 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Force Fields Are Ready For Ground State Catalyst Discovery
Sep 26, 2022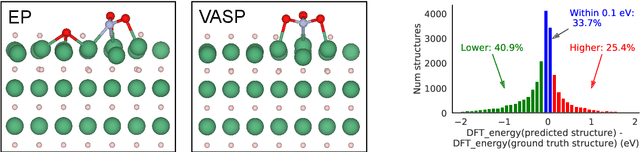
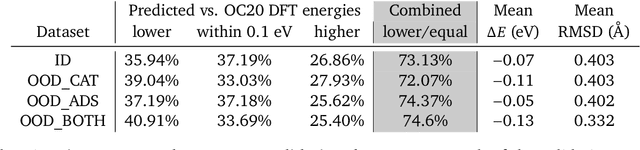
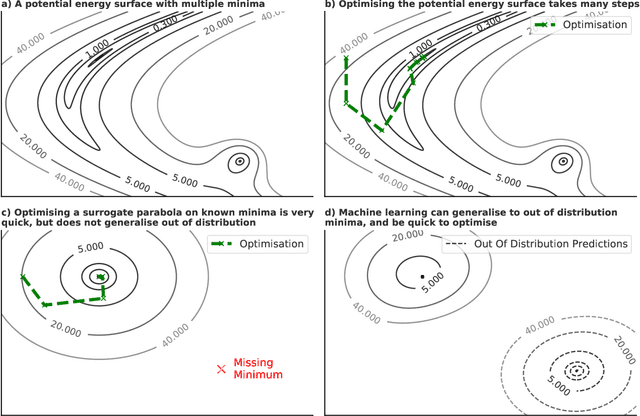
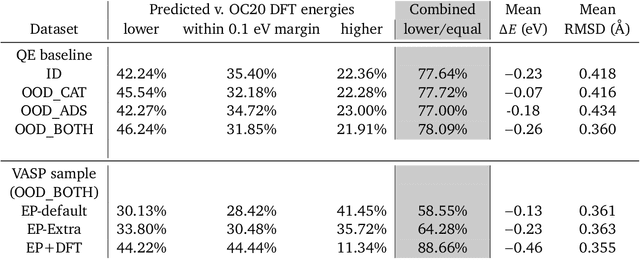
We present evidence that learned density functional theory (``DFT'') force fields are ready for ground state catalyst discovery. Our key finding is that relaxation using forces from a learned potential yields structures with similar or lower energy to those relaxed using the RPBE functional in over 50\% of evaluated systems, despite the fact that the predicted forces differ significantly from the ground truth. This has the surprising implication that learned potentials may be ready for replacing DFT in challenging catalytic systems such as those found in the Open Catalyst 2020 dataset. Furthermore, we show that a force field trained on a locally harmonic energy surface with the same minima as a target DFT energy is also able to find lower or similar energy structures in over 50\% of cases. This ``Easy Potential'' converges in fewer steps than a standard model trained on true energies and forces, which further accelerates calculations. Its success illustrates a key point: learned potentials can locate energy minima even when the model has high force errors. The main requirement for structure optimisation is simply that the learned potential has the correct minima. Since learned potentials are fast and scale linearly with system size, our results open the possibility of quickly finding ground states for large systems.
ETA Prediction with Graph Neural Networks in Google Maps
Aug 25, 2021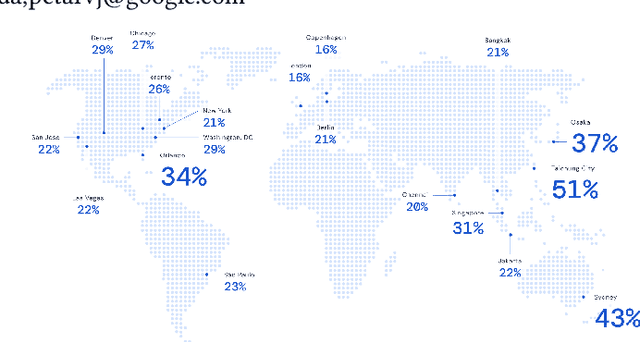


Travel-time prediction constitutes a task of high importance in transportation networks, with web mapping services like Google Maps regularly serving vast quantities of travel time queries from users and enterprises alike. Further, such a task requires accounting for complex spatiotemporal interactions (modelling both the topological properties of the road network and anticipating events -- such as rush hours -- that may occur in the future). Hence, it is an ideal target for graph representation learning at scale. Here we present a graph neural network estimator for estimated time of arrival (ETA) which we have deployed in production at Google Maps. While our main architecture consists of standard GNN building blocks, we further detail the usage of training schedule methods such as MetaGradients in order to make our model robust and production-ready. We also provide prescriptive studies: ablating on various architectural decisions and training regimes, and qualitative analyses on real-world situations where our model provides a competitive edge. Our GNN proved powerful when deployed, significantly reducing negative ETA outcomes in several regions compared to the previous production baseline (40+% in cities like Sydney).
Large-scale graph representation learning with very deep GNNs and self-supervision
Jul 20, 2021
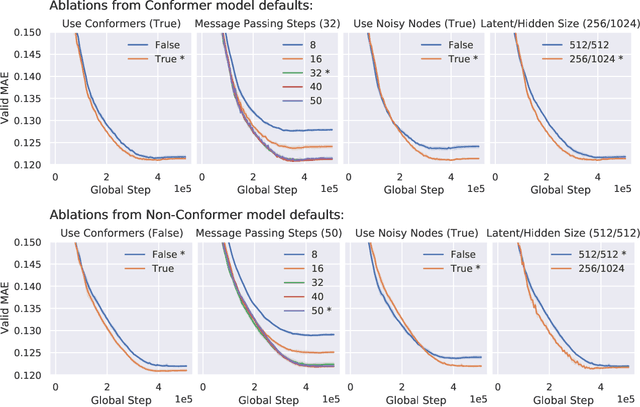
Effectively and efficiently deploying graph neural networks (GNNs) at scale remains one of the most challenging aspects of graph representation learning. Many powerful solutions have only ever been validated on comparatively small datasets, often with counter-intuitive outcomes -- a barrier which has been broken by the Open Graph Benchmark Large-Scale Challenge (OGB-LSC). We entered the OGB-LSC with two large-scale GNNs: a deep transductive node classifier powered by bootstrapping, and a very deep (up to 50-layer) inductive graph regressor regularised by denoising objectives. Our models achieved an award-level (top-3) performance on both the MAG240M and PCQM4M benchmarks. In doing so, we demonstrate evidence of scalable self-supervised graph representation learning, and utility of very deep GNNs -- both very important open issues. Our code is publicly available at: https://github.com/deepmind/deepmind-research/tree/master/ogb_lsc.
Generating Images with Sparse Representations
Mar 05, 2021
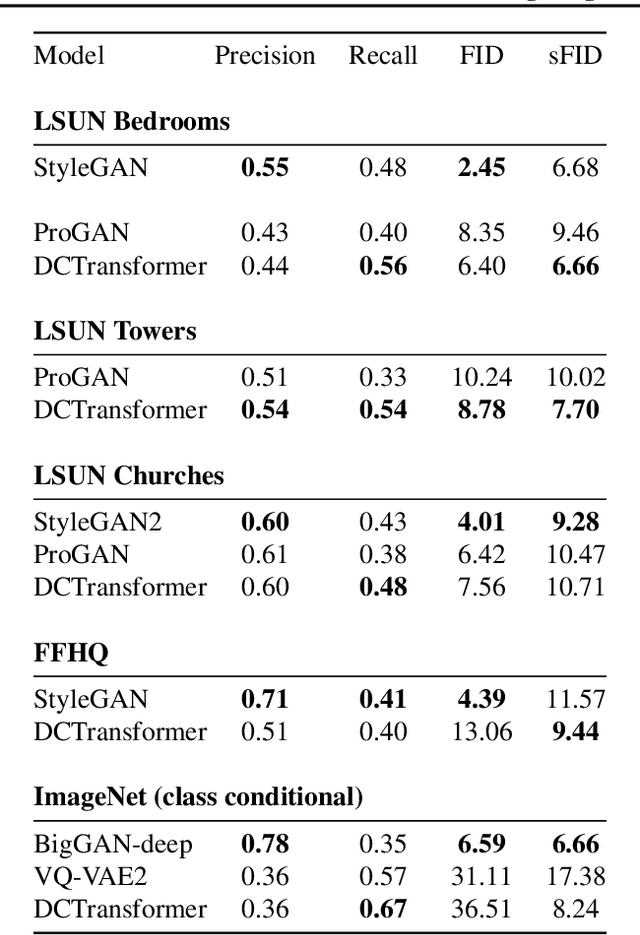
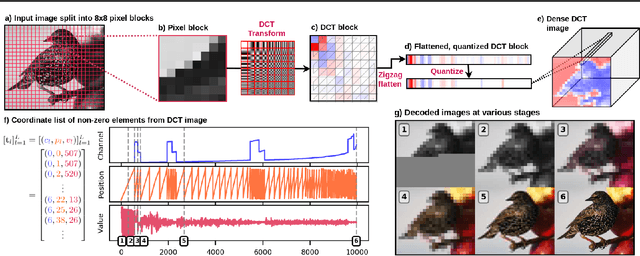
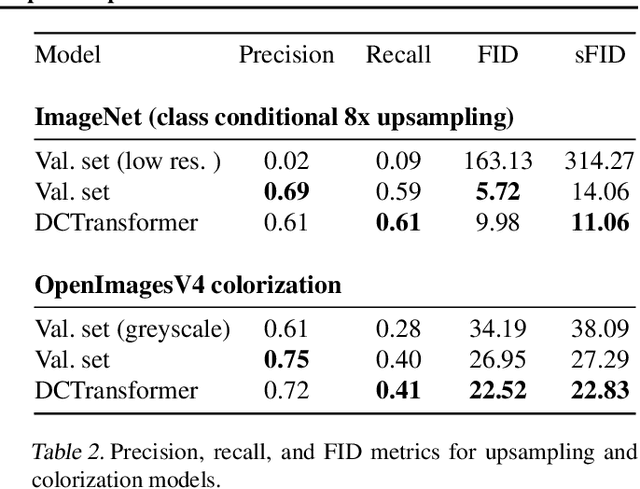
The high dimensionality of images presents architecture and sampling-efficiency challenges for likelihood-based generative models. Previous approaches such as VQ-VAE use deep autoencoders to obtain compact representations, which are more practical as inputs for likelihood-based models. We present an alternative approach, inspired by common image compression methods like JPEG, and convert images to quantized discrete cosine transform (DCT) blocks, which are represented sparsely as a sequence of DCT channel, spatial location, and DCT coefficient triples. We propose a Transformer-based autoregressive architecture, which is trained to sequentially predict the conditional distribution of the next element in such sequences, and which scales effectively to high resolution images. On a range of image datasets, we demonstrate that our approach can generate high quality, diverse images, with sample metric scores competitive with state of the art methods. We additionally show that simple modifications to our method yield effective image colorization and super-resolution models.
Learning Mesh-Based Simulation with Graph Networks
Oct 07, 2020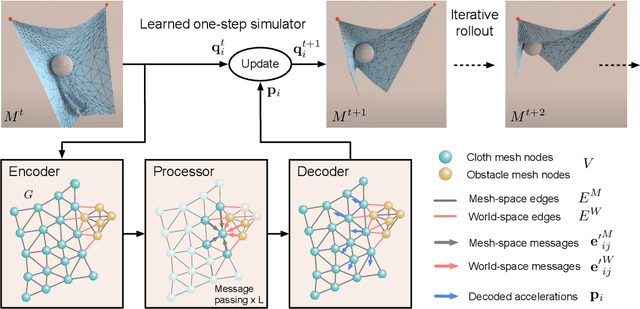
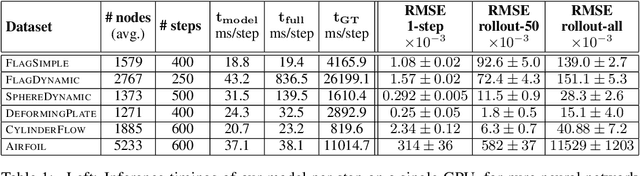
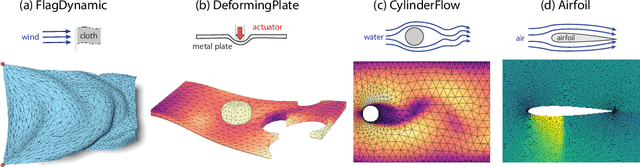
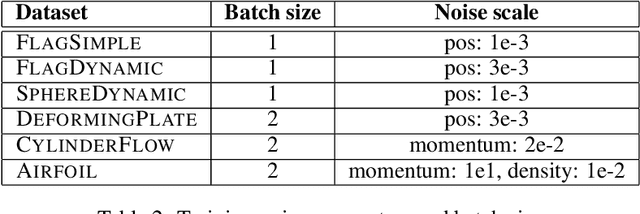
Mesh-based simulations are central to modeling complex physical systems in many disciplines across science and engineering. Mesh representations support powerful numerical integration methods and their resolution can be adapted to strike favorable trade-offs between accuracy and efficiency. However, high-dimensional scientific simulations are very expensive to run, and solvers and parameters must often be tuned individually to each system studied. Here we introduce MeshGraphNets, a framework for learning mesh-based simulations using graph neural networks. Our model can be trained to pass messages on a mesh graph and to adapt the mesh discretization during forward simulation. Our results show it can accurately predict the dynamics of a wide range of physical systems, including aerodynamics, structural mechanics, and cloth. The model's adaptivity supports learning resolution-independent dynamics and can scale to more complex state spaces at test time. Our method is also highly efficient, running 1-2 orders of magnitude faster than the simulation on which it is trained. Our approach broadens the range of problems on which neural network simulators can operate and promises to improve the efficiency of complex, scientific modeling tasks.
PolyGen: An Autoregressive Generative Model of 3D Meshes
Feb 23, 2020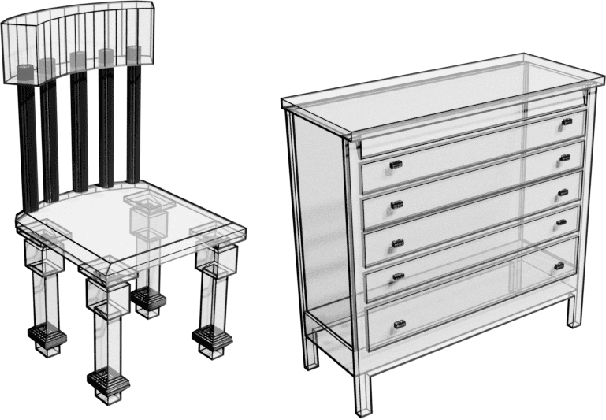
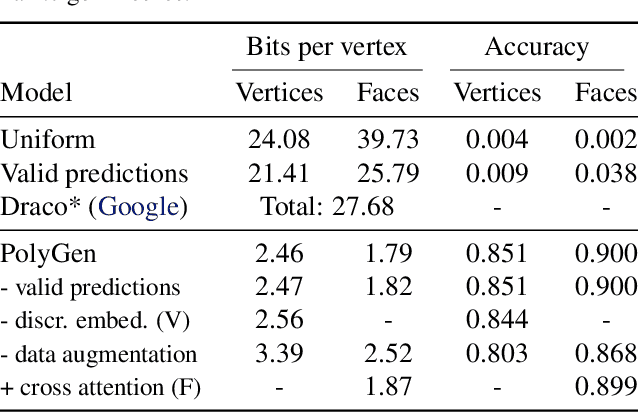
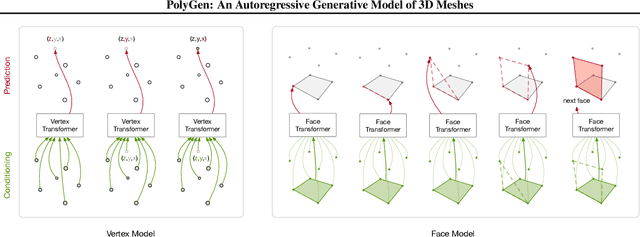
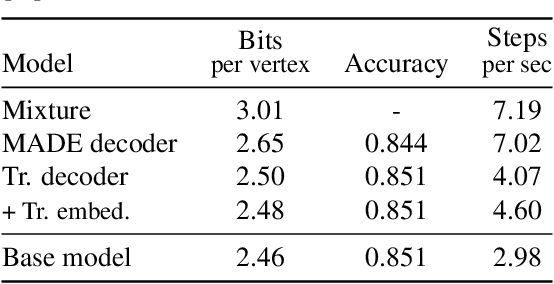
Polygon meshes are an efficient representation of 3D geometry, and are of central importance in computer graphics, robotics and games development. Existing learning-based approaches have avoided the challenges of working with 3D meshes, instead using alternative object representations that are more compatible with neural architectures and training approaches. We present an approach which models the mesh directly, predicting mesh vertices and faces sequentially using a Transformer-based architecture. Our model can condition on a range of inputs, including object classes, voxels, and images, and because the model is probabilistic it can produce samples that capture uncertainty in ambiguous scenarios. We show that the model is capable of producing high-quality, usable meshes, and establish log-likelihood benchmarks for the mesh-modelling task. We also evaluate the conditional models on surface reconstruction metrics against alternative methods, and demonstrate competitive performance despite not training directly on this task.
Learning to Simulate Complex Physics with Graph Networks
Feb 21, 2020
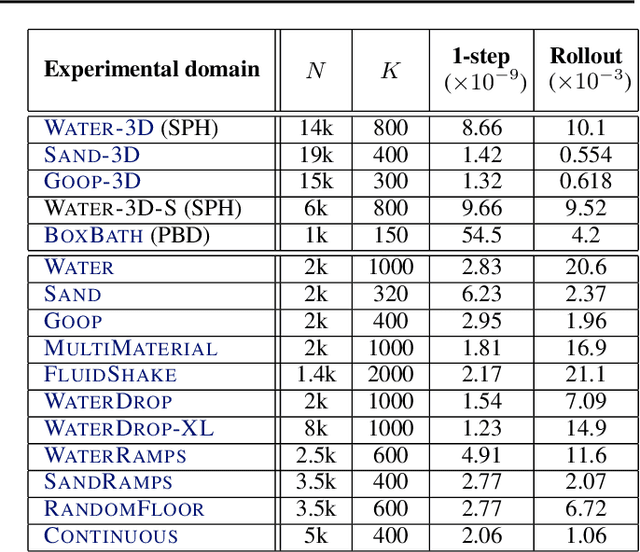
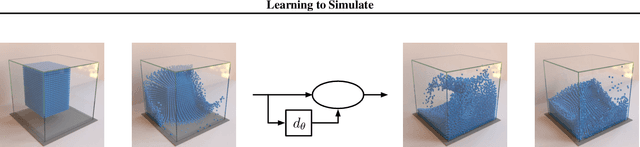
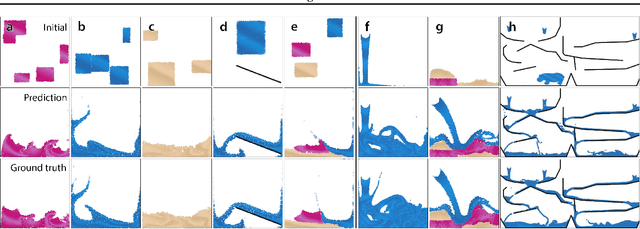
Here we present a general framework for learning simulation, and provide a single model implementation that yields state-of-the-art performance across a variety of challenging physical domains, involving fluids, rigid solids, and deformable materials interacting with one another. Our framework---which we term "Graph Network-based Simulators" (GNS)---represents the state of a physical system with particles, expressed as nodes in a graph, and computes dynamics via learned message-passing. Our results show that our model can generalize from single-timestep predictions with thousands of particles during training, to different initial conditions, thousands of timesteps, and at least an order of magnitude more particles at test time. Our model was robust to hyperparameter choices across various evaluation metrics: the main determinants of long-term performance were the number of message-passing steps, and mitigating the accumulation of error by corrupting the training data with noise. Our GNS framework is the most accurate general-purpose learned physics simulator to date, and holds promise for solving a wide range of complex forward and inverse problems.
Combining Q-Learning and Search with Amortized Value Estimates
Jan 10, 2020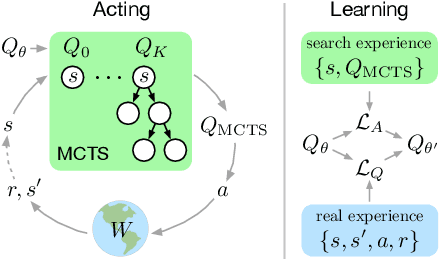
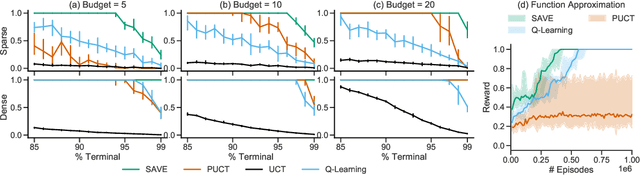
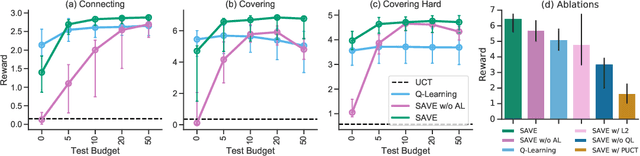
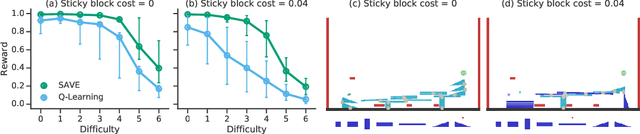
We introduce "Search with Amortized Value Estimates" (SAVE), an approach for combining model-free Q-learning with model-based Monte-Carlo Tree Search (MCTS). In SAVE, a learned prior over state-action values is used to guide MCTS, which estimates an improved set of state-action values. The new Q-estimates are then used in combination with real experience to update the prior. This effectively amortizes the value computation performed by MCTS, resulting in a cooperative relationship between model-free learning and model-based search. SAVE can be implemented on top of any Q-learning agent with access to a model, which we demonstrate by incorporating it into agents that perform challenging physical reasoning tasks and Atari. SAVE consistently achieves higher rewards with fewer training steps, and---in contrast to typical model-based search approaches---yields strong performance with very small search budgets. By combining real experience with information computed during search, SAVE demonstrates that it is possible to improve on both the performance of model-free learning and the computational cost of planning.
Object-oriented state editing for HRL
Oct 31, 2019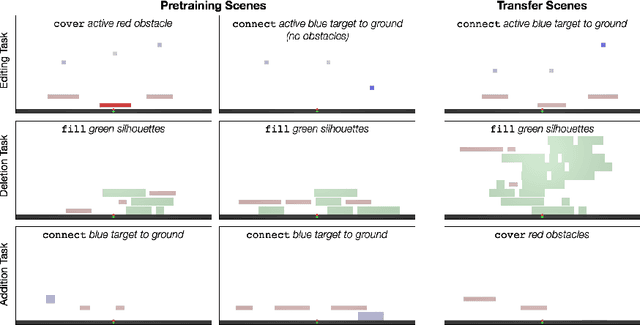
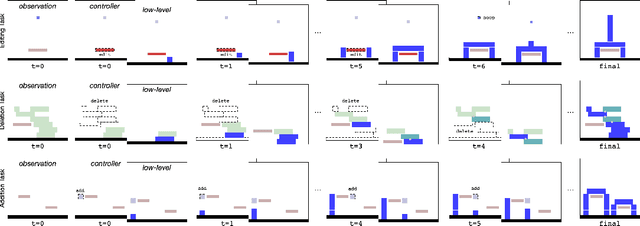

We introduce agents that use object-oriented reasoning to consider alternate states of the world in order to more quickly find solutions to problems. Specifically, a hierarchical controller directs a low-level agent to behave as if objects in the scene were added, deleted, or modified. The actions taken by the controller are defined over a graph-based representation of the scene, with actions corresponding to adding, deleting, or editing the nodes of a graph. We present preliminary results on three environments, demonstrating that our approach can achieve similar levels of reward as non-hierarchical agents, but with better data efficiency.
Structured agents for physical construction
May 13, 2019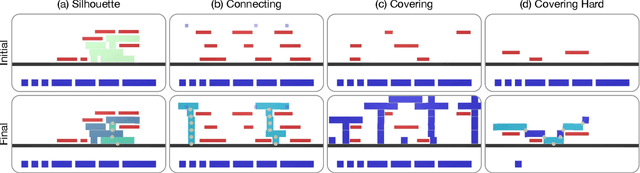
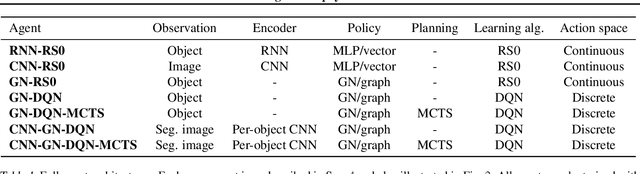
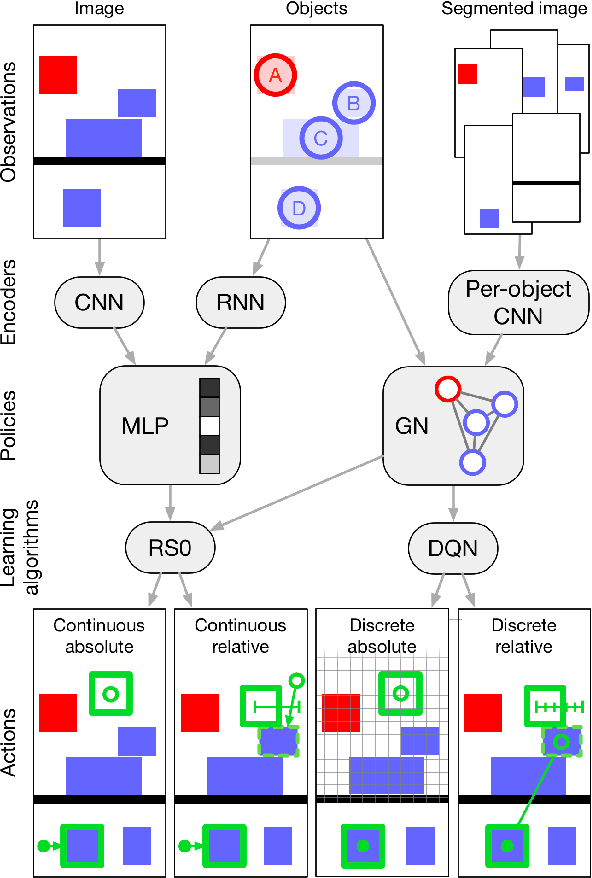
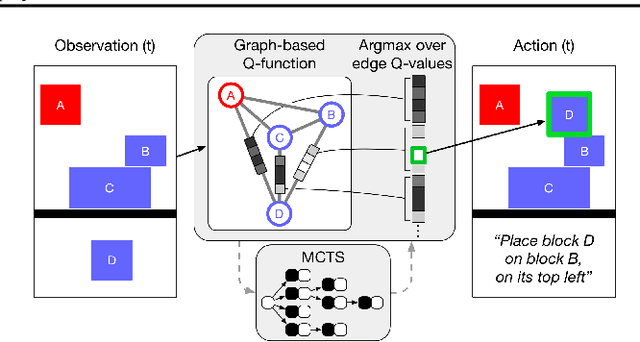
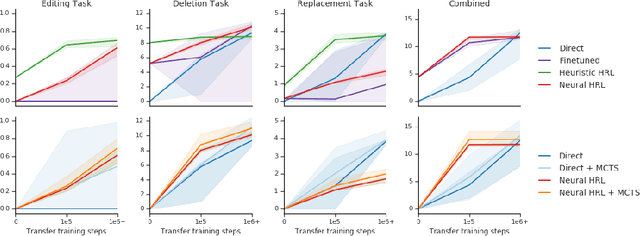
Physical construction---the ability to compose objects, subject to physical dynamics, to serve some function---is fundamental to human intelligence. We introduce a suite of challenging physical construction tasks inspired by how children play with blocks, such as matching a target configuration, stacking blocks to connect objects together, and creating shelter-like structures over target objects. We examine how a range of deep reinforcement learning agents fare on these challenges, and introduce several new approaches which provide superior performance. Our results show that agents which use structured representations (e.g., objects and scene graphs) and structured policies (e.g., object-centric actions) outperform those which use less structured representations, and generalize better beyond their training when asked to reason about larger scenes. Model-based agents which use Monte-Carlo Tree Search also outperform strictly model-free agents in our most challenging construction problems. We conclude that approaches which combine structured representations and reasoning with powerful learning are a key path toward agents that possess rich intuitive physics, scene understanding, and planning.