 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelightful Exploration
May 13, 2026Most exploration algorithms search broadly until uncertainty is resolved. When the action space is too large to resolve within budget, practitioners default to $\varepsilon$-greedy, which bounds disruption but spends its override blindly. We introduce \textit{Delight-gated exploration} (DE), a host--override rule that spends exploratory actions only when their prospective delight (expected improvement times surprisal) exceeds a gate price. This practical heuristic recovers a classical result: Pandora's reservation-value rule for costly search, with surprisal setting the effective inspection cost. Resolved arms exit the gate, fresh arms shut off above a prior-determined threshold, and selected linear-bandit overrides consume finite information budget. Across Bernoulli bandits, linear bandits, and tabular MDPs, the same hyperparameters transfer without retuning, and DE shows much weaker regret growth than Thompson Sampling and $\varepsilon$-greedy in the tested unresolved regimes. Delight improves acting for the same reason it improves learning: it prices scarce resources by the product of upside and surprisal.
Delightful Gradients Accelerate Corner Escape
May 12, 2026Softmax policy gradient converges at $O(1/t)$, but its transient behavior near sub-optimal corners of the simplex can be exponentially slow. The bottleneck is self-trapping: negative-advantage actions reinforce the corner policy and can initially push the optimal action backward. We study \emph{Delightful Policy Gradient} (DG), which gates each policy-gradient term by the product of advantage and action surprisal. For $K$-armed bandits, we prove that the zero-temperature limit of DG removes this corner-trapping mechanism on a quantitative sector near any sub-optimal corner, yielding a first-exit escape bound logarithmic in the initial probability ratio. At every fixed temperature, the same local mechanism persists because harmful actions are polynomially suppressed as they become rare. A key structural insight is that every action better than the corner action is an \emph{ally}: its contribution to escape is non-negative. Combining corner instability with a monotonic value improvement identity, we prove that DG converges globally to the optimal policy in both bandits and tabular MDPs at an asymptotic $O(1/t)$ rate. We also show, via an exact counterexample, that this tabular mechanism can fail under shared function approximation. In MNIST contextual bandits with a shared-parameter neural network, DG nevertheless recovers from bad initializations faster than standard policy gradient, suggesting that the counterexample marks a boundary of the theory rather than a practical prohibition.
Delightful Distributed Policy Gradient
Mar 20, 2026Distributed reinforcement learning trains on data from stale, buggy, or mismatched actors, producing actions with high surprisal (negative log-probability) under the learner's policy. The core difficulty is not surprising data per se, but \emph{negative learning from surprising data}. High-surprisal failures can dominate the update direction despite carrying little useful signal, while high-surprisal successes reveal opportunities the current policy would otherwise miss. The \textit{Delightful Policy Gradient} (DG) separates these cases by gating each update with delight, the product of advantage and surprisal, suppressing rare failures and amplifying rare successes without behavior probabilities. Under contaminated sampling, the cosine similarity between the standard policy gradient and the true gradient collapses, while DG's grows as the policy improves. No sign-blind reweighting, including exact importance sampling, can reproduce this effect. On MNIST with simulated staleness, DG without off-policy correction outperforms importance-weighted PG with exact behavior probabilities. On a transformer sequence task with staleness, actor bugs, reward corruption, and rare discovery, DG achieves roughly $10{\times}$ lower error. When all four frictions act simultaneously, its compute advantage is order-of-magnitude and grows with task complexity.
Does This Gradient Spark Joy?
Mar 20, 2026Policy gradient computes a backward pass for every sample, even though the backward pass is expensive and most samples carry little learning value. The Delightful Policy Gradient (DG) provides a forward-pass signal of learning value: \emph{delight}, the product of advantage and surprisal (negative log-probability). We introduce the \emph{Kondo gate}, which compares delight against a compute price and pays for a backward pass only when the sample is worth it, thereby tracing a quality--cost Pareto frontier. In bandits, zero-price gating preserves useful gradient signal while removing perpendicular noise, and delight is a more reliable screening signal than additive combinations of value and surprise. On MNIST and transformer token reversal, the Kondo gate skips most backward passes while retaining nearly all of DG's learning quality, with gains that grow as problems get harder and backward passes become more expensive. Because the gate tolerates approximate delight, a cheap forward pass can screen samples before expensive backpropagation, suggesting a speculative-decoding-for-training paradigm.
Delightful Policy Gradient
Mar 15, 2026Standard policy gradients weight each sampled action by advantage alone, regardless of how likely that action was under the current policy. This creates two pathologies: within a single decision context (e.g. one image or prompt), a rare negative-advantage action can disproportionately distort the update direction; across many such contexts in a batch, the expected gradient over-allocates budget to contexts the policy already handles well. We introduce the \textit{Delightful Policy Gradient} (DG), which gates each term with a sigmoid of \emph{delight}, the product of advantage and action surprisal (negative log-probability). For $K$-armed bandits, DG provably improves directional accuracy in a single context and, across multiple contexts, shifts the expected gradient strictly closer to the supervised cross-entropy oracle. This second effect is not variance reduction: it persists even with infinite samples. Empirically, DG outperforms REINFORCE, PPO, and advantage-weighted baselines across MNIST, transformer sequence modeling, and continuous control, with larger gains on harder tasks.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Approximate Thompson Sampling via Epistemic Neural Networks
Feb 18, 2023



Thompson sampling (TS) is a popular heuristic for action selection, but it requires sampling from a posterior distribution. Unfortunately, this can become computationally intractable in complex environments, such as those modeled using neural networks. Approximate posterior samples can produce effective actions, but only if they reasonably approximate joint predictive distributions of outputs across inputs. Notably, accuracy of marginal predictive distributions does not suffice. Epistemic neural networks (ENNs) are designed to produce accurate joint predictive distributions. We compare a range of ENNs through computational experiments that assess their performance in approximating TS across bandit and reinforcement learning environments. The results indicate that ENNs serve this purpose well and illustrate how the quality of joint predictive distributions drives performance. Further, we demonstrate that the \textit{epinet} -- a small additive network that estimates uncertainty -- matches the performance of large ensembles at orders of magnitude lower computational cost. This enables effective application of TS with computation that scales gracefully to complex environments.
Fine-Tuning Language Models via Epistemic Neural Networks
Nov 03, 2022



Large language models are now part of a powerful new paradigm in machine learning. These models learn a wide range of capabilities from training on large unsupervised text corpora. In many applications, these capabilities are then fine-tuned through additional training on specialized data to improve performance in that setting. In this paper, we augment these models with an epinet: a small additional network architecture that helps to estimate model uncertainty and form an epistemic neural network (ENN). ENNs are neural networks that can know what they don't know. We show that, using an epinet to prioritize uncertain data, we can fine-tune BERT on GLUE tasks to the same performance while using 2x less data. We also investigate performance in synthetic neural network generative models designed to build understanding. In each setting, using an epinet outperforms heuristic active learning schemes.
Robustness of Epinets against Distributional Shifts
Jul 01, 2022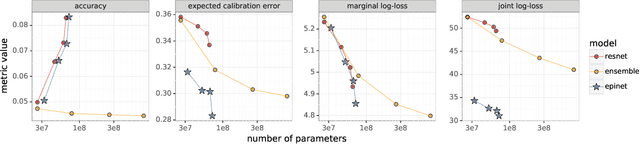
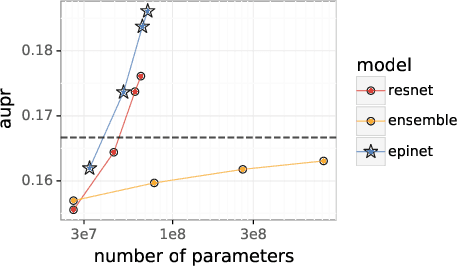
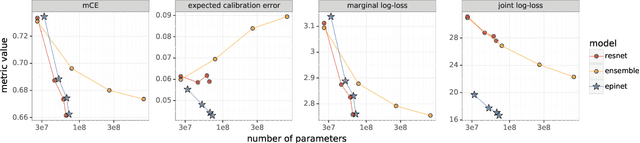
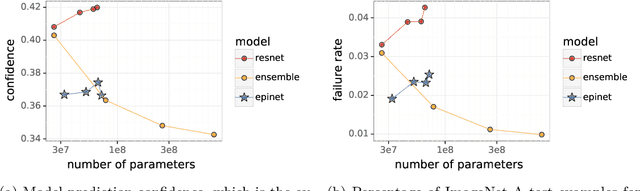
Recent work introduced the epinet as a new approach to uncertainty modeling in deep learning. An epinet is a small neural network added to traditional neural networks, which, together, can produce predictive distributions. In particular, using an epinet can greatly improve the quality of joint predictions across multiple inputs, a measure of how well a neural network knows what it does not know. In this paper, we examine whether epinets can offer similar advantages under distributional shifts. We find that, across ImageNet-A/O/C, epinets generally improve robustness metrics. Moreover, these improvements are more significant than those afforded by even very large ensembles at orders of magnitude lower computational costs. However, these improvements are relatively small compared to the outstanding issues in distributionally-robust deep learning. Epinets may be a useful tool in the toolbox, but they are far from the complete solution.