 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Constrained Imitation Learning
Aug 20, 2025



Policy learning under action constraints plays a central role in ensuring safe behaviors in various robot control and resource allocation applications. In this paper, we study a new problem setting termed Action-Constrained Imitation Learning (ACIL), where an action-constrained imitator aims to learn from a demonstrative expert with larger action space. The fundamental challenge of ACIL lies in the unavoidable mismatch of occupancy measure between the expert and the imitator caused by the action constraints. We tackle this mismatch through \textit{trajectory alignment} and propose DTWIL, which replaces the original expert demonstrations with a surrogate dataset that follows similar state trajectories while adhering to the action constraints. Specifically, we recast trajectory alignment as a planning problem and solve it via Model Predictive Control, which aligns the surrogate trajectories with the expert trajectories based on the Dynamic Time Warping (DTW) distance. Through extensive experiments, we demonstrate that learning from the dataset generated by DTWIL significantly enhances performance across multiple robot control tasks and outperforms various benchmark imitation learning algorithms in terms of sample efficiency. Our code is publicly available at https://github.com/NYCU-RL-Bandits-Lab/ACRL-Baselines.
IGDrivSim: A Benchmark for the Imitation Gap in Autonomous Driving
Nov 07, 2024



Developing autonomous vehicles that can navigate complex environments with human-level safety and efficiency is a central goal in self-driving research. A common approach to achieving this is imitation learning, where agents are trained to mimic human expert demonstrations collected from real-world driving scenarios. However, discrepancies between human perception and the self-driving car's sensors can introduce an \textit{imitation gap}, leading to imitation learning failures. In this work, we introduce \textbf{IGDrivSim}, a benchmark built on top of the Waymax simulator, designed to investigate the effects of the imitation gap in learning autonomous driving policy from human expert demonstrations. Our experiments show that this perception gap between human experts and self-driving agents can hinder the learning of safe and effective driving behaviors. We further show that combining imitation with reinforcement learning, using a simple penalty reward for prohibited behaviors, effectively mitigates these failures. Our code is open-sourced at: https://github.com/clemgris/IGDrivSim.git.
A Bayesian Solution To The Imitation Gap
Jun 29, 2024



In many real-world settings, an agent must learn to act in environments where no reward signal can be specified, but a set of expert demonstrations is available. Imitation learning (IL) is a popular framework for learning policies from such demonstrations. However, in some cases, differences in observability between the expert and the agent can give rise to an imitation gap such that the expert's policy is not optimal for the agent and a naive application of IL can fail catastrophically. In particular, if the expert observes the Markov state and the agent does not, then the expert will not demonstrate the information-gathering behavior needed by the agent but not the expert. In this paper, we propose a Bayesian solution to the Imitation Gap (BIG), first using the expert demonstrations, together with a prior specifying the cost of exploratory behavior that is not demonstrated, to infer a posterior over rewards with Bayesian inverse reinforcement learning (IRL). BIG then uses the reward posterior to learn a Bayes-optimal policy. Our experiments show that BIG, unlike IL, allows the agent to explore at test time when presented with an imitation gap, whilst still learning to behave optimally using expert demonstrations when no such gap exists.
SplAgger: Split Aggregation for Meta-Reinforcement Learning
Mar 08, 2024



A core ambition of reinforcement learning (RL) is the creation of agents capable of rapid learning in novel tasks. Meta-RL aims to achieve this by directly learning such agents. Black box methods do so by training off-the-shelf sequence models end-to-end. By contrast, task inference methods explicitly infer a posterior distribution over the unknown task, typically using distinct objectives and sequence models designed to enable task inference. Recent work has shown that task inference methods are not necessary for strong performance. However, it remains unclear whether task inference sequence models are beneficial even when task inference objectives are not. In this paper, we present strong evidence that task inference sequence models are still beneficial. In particular, we investigate sequence models with permutation invariant aggregation, which exploit the fact that, due to the Markov property, the task posterior does not depend on the order of data. We empirically confirm the advantage of permutation invariant sequence models without the use of task inference objectives. However, we also find, surprisingly, that there are multiple conditions under which permutation variance remains useful. Therefore, we propose SplAgger, which uses both permutation variant and invariant components to achieve the best of both worlds, outperforming all baselines on continuous control and memory environments.
Distilling Morphology-Conditioned Hypernetworks for Efficient Universal Morphology Control
Feb 09, 2024



Learning a universal policy across different robot morphologies can significantly improve learning efficiency and enable zero-shot generalization to unseen morphologies. However, learning a highly performant universal policy requires sophisticated architectures like transformers (TF) that have larger memory and computational cost than simpler multi-layer perceptrons (MLP). To achieve both good performance like TF and high efficiency like MLP at inference time, we propose HyperDistill, which consists of: (1) A morphology-conditioned hypernetwork (HN) that generates robot-wise MLP policies, and (2) A policy distillation approach that is essential for successful training. We show that on UNIMAL, a benchmark with hundreds of diverse morphologies, HyperDistill performs as well as a universal TF teacher policy on both training and unseen test robots, but reduces model size by 6-14 times, and computational cost by 67-160 times in different environments. Our analysis attributes the efficiency advantage of HyperDistill at inference time to knowledge decoupling, i.e., the ability to decouple inter-task and intra-task knowledge, a general principle that could also be applied to improve inference efficiency in other domains.
Discovering General Reinforcement Learning Algorithms with Adversarial Environment Design
Oct 04, 2023



The past decade has seen vast progress in deep reinforcement learning (RL) on the back of algorithms manually designed by human researchers. Recently, it has been shown that it is possible to meta-learn update rules, with the hope of discovering algorithms that can perform well on a wide range of RL tasks. Despite impressive initial results from algorithms such as Learned Policy Gradient (LPG), there remains a generalization gap when these algorithms are applied to unseen environments. In this work, we examine how characteristics of the meta-training distribution impact the generalization performance of these algorithms. Motivated by this analysis and building on ideas from Unsupervised Environment Design (UED), we propose a novel approach for automatically generating curricula to maximize the regret of a meta-learned optimizer, in addition to a novel approximation of regret, which we name algorithmic regret (AR). The result is our method, General RL Optimizers Obtained Via Environment Design (GROOVE). In a series of experiments, we show that GROOVE achieves superior generalization to LPG, and evaluate AR against baseline metrics from UED, identifying it as a critical component of environment design in this setting. We believe this approach is a step towards the discovery of truly general RL algorithms, capable of solving a wide range of real-world environments.
Recurrent Hypernetworks are Surprisingly Strong in Meta-RL
Sep 26, 2023



Deep reinforcement learning (RL) is notoriously impractical to deploy due to sample inefficiency. Meta-RL directly addresses this sample inefficiency by learning to perform few-shot learning when a distribution of related tasks is available for meta-training. While many specialized meta-RL methods have been proposed, recent work suggests that end-to-end learning in conjunction with an off-the-shelf sequential model, such as a recurrent network, is a surprisingly strong baseline. However, such claims have been controversial due to limited supporting evidence, particularly in the face of prior work establishing precisely the opposite. In this paper, we conduct an empirical investigation. While we likewise find that a recurrent network can achieve strong performance, we demonstrate that the use of hypernetworks is crucial to maximizing their potential. Surprisingly, when combined with hypernetworks, the recurrent baselines that are far simpler than existing specialized methods actually achieve the strongest performance of all methods evaluated.
A Survey of Meta-Reinforcement Learning
Jan 19, 2023



While deep reinforcement learning (RL) has fueled multiple high-profile successes in machine learning, it is held back from more widespread adoption by its often poor data efficiency and the limited generality of the policies it produces. A promising approach for alleviating these limitations is to cast the development of better RL algorithms as a machine learning problem itself in a process called meta-RL. Meta-RL is most commonly studied in a problem setting where, given a distribution of tasks, the goal is to learn a policy that is capable of adapting to any new task from the task distribution with as little data as possible. In this survey, we describe the meta-RL problem setting in detail as well as its major variations. We discuss how, at a high level, meta-RL research can be clustered based on the presence of a task distribution and the learning budget available for each individual task. Using these clusters, we then survey meta-RL algorithms and applications. We conclude by presenting the open problems on the path to making meta-RL part of the standard toolbox for a deep RL practitioner.
Deconfounded Imitation Learning
Nov 04, 2022Standard imitation learning can fail when the expert demonstrators have different sensory inputs than the imitating agent. This is because partial observability gives rise to hidden confounders in the causal graph. We break down the space of confounded imitation learning problems and identify three settings with different data requirements in which the correct imitation policy can be identified. We then introduce an algorithm for deconfounded imitation learning, which trains an inference model jointly with a latent-conditional policy. At test time, the agent alternates between updating its belief over the latent and acting under the belief. We show in theory and practice that this algorithm converges to the correct interventional policy, solves the confounding issue, and can under certain assumptions achieve an asymptotically optimal imitation performance.
Hypernetworks in Meta-Reinforcement Learning
Oct 20, 2022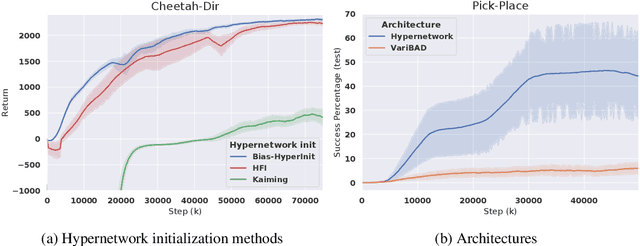

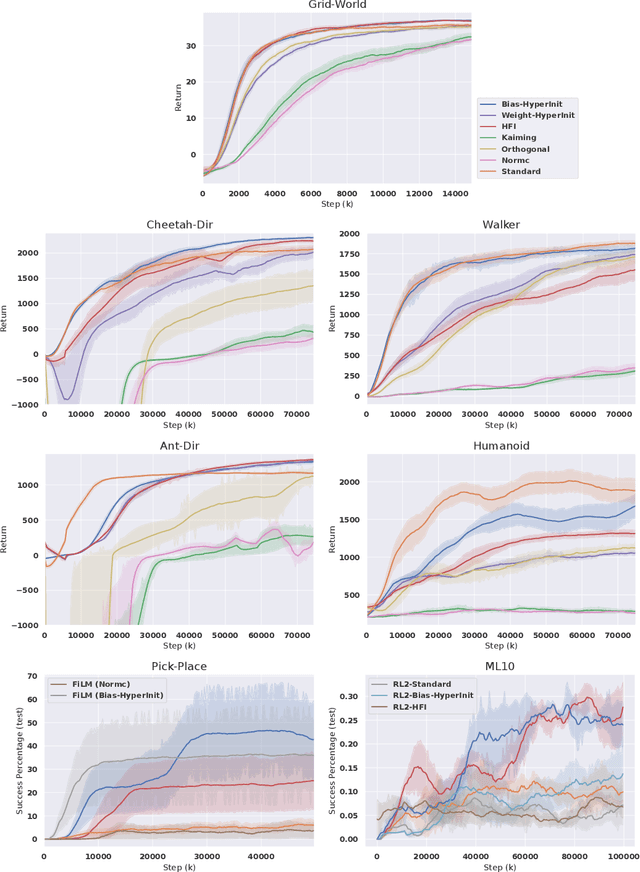
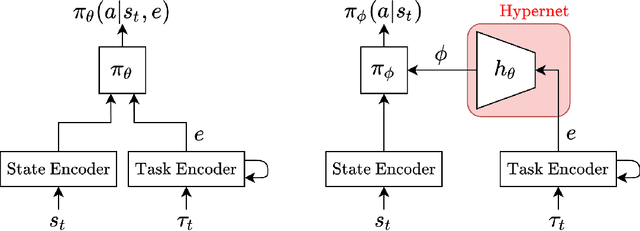
Training a reinforcement learning (RL) agent on a real-world robotics task remains generally impractical due to sample inefficiency. Multi-task RL and meta-RL aim to improve sample efficiency by generalizing over a distribution of related tasks. However, doing so is difficult in practice: In multi-task RL, state of the art methods often fail to outperform a degenerate solution that simply learns each task separately. Hypernetworks are a promising path forward since they replicate the separate policies of the degenerate solution while also allowing for generalization across tasks, and are applicable to meta-RL. However, evidence from supervised learning suggests hypernetwork performance is highly sensitive to the initialization. In this paper, we 1) show that hypernetwork initialization is also a critical factor in meta-RL, and that naive initializations yield poor performance; 2) propose a novel hypernetwork initialization scheme that matches or exceeds the performance of a state-of-the-art approach proposed for supervised settings, as well as being simpler and more general; and 3) use this method to show that hypernetworks can improve performance in meta-RL by evaluating on multiple simulated robotics benchmarks.