 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalist Hanabi Agent
Mar 17, 2025Traditional multi-agent reinforcement learning (MARL) systems can develop cooperative strategies through repeated interactions. However, these systems are unable to perform well on any other setting than the one they have been trained on, and struggle to successfully cooperate with unfamiliar collaborators. This is particularly visible in the Hanabi benchmark, a popular 2-to-5 player cooperative card-game which requires complex reasoning and precise assistance to other agents. Current MARL agents for Hanabi can only learn one specific game-setting (e.g., 2-player games), and play with the same algorithmic agents. This is in stark contrast to humans, who can quickly adjust their strategies to work with unfamiliar partners or situations. In this paper, we introduce Recurrent Replay Relevance Distributed DQN (R3D2), a generalist agent for Hanabi, designed to overcome these limitations. We reformulate the task using text, as language has been shown to improve transfer. We then propose a distributed MARL algorithm that copes with the resulting dynamic observation- and action-space. In doing so, our agent is the first that can play all game settings concurrently, and extend strategies learned from one setting to other ones. As a consequence, our agent also demonstrates the ability to collaborate with different algorithmic agents -- agents that are themselves unable to do so. The implementation code is available at: $\href{https://github.com/chandar-lab/R3D2-A-Generalist-Hanabi-Agent}{R3D2-A-Generalist-Hanabi-Agent}$
Toward Debugging Deep Reinforcement Learning Programs with RLExplorer
Oct 06, 2024



Deep reinforcement learning (DRL) has shown success in diverse domains such as robotics, computer games, and recommendation systems. However, like any other software system, DRL-based software systems are susceptible to faults that pose unique challenges for debugging and diagnosing. These faults often result in unexpected behavior without explicit failures and error messages, making debugging difficult and time-consuming. Therefore, automating the monitoring and diagnosis of DRL systems is crucial to alleviate the burden on developers. In this paper, we propose RLExplorer, the first fault diagnosis approach for DRL-based software systems. RLExplorer automatically monitors training traces and runs diagnosis routines based on properties of the DRL learning dynamics to detect the occurrence of DRL-specific faults. It then logs the results of these diagnoses as warnings that cover theoretical concepts, recommended practices, and potential solutions to the identified faults. We conducted two sets of evaluations to assess RLExplorer. Our first evaluation of faulty DRL samples from Stack Overflow revealed that our approach can effectively diagnose real faults in 83% of the cases. Our second evaluation of RLExplorer with 15 DRL experts/developers showed that (1) RLExplorer could identify 3.6 times more defects than manual debugging and (2) RLExplorer is easily integrated into DRL applications.
Intelligent Switching for Reset-Free RL
May 02, 2024In the real world, the strong episode resetting mechanisms that are needed to train agents in simulation are unavailable. The \textit{resetting} assumption limits the potential of reinforcement learning in the real world, as providing resets to an agent usually requires the creation of additional handcrafted mechanisms or human interventions. Recent work aims to train agents (\textit{forward}) with learned resets by constructing a second (\textit{backward}) agent that returns the forward agent to the initial state. We find that the termination and timing of the transitions between these two agents are crucial for algorithm success. With this in mind, we create a new algorithm, Reset Free RL with Intelligently Switching Controller (RISC) which intelligently switches between the two agents based on the agent's confidence in achieving its current goal. Our new method achieves state-of-the-art performance on several challenging environments for reset-free RL.
Fairness Incentives in Response to Unfair Dynamic Pricing
Apr 22, 2024The use of dynamic pricing by profit-maximizing firms gives rise to demand fairness concerns, measured by discrepancies in consumer groups' demand responses to a given pricing strategy. Notably, dynamic pricing may result in buyer distributions unreflective of those of the underlying population, which can be problematic in markets where fair representation is socially desirable. To address this, policy makers might leverage tools such as taxation and subsidy to adapt policy mechanisms dependent upon their social objective. In this paper, we explore the potential for AI methods to assist such intervention strategies. To this end, we design a basic simulated economy, wherein we introduce a dynamic social planner (SP) to generate corporate taxation schedules geared to incentivizing firms towards adopting fair pricing behaviours, and to use the collected tax budget to subsidize consumption among underrepresented groups. To cover a range of possible policy scenarios, we formulate our social planner's learning problem as a multi-armed bandit, a contextual bandit and finally as a full reinforcement learning (RL) problem, evaluating welfare outcomes from each case. To alleviate the difficulty in retaining meaningful tax rates that apply to less frequently occurring brackets, we introduce FairReplayBuffer, which ensures that our RL agent samples experiences uniformly across a discretized fairness space. We find that, upon deploying a learned tax and redistribution policy, social welfare improves on that of the fairness-agnostic baseline, and approaches that of the analytically optimal fairness-aware baseline for the multi-armed and contextual bandit settings, and surpassing it by 13.19% in the full RL setting.
Mastering Memory Tasks with World Models
Mar 07, 2024Current model-based reinforcement learning (MBRL) agents struggle with long-term dependencies. This limits their ability to effectively solve tasks involving extended time gaps between actions and outcomes, or tasks demanding the recalling of distant observations to inform current actions. To improve temporal coherence, we integrate a new family of state space models (SSMs) in world models of MBRL agents to present a new method, Recall to Imagine (R2I). This integration aims to enhance both long-term memory and long-horizon credit assignment. Through a diverse set of illustrative tasks, we systematically demonstrate that R2I not only establishes a new state-of-the-art for challenging memory and credit assignment RL tasks, such as BSuite and POPGym, but also showcases superhuman performance in the complex memory domain of Memory Maze. At the same time, it upholds comparable performance in classic RL tasks, such as Atari and DMC, suggesting the generality of our method. We also show that R2I is faster than the state-of-the-art MBRL method, DreamerV3, resulting in faster wall-time convergence.
Language Model-In-The-Loop: Data Optimal Approach to Learn-To-Recommend Actions in Text Games
Nov 13, 2023



Large Language Models (LLMs) have demonstrated superior performance in language understanding benchmarks. CALM, a popular approach, leverages linguistic priors of LLMs -- GPT-2 -- for action candidate recommendations to improve the performance in text games in Jericho without environment-provided actions. However, CALM adapts GPT-2 with annotated human gameplays and keeps the LLM fixed during the learning of the text based games. In this work, we explore and evaluate updating LLM used for candidate recommendation during the learning of the text based game as well to mitigate the reliance on the human annotated gameplays, which are costly to acquire. We observe that by updating the LLM during learning using carefully selected in-game transitions, we can reduce the dependency on using human annotated game plays for fine-tuning the LLMs. We conducted further analysis to study the transferability of the updated LLMs and observed that transferring in-game trained models to other games did not result in a consistent transfer.
Towards Few-shot Coordination: Revisiting Ad-hoc Teamplay Challenge In the Game of Hanabi
Aug 20, 2023



Cooperative Multi-agent Reinforcement Learning (MARL) algorithms with Zero-Shot Coordination (ZSC) have gained significant attention in recent years. ZSC refers to the ability of agents to coordinate zero-shot (without additional interaction experience) with independently trained agents. While ZSC is crucial for cooperative MARL agents, it might not be possible for complex tasks and changing environments. Agents also need to adapt and improve their performance with minimal interaction with other agents. In this work, we show empirically that state-of-the-art ZSC algorithms have poor performance when paired with agents trained with different learning methods, and they require millions of interaction samples to adapt to these new partners. To investigate this issue, we formally defined a framework based on a popular cooperative multi-agent game called Hanabi to evaluate the adaptability of MARL methods. In particular, we created a diverse set of pre-trained agents and defined a new metric called adaptation regret that measures the agent's ability to efficiently adapt and improve its coordination performance when paired with some held-out pool of partners on top of its ZSC performance. After evaluating several SOTA algorithms using our framework, our experiments reveal that naive Independent Q-Learning (IQL) agents in most cases adapt as quickly as the SOTA ZSC algorithm Off-Belief Learning (OBL). This finding raises an interesting research question: How to design MARL algorithms with high ZSC performance and capability of fast adaptation to unseen partners. As a first step, we studied the role of different hyper-parameters and design choices on the adaptability of current MARL algorithms. Our experiments show that two categories of hyper-parameters controlling the training data diversity and optimization process have a significant impact on the adaptability of Hanabi agents.
Conditionally Optimistic Exploration for Cooperative Deep Multi-Agent Reinforcement Learning
Mar 16, 2023



Efficient exploration is critical in cooperative deep Multi-Agent Reinforcement Learning (MARL). In this paper, we propose an exploration method that efficiently encourages cooperative exploration based on the idea of the theoretically justified tree search algorithm UCT (Upper Confidence bounds applied to Trees). The high-level intuition is that to perform optimism-based exploration, agents would achieve cooperative strategies if each agent's optimism estimate captures a structured dependency relationship with other agents. At each node (i.e., action) of the search tree, UCT performs optimism-based exploration using a bonus derived by conditioning on the visitation count of its parent node. We provide a perspective to view MARL as tree search iterations and develop a method called Conditionally Optimistic Exploration (COE). We assume agents take actions following a sequential order, and consider nodes at the same depth of the search tree as actions of one individual agent. COE computes each agent's state-action value estimate with an optimistic bonus derived from the visitation count of the state and joint actions taken by agents up to the current agent. COE is adaptable to any value decomposition method for centralized training with decentralized execution. Experiments across various cooperative MARL benchmarks show that COE outperforms current state-of-the-art exploration methods on hard-exploration tasks.
Replay Buffer With Local Forgetting for Adaptive Deep Model-Based Reinforcement Learning
Mar 15, 2023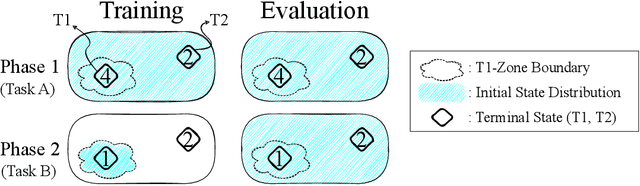
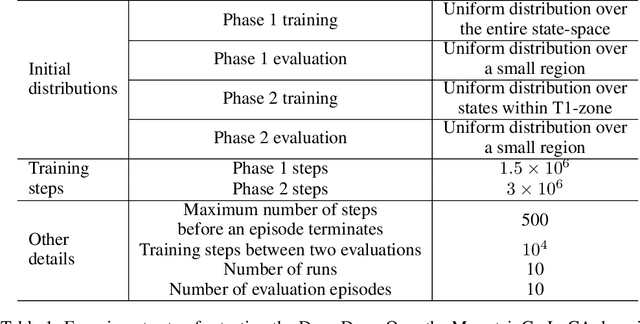
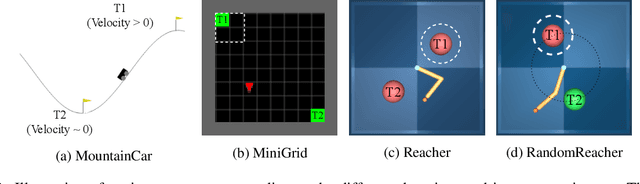
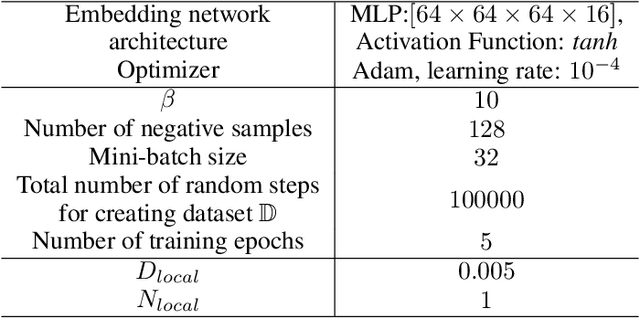
One of the key behavioral characteristics used in neuroscience to determine whether the subject of study -- be it a rodent or a human -- exhibits model-based learning is effective adaptation to local changes in the environment. In reinforcement learning, however, recent work has shown that modern deep model-based reinforcement-learning (MBRL) methods adapt poorly to such changes. An explanation for this mismatch is that MBRL methods are typically designed with sample-efficiency on a single task in mind and the requirements for effective adaptation are substantially higher, both in terms of the learned world model and the planning routine. One particularly challenging requirement is that the learned world model has to be sufficiently accurate throughout relevant parts of the state-space. This is challenging for deep-learning-based world models due to catastrophic forgetting. And while a replay buffer can mitigate the effects of catastrophic forgetting, the traditional first-in-first-out replay buffer precludes effective adaptation due to maintaining stale data. In this work, we show that a conceptually simple variation of this traditional replay buffer is able to overcome this limitation. By removing only samples from the buffer from the local neighbourhood of the newly observed samples, deep world models can be built that maintain their accuracy across the state-space, while also being able to effectively adapt to changes in the reward function. We demonstrate this by applying our replay-buffer variation to a deep version of the classical Dyna method, as well as to recent methods such as PlaNet and DreamerV2, demonstrating that deep model-based methods can adapt effectively as well to local changes in the environment.
Dealing With Non-stationarity in Decentralized Cooperative Multi-Agent Deep Reinforcement Learning via Multi-Timescale Learning
Feb 06, 2023



Decentralized cooperative multi-agent deep reinforcement learning (MARL) can be a versatile learning framework, particularly in scenarios where centralized training is either not possible or not practical. One of the key challenges in decentralized deep MARL is the non-stationarity of the learning environment when multiple agents are learning concurrently. A commonly used and efficient scheme for decentralized MARL is independent learning in which agents concurrently update their policies independent of each other. We first show that independent learning does not always converge, while sequential learning where agents update their policies one after another in a sequence is guaranteed to converge to an agent-by-agent optimal solution. In sequential learning, when one agent updates its policy, all other agent's policies are kept fixed, alleviating the challenge of non-stationarity due to concurrent updates in other agents' policies. However, it can be slow because only one agent is learning at any time. Therefore it might also not always be practical. In this work, we propose a decentralized cooperative MARL algorithm based on multi-timescale learning. In multi-timescale learning, all agents learn concurrently, but at different learning rates. In our proposed method, when one agent updates its policy, other agents are allowed to update their policies as well, but at a slower rate. This speeds up sequential learning, while also minimizing non-stationarity caused by other agents updating concurrently. Multi-timescale learning outperforms state-of-the-art decentralized learning methods on a set of challenging multi-agent cooperative tasks in the epymarl (papoudakis2020) benchmark. This can be seen as a first step towards more general decentralized cooperative deep MARL methods based on multi-timescale learning.