 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Learning from Language Feedback
Jun 12, 2025Interactively learning from observation and language feedback is an increasingly studied area driven by the emergence of large language model (LLM) agents. While impressive empirical demonstrations have been shown, so far a principled framing of these decision problems remains lacking. In this paper, we formalize the Learning from Language Feedback (LLF) problem, assert sufficient assumptions to enable learning despite latent rewards, and introduce $\textit{transfer eluder dimension}$ as a complexity measure to characterize the hardness of LLF problems. We show that transfer eluder dimension captures the intuition that information in the feedback changes the learning complexity of the LLF problem. We demonstrate cases where learning from rich language feedback can be exponentially faster than learning from reward. We develop a no-regret algorithm, called $\texttt{HELiX}$, that provably solves LLF problems through sequential interactions, with performance guarantees that scale with the transfer eluder dimension of the problem. Across several empirical domains, we show that $\texttt{HELiX}$ performs well even when repeatedly prompting LLMs does not work reliably. Our contributions mark a first step towards designing principled interactive learning algorithms from generic language feedback.
How to Solve Contextual Goal-Oriented Problems with Offline Datasets?
Aug 14, 2024



We present a novel method, Contextual goal-Oriented Data Augmentation (CODA), which uses commonly available unlabeled trajectories and context-goal pairs to solve Contextual Goal-Oriented (CGO) problems. By carefully constructing an action-augmented MDP that is equivalent to the original MDP, CODA creates a fully labeled transition dataset under training contexts without additional approximation error. We conduct a novel theoretical analysis to demonstrate CODA's capability to solve CGO problems in the offline data setup. Empirical results also showcase the effectiveness of CODA, which outperforms other baseline methods across various context-goal relationships of CGO problem. This approach offers a promising direction to solving CGO problems using offline datasets.
On the Statistical Efficiency of Reward-Free Exploration in Non-Linear RL
Jun 21, 2022
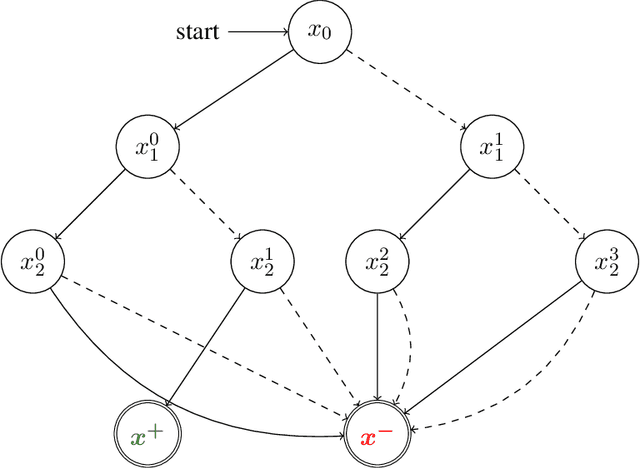
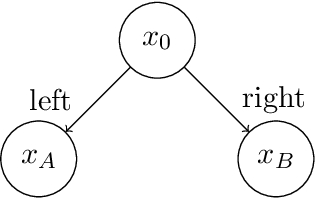
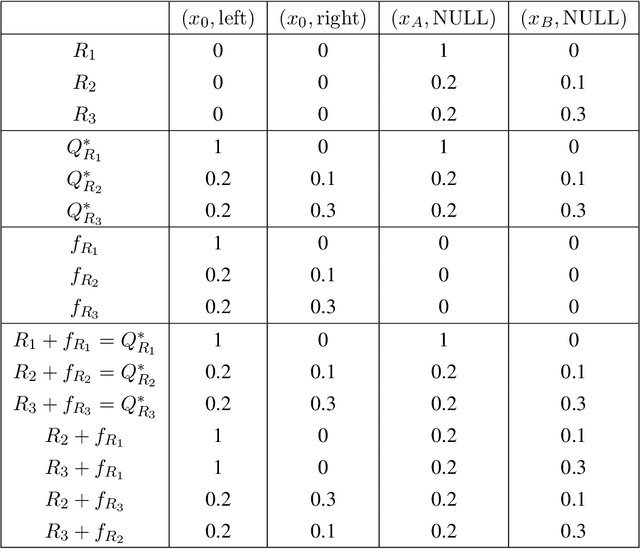
We study reward-free reinforcement learning (RL) under general non-linear function approximation, and establish sample efficiency and hardness results under various standard structural assumptions. On the positive side, we propose the RFOLIVE (Reward-Free OLIVE) algorithm for sample-efficient reward-free exploration under minimal structural assumptions, which covers the previously studied settings of linear MDPs (Jin et al., 2020b), linear completeness (Zanette et al., 2020b) and low-rank MDPs with unknown representation (Modi et al., 2021). Our analyses indicate that the explorability or reachability assumptions, previously made for the latter two settings, are not necessary statistically for reward-free exploration. On the negative side, we provide a statistical hardness result for both reward-free and reward-aware exploration under linear completeness assumptions when the underlying features are unknown, showing an exponential separation between low-rank and linear completeness settings.
Joint Learning-Based Stabilization of Multiple Unknown Linear Systems
Jan 01, 2022
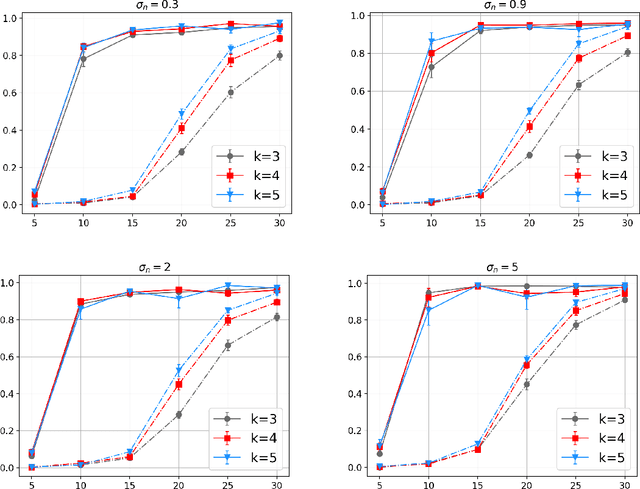
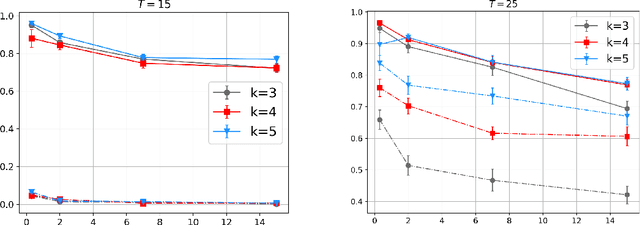
Learning-based control of linear systems received a lot of attentions recently. In popular settings, the true dynamical models are unknown to the decision-maker and need to be interactively learned by applying control inputs to the systems. Unlike the matured literature of efficient reinforcement learning policies for adaptive control of a single system, results on joint learning of multiple systems are not currently available. Especially, the important problem of fast and reliable joint-stabilization remains unaddressed and so is the focus of this work. We propose a novel joint learning-based stabilization algorithm for quickly learning stabilizing policies for all systems understudy, from the data of unstable state trajectories. The presented procedure is shown to be notably effective such that it stabilizes the family of dynamical systems in an extremely short time period.
Joint Learning of Linear Time-Invariant Dynamical Systems
Dec 22, 2021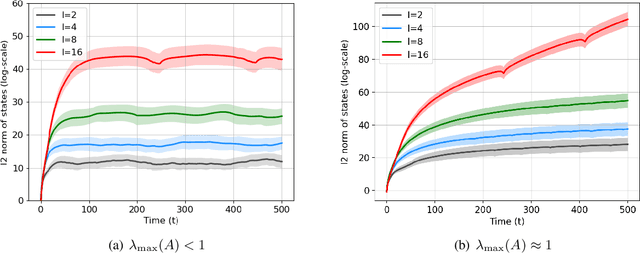
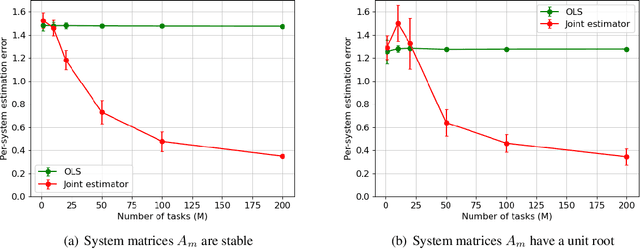
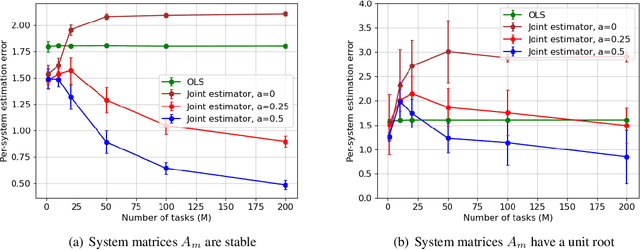
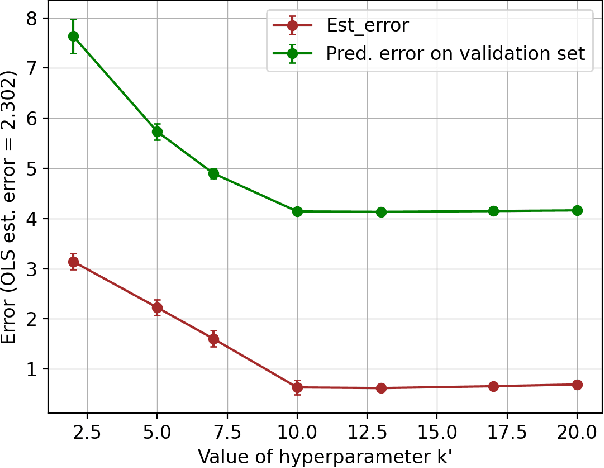
Learning the parameters of a linear time-invariant dynamical system (LTIDS) is a problem of current interest. In many applications, one is interested in jointly learning the parameters of multiple related LTIDS, which remains unexplored to date. To that end, we develop a joint estimator for learning the transition matrices of LTIDS that share common basis matrices. Further, we establish finite-time error bounds that depend on the underlying sample size, dimension, number of tasks, and spectral properties of the transition matrices. The results are obtained under mild regularity assumptions and showcase the gains from pooling information across LTIDS, in comparison to learning each system separately. We also study the impact of misspecifying the joint structure of the transition matrices and show that the established results are robust in the presence of moderate misspecifications.
Model-free Representation Learning and Exploration in Low-rank MDPs
Feb 14, 2021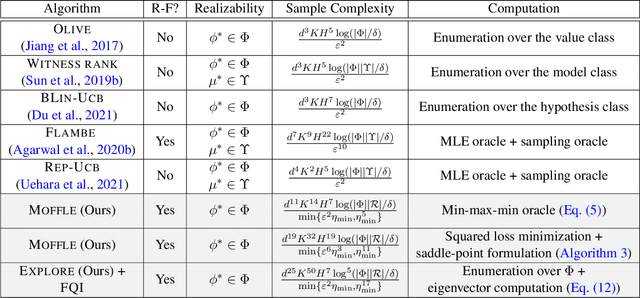
The low rank MDP has emerged as an important model for studying representation learning and exploration in reinforcement learning. With a known representation, several model-free exploration strategies exist. In contrast, all algorithms for the unknown representation setting are model-based, thereby requiring the ability to model the full dynamics. In this work, we present the first model-free representation learning algorithms for low rank MDPs. The key algorithmic contribution is a new minimax representation learning objective, for which we provide variants with differing tradeoffs in their statistical and computational properties. We interleave this representation learning step with an exploration strategy to cover the state space in a reward-free manner. The resulting algorithms are provably sample efficient and can accommodate general function approximation to scale to complex environments.
Clinician-in-the-Loop Decision Making: Reinforcement Learning with Near-Optimal Set-Valued Policies
Jul 24, 2020

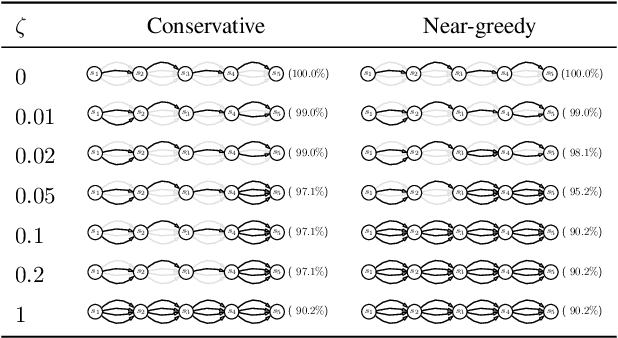
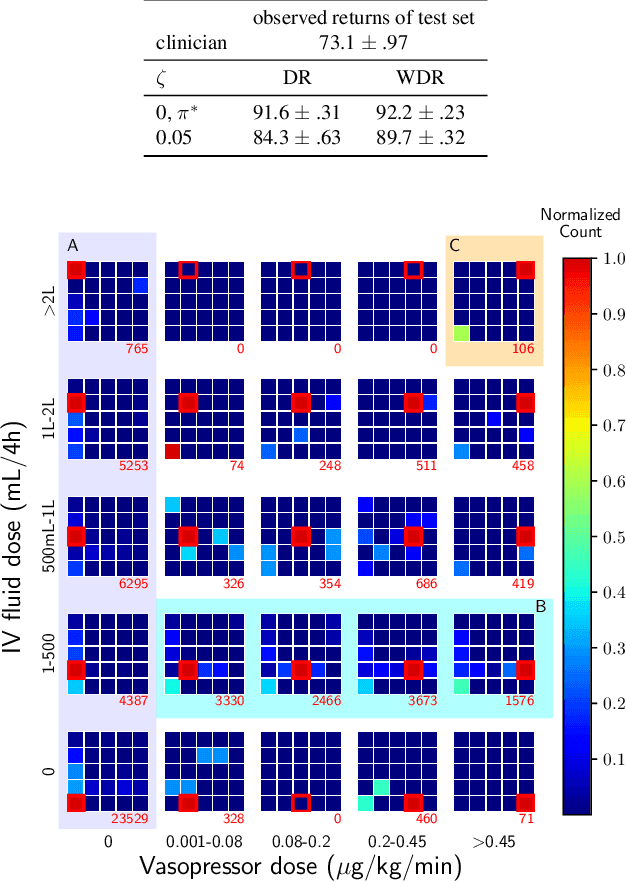
Standard reinforcement learning (RL) aims to find an optimal policy that identifies the best action for each state. However, in healthcare settings, many actions may be near-equivalent with respect to the reward (e.g., survival). We consider an alternative objective -- learning set-valued policies to capture near-equivalent actions that lead to similar cumulative rewards. We propose a model-free algorithm based on temporal difference learning and a near-greedy heuristic for action selection. We analyze the theoretical properties of the proposed algorithm, providing optimality guarantees and demonstrate our approach on simulated environments and a real clinical task. Empirically, the proposed algorithm exhibits good convergence properties and discovers meaningful near-equivalent actions. Our work provides theoretical, as well as practical, foundations for clinician/human-in-the-loop decision making, in which humans (e.g., clinicians, patients) can incorporate additional knowledge (e.g., side effects, patient preference) when selecting among near-equivalent actions.
Sample Complexity of Reinforcement Learning using Linearly Combined Model Ensembles
Oct 23, 2019Reinforcement learning (RL) methods have been shown to be capable of learning intelligent behavior in rich domains. However, this has largely been done in simulated domains without adequate focus on the process of building the simulator. In this paper, we consider a setting where we have access to an ensemble of pre-trained and possibly inaccurate simulators (models). We approximate the real environment using a state-dependent linear combination of the ensemble, where the coefficients are determined by the given state features and some unknown parameters. Our proposed algorithm provably learns a near-optimal policy with a sample complexity polynomial in the number of unknown parameters, and incurs no dependence on the size of the state (or action) space. As an extension, we also consider the more challenging problem of model selection, where the state features are unknown and can be chosen from a large candidate set. We provide exponential lower bounds that illustrate the fundamental hardness of this problem, and develop a provably efficient algorithm under additional natural assumptions.
Metareasoning in Modular Software Systems: On-the-Fly Configuration using Reinforcement Learning with Rich Contextual Representations
May 12, 2019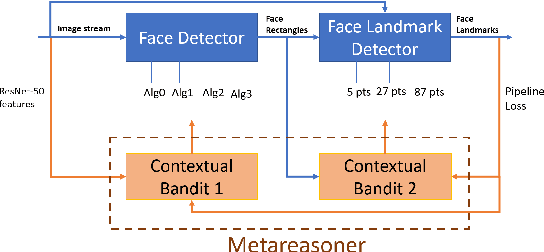

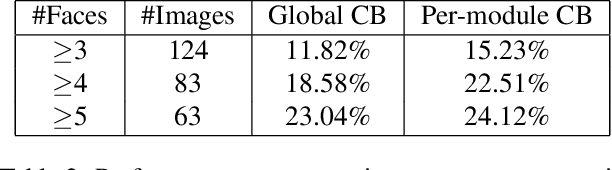
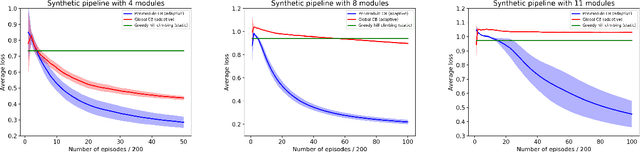
Assemblies of modular subsystems are being pressed into service to perform sensing, reasoning, and decision making in high-stakes, time-critical tasks in such areas as transportation, healthcare, and industrial automation. We address the opportunity to maximize the utility of an overall computing system by employing reinforcement learning to guide the configuration of the set of interacting modules that comprise the system. The challenge of doing system-wide optimization is a combinatorial problem. Local attempts to boost the performance of a specific module by modifying its configuration often leads to losses in overall utility of the system's performance as the distribution of inputs to downstream modules changes drastically. We present metareasoning techniques which consider a rich representation of the input, monitor the state of the entire pipeline, and adjust the configuration of modules on-the-fly so as to maximize the utility of a system's operation. We show significant improvement in both real-world and synthetic pipelines across a variety of reinforcement learning techniques.
Contextual Markov Decision Processes using Generalized Linear Models
Mar 14, 2019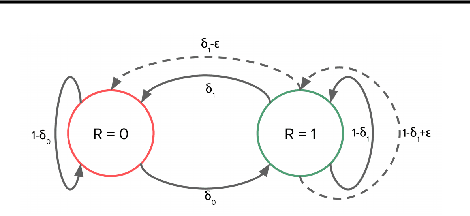
We consider the recently proposed reinforcement learning (RL) framework of Contextual Markov Decision Processes (CMDP), where the agent has a sequence of episodic interactions with tabular environments chosen from a possibly infinite set. The parameters of these environments depend on a context vector that is available to the agent at the start of each episode. In this paper, we propose a no-regret online RL algorithm in the setting where the MDP parameters are obtained from the context using generalized linear models (GLMs). The proposed algorithm \texttt{GL-ORL} relies on efficient online updates and is also memory efficient. Our analysis of the algorithm gives new results in the logit link case and improves previous bounds in the linear case. Our algorithm uses efficient Online Newton Step updates to build confidence sets. Moreover, for any strongly convex link function, we also show a generic conversion from any online no-regret algorithm to confidence sets.