 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataRater: Meta-Learned Dataset Curation
May 23, 2025The quality of foundation models depends heavily on their training data. Consequently, great efforts have been put into dataset curation. Yet most approaches rely on manual tuning of coarse-grained mixtures of large buckets of data, or filtering by hand-crafted heuristics. An approach that is ultimately more scalable (let alone more satisfying) is to \emph{learn} which data is actually valuable for training. This type of meta-learning could allow more sophisticated, fine-grained, and effective curation. Our proposed \emph{DataRater} is an instance of this idea. It estimates the value of training on any particular data point. This is done by meta-learning using `meta-gradients', with the objective of improving training efficiency on held out data. In extensive experiments across a range of model scales and datasets, we find that using our DataRater to filter data is highly effective, resulting in significantly improved compute efficiency.
Self-Consistent Models and Values
Oct 25, 2021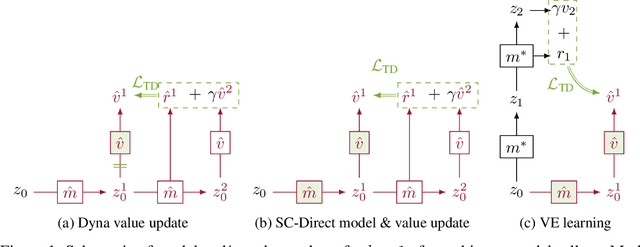

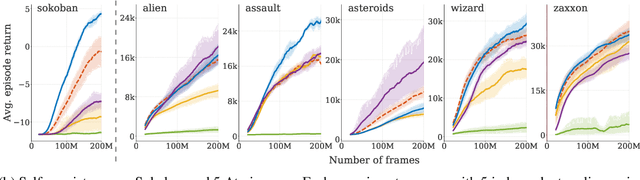
Learned models of the environment provide reinforcement learning (RL) agents with flexible ways of making predictions about the environment. In particular, models enable planning, i.e. using more computation to improve value functions or policies, without requiring additional environment interactions. In this work, we investigate a way of augmenting model-based RL, by additionally encouraging a learned model and value function to be jointly \emph{self-consistent}. Our approach differs from classic planning methods such as Dyna, which only update values to be consistent with the model. We propose multiple self-consistency updates, evaluate these in both tabular and function approximation settings, and find that, with appropriate choices, self-consistency helps both policy evaluation and control.
Emphatic Algorithms for Deep Reinforcement Learning
Jun 21, 2021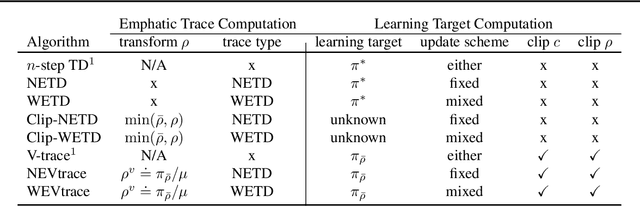
Off-policy learning allows us to learn about possible policies of behavior from experience generated by a different behavior policy. Temporal difference (TD) learning algorithms can become unstable when combined with function approximation and off-policy sampling - this is known as the ''deadly triad''. Emphatic temporal difference (ETD($\lambda$)) algorithm ensures convergence in the linear case by appropriately weighting the TD($\lambda$) updates. In this paper, we extend the use of emphatic methods to deep reinforcement learning agents. We show that naively adapting ETD($\lambda$) to popular deep reinforcement learning algorithms, which use forward view multi-step returns, results in poor performance. We then derive new emphatic algorithms for use in the context of such algorithms, and we demonstrate that they provide noticeable benefits in small problems designed to highlight the instability of TD methods. Finally, we observed improved performance when applying these algorithms at scale on classic Atari games from the Arcade Learning Environment.
Podracer architectures for scalable Reinforcement Learning
Apr 13, 2021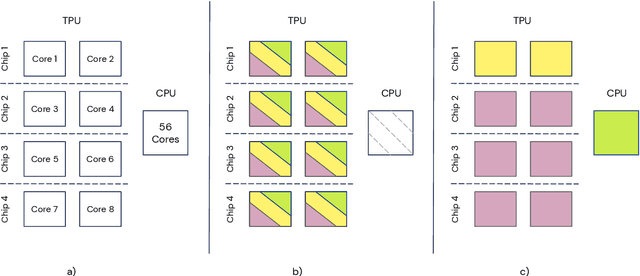
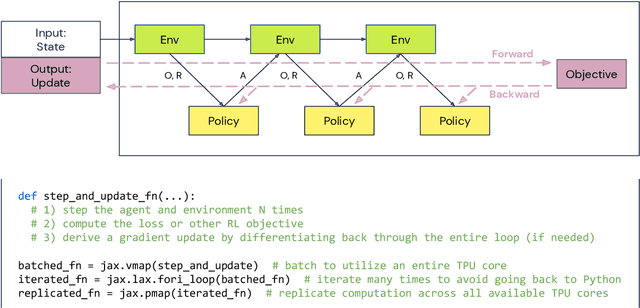
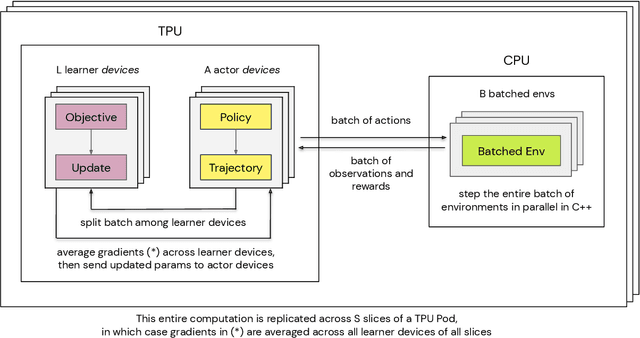
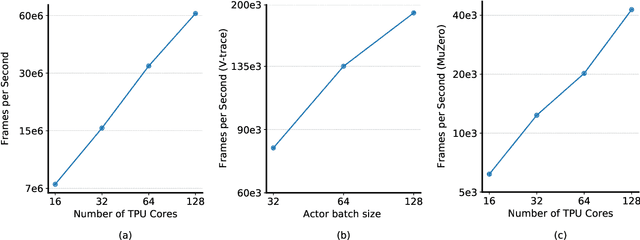
Supporting state-of-the-art AI research requires balancing rapid prototyping, ease of use, and quick iteration, with the ability to deploy experiments at a scale traditionally associated with production systems.Deep learning frameworks such as TensorFlow, PyTorch and JAX allow users to transparently make use of accelerators, such as TPUs and GPUs, to offload the more computationally intensive parts of training and inference in modern deep learning systems. Popular training pipelines that use these frameworks for deep learning typically focus on (un-)supervised learning. How to best train reinforcement learning (RL) agents at scale is still an active research area. In this report we argue that TPUs are particularly well suited for training RL agents in a scalable, efficient and reproducible way. Specifically we describe two architectures designed to make the best use of the resources available on a TPU Pod (a special configuration in a Google data center that features multiple TPU devices connected to each other by extremely low latency communication channels).
Muesli: Combining Improvements in Policy Optimization
Apr 13, 2021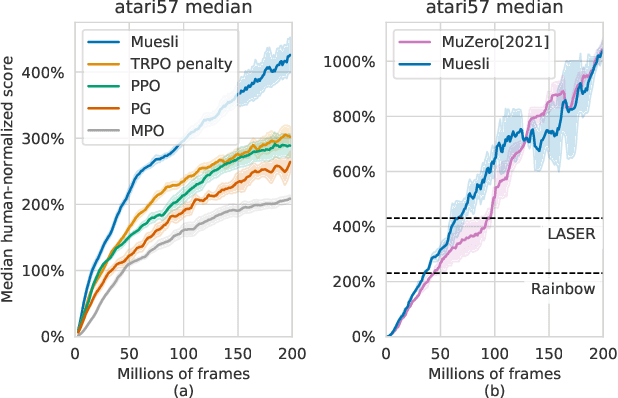
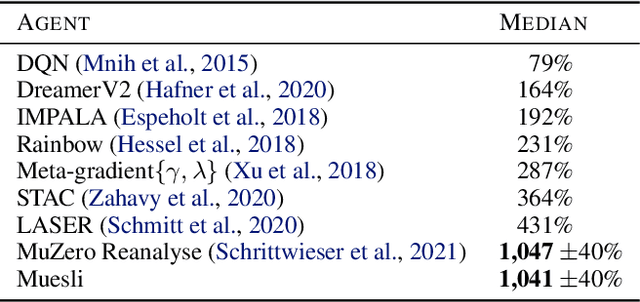
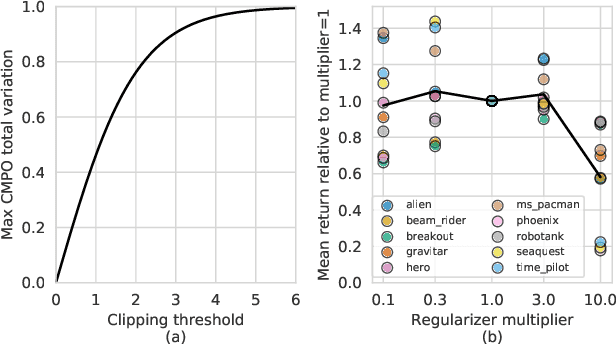
We propose a novel policy update that combines regularized policy optimization with model learning as an auxiliary loss. The update (henceforth Muesli) matches MuZero's state-of-the-art performance on Atari. Notably, Muesli does so without using deep search: it acts directly with a policy network and has computation speed comparable to model-free baselines. The Atari results are complemented by extensive ablations, and by additional results on continuous control and 9x9 Go.
Discovery of Options via Meta-Learned Subgoals
Feb 12, 2021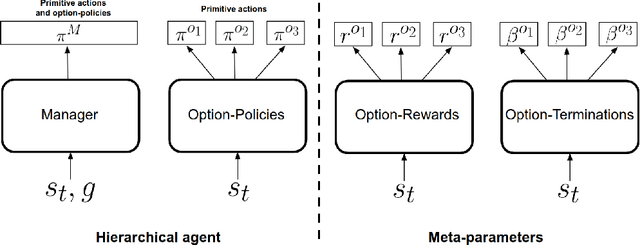
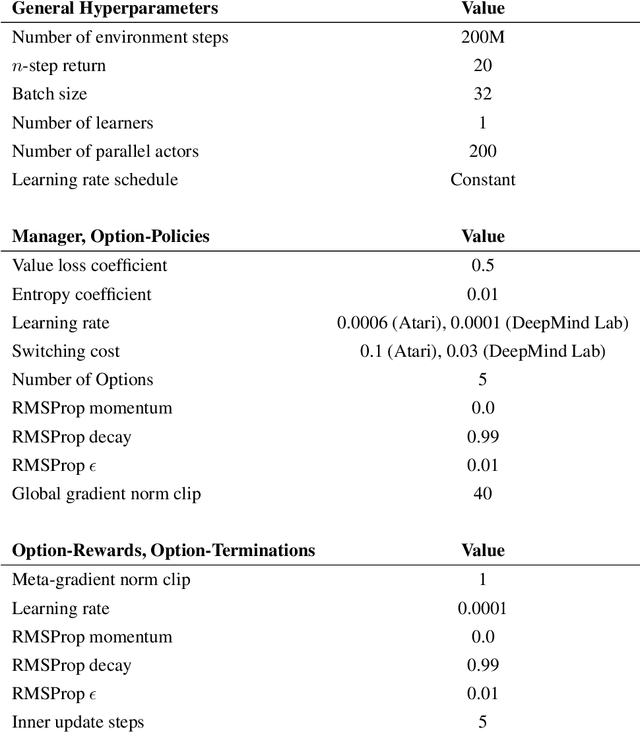
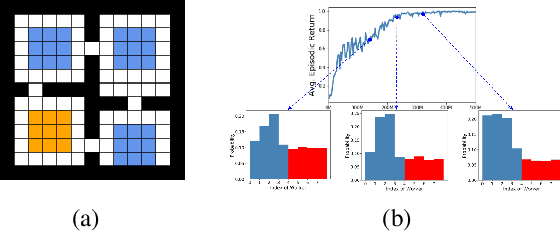
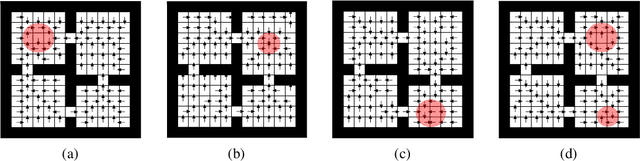
Temporal abstractions in the form of options have been shown to help reinforcement learning (RL) agents learn faster. However, despite prior work on this topic, the problem of discovering options through interaction with an environment remains a challenge. In this paper, we introduce a novel meta-gradient approach for discovering useful options in multi-task RL environments. Our approach is based on a manager-worker decomposition of the RL agent, in which a manager maximises rewards from the environment by learning a task-dependent policy over both a set of task-independent discovered-options and primitive actions. The option-reward and termination functions that define a subgoal for each option are parameterised as neural networks and trained via meta-gradients to maximise their usefulness. Empirical analysis on gridworld and DeepMind Lab tasks show that: (1) our approach can discover meaningful and diverse temporally-extended options in multi-task RL domains, (2) the discovered options are frequently used by the agent while learning to solve the training tasks, and (3) that the discovered options help a randomly initialised manager learn faster in completely new tasks.
Discovering Reinforcement Learning Algorithms
Jul 17, 2020
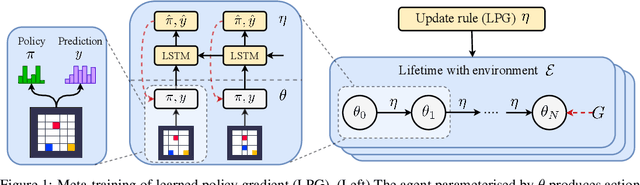
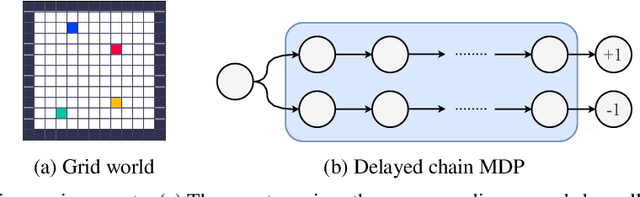
Reinforcement learning (RL) algorithms update an agent's parameters according to one of several possible rules, discovered manually through years of research. Automating the discovery of update rules from data could lead to more efficient algorithms, or algorithms that are better adapted to specific environments. Although there have been prior attempts at addressing this significant scientific challenge, it remains an open question whether it is feasible to discover alternatives to fundamental concepts of RL such as value functions and temporal-difference learning. This paper introduces a new meta-learning approach that discovers an entire update rule which includes both 'what to predict' (e.g. value functions) and 'how to learn from it' (e.g. bootstrapping) by interacting with a set of environments. The output of this method is an RL algorithm that we call Learned Policy Gradient (LPG). Empirical results show that our method discovers its own alternative to the concept of value functions. Furthermore it discovers a bootstrapping mechanism to maintain and use its predictions. Surprisingly, when trained solely on toy environments, LPG generalises effectively to complex Atari games and achieves non-trivial performance. This shows the potential to discover general RL algorithms from data.
Meta-Gradient Reinforcement Learning with an Objective Discovered Online
Jul 16, 2020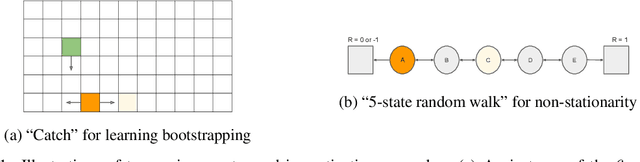

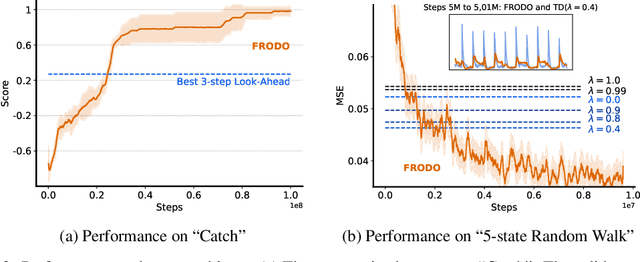
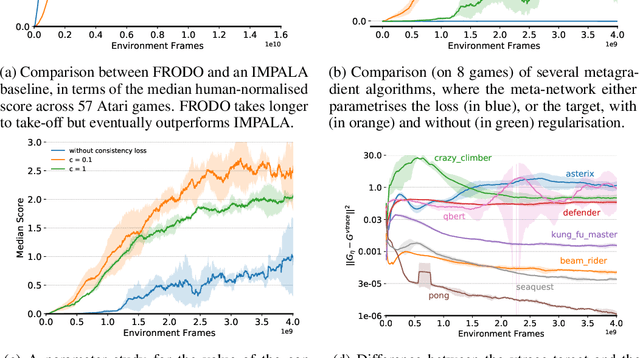
Deep reinforcement learning includes a broad family of algorithms that parameterise an internal representation, such as a value function or policy, by a deep neural network. Each algorithm optimises its parameters with respect to an objective, such as Q-learning or policy gradient, that defines its semantics. In this work, we propose an algorithm based on meta-gradient descent that discovers its own objective, flexibly parameterised by a deep neural network, solely from interactive experience with its environment. Over time, this allows the agent to learn how to learn increasingly effectively. Furthermore, because the objective is discovered online, it can adapt to changes over time. We demonstrate that the algorithm discovers how to address several important issues in RL, such as bootstrapping, non-stationarity, and off-policy learning. On the Atari Learning Environment, the meta-gradient algorithm adapts over time to learn with greater efficiency, eventually outperforming the median score of a strong actor-critic baseline.
Expected Eligibility Traces
Jul 03, 2020
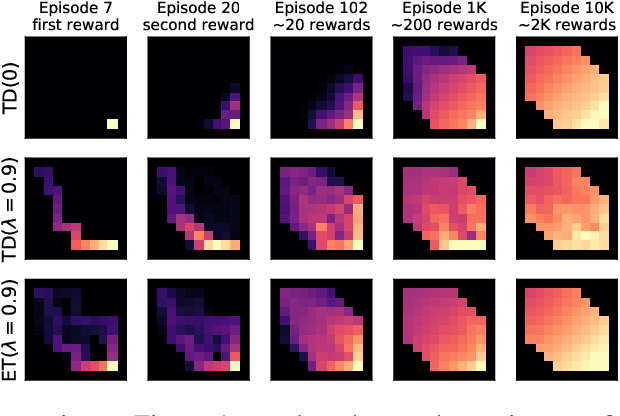
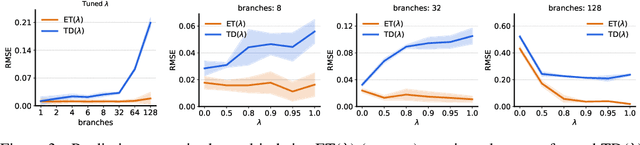
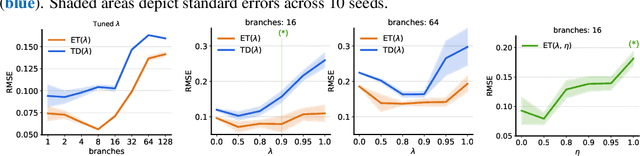
The question of how to determine which states and actions are responsible for a certain outcome is known as the credit assignment problem and remains a central research question in reinforcement learning and artificial intelligence. Eligibility traces enable efficient credit assignment to the recent sequence of states and actions experienced by the agent, but not to counterfactual sequences that could also have led to the current state. In this work, we introduce expected eligibility traces. Expected traces allow, with a single update, to update states and actions that could have preceded the current state, even if they did not do so on this occasion. We discuss when expected traces provide benefits over classic (instantaneous) traces in temporal-difference learning, and show that sometimes substantial improvements can be attained. We provide a way to smoothly interpolate between instantaneous and expected traces by a mechanism similar to bootstrapping, which ensures that the resulting algorithm is a strict generalisation of TD($\lambda$). Finally, we discuss possible extensions and connections to related ideas, such as successor features.
Self-Tuning Deep Reinforcement Learning
Mar 02, 2020
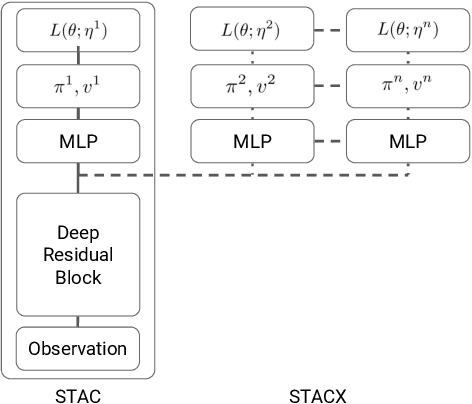
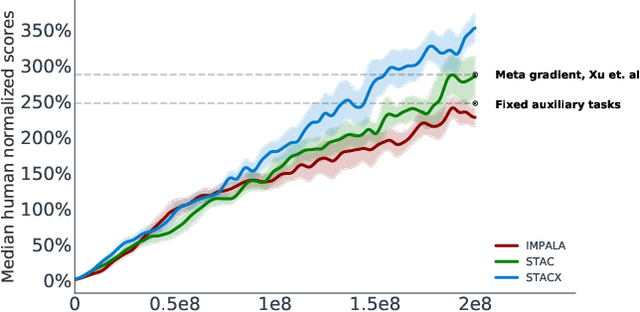
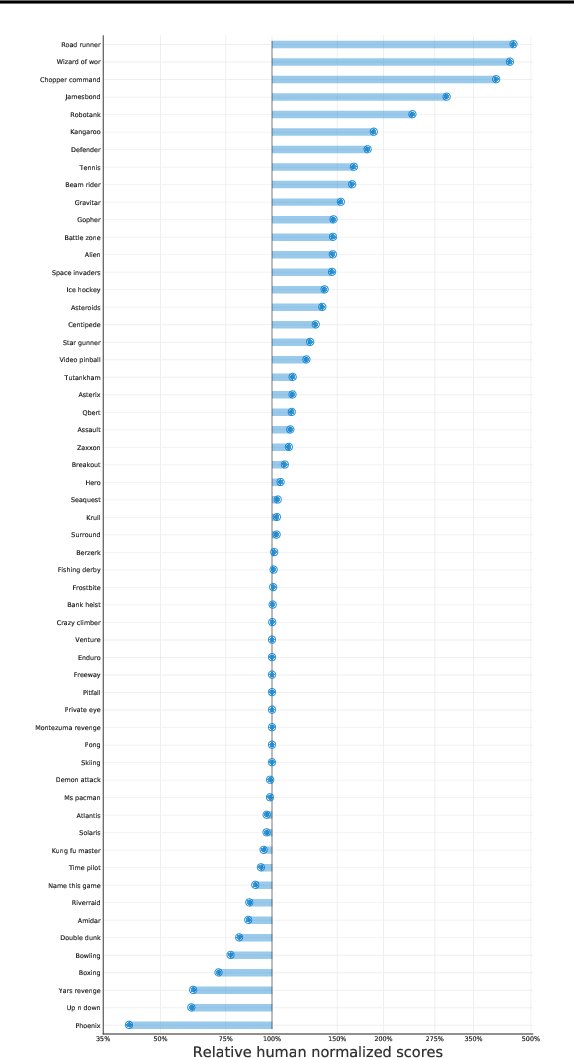
Reinforcement learning (RL) algorithms often require expensive manual or automated hyperparameter searches in order to perform well on a new domain. This need is particularly acute in modern deep RL architectures which often incorporate many modules and multiple loss functions. In this paper, we take a step towards addressing this issue by using metagradients (Xu et al., 2018) to tune these hyperparameters via differentiable cross validation, whilst the agent interacts with and learns from the environment. We present the Self-Tuning Actor Critic (STAC) which uses this process to tune the hyperparameters of the usual loss function of the IMPALA actor critic agent(Espeholt et. al., 2018), to learn the hyperparameters that define auxiliary loss functions, and to balance trade offs in off policy learning by introducing and adapting the hyperparameters of a novel leaky V-trace operator. The method is simple to use, sample efficient and does not require significant increase in compute. Ablative studies show that the overall performance of STAC improves as we adapt more hyperparameters. When applied to 57 games on the Atari 2600 environment over 200 million frames our algorithm improves the median human normalized score of the baseline from 243% to 364%.