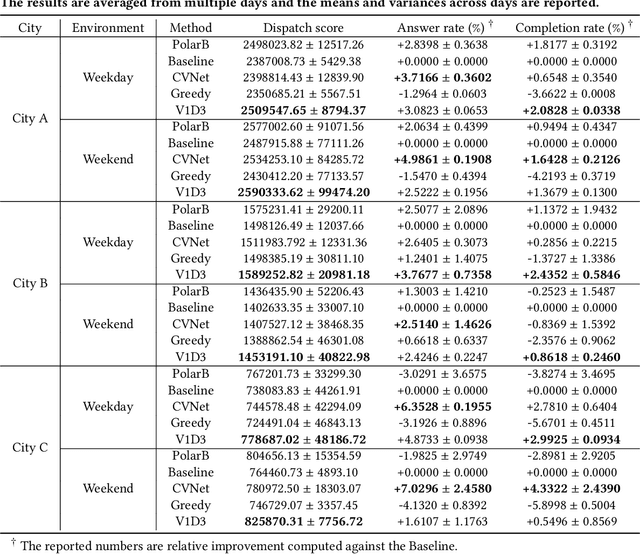
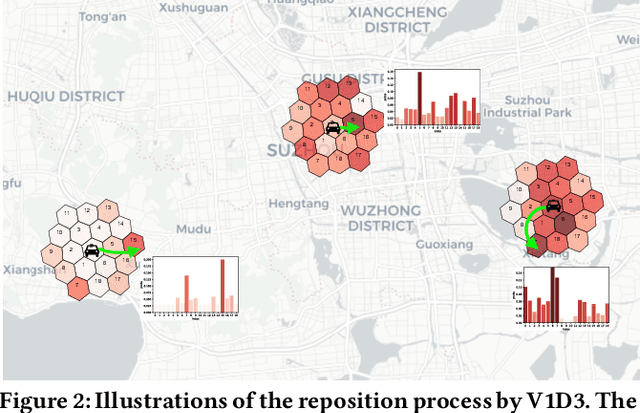
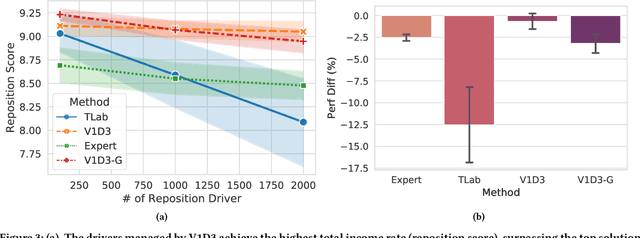
Large ride-hailing platforms, such as DiDi, Uber and Lyft, connect tens of thousands of vehicles in a city to millions of ride demands throughout the day, providing great promises for improving transportation efficiency through the tasks of order dispatching and vehicle repositioning. Existing studies, however, usually consider the two tasks in simplified settings that hardly address the complex interactions between the two, the real-time fluctuations between supply and demand, and the necessary coordinations due to the large-scale nature of the problem. In this paper we propose a unified value-based dynamic learning framework (V1D3) for tackling both tasks. At the center of the framework is a globally shared value function that is updated continuously using online experiences generated from real-time platform transactions. To improve the sample-efficiency and the robustness, we further propose a novel periodic ensemble method combining the fast online learning with a large-scale offline training scheme that leverages the abundant historical driver trajectory data. This allows the proposed framework to adapt quickly to the highly dynamic environment, to generalize robustly to recurrent patterns and to drive implicit coordinations among the population of managed vehicles. Extensive experiments based on real-world datasets show considerably improvements over other recently proposed methods on both tasks. Particularly, V1D3 outperforms the first prize winners of both dispatching and repositioning tracks in the KDD Cup 2020 RL competition, achieving state-of-the-art results on improving both total driver income and user experience related metrics.