 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Detection-Guided Preference Optimization for Clinical Summarization
May 27, 2026Large language models (LLMs) have shown promise on summarization tasks, but they often produce hallucinations, which are unsupported or incorrect statements that limit their reliability in specialized healthcare applications. We introduce \itermodelfull (\itermodel), an inference-time method that leverages hallucination detectors to guide iterative summary revisions toward factual corrections. Building on this, we propose \itermodel for Preference Learning (\model), which converts detector-guided refinement trajectories into preference pairs for model finetuning. Extensive experiments show that our methods substantially reduce hallucinations for Llama and Gemma models in summarizing real-world clinical notes from \MimicIV. For example, \itermodel reduces 24\% and \model reduces 48\% hallucinations in Llama-3.1-8B-Instruct. Importantly, both methods preserve summary fluency, coherence, and relevance according to human expert and LLM-Jury evaluations. Together, these results demonstrate that detection-informed refinement and preference learning offer an automated solution for improving factual faithfulness in clinical summarization.
Test-Time Strategies for More Efficient and Accurate Agentic RAG
Mar 12, 2026Retrieval-Augmented Generation (RAG) systems face challenges with complex, multihop questions, and agentic frameworks such as Search-R1 (Jin et al., 2025), which operates iteratively, have been proposed to address these complexities. However, such approaches can introduce inefficiencies, including repetitive retrieval of previously processed information and challenges in contextualizing retrieved results effectively within the current generation prompt. Such issues can lead to unnecessary retrieval turns, suboptimal reasoning, inaccurate answers, and increased token consumption. In this paper, we investigate test-time modifications to the Search-R1 pipeline to mitigate these identified shortcomings. Specifically, we explore the integration of two components and their combination: a contextualization module to better integrate relevant information from retrieved documents into reasoning, and a de-duplication module that replaces previously retrieved documents with the next most relevant ones. We evaluate our approaches using the HotpotQA (Yang et al., 2018) and the Natural Questions (Kwiatkowski et al., 2019) datasets, reporting the exact match (EM) score, an LLM-as-a-Judge assessment of answer correctness, and the average number of turns. Our best-performing variant, utilizing GPT-4.1-mini for contextualization, achieves a 5.6% increase in EM score and reduces the number of turns by 10.5% compared to the Search-R1 baseline, demonstrating improved answer accuracy and retrieval efficiency.
Hop, Skip, and Overthink: Diagnosing Why Reasoning Models Fumble during Multi-Hop Analysis
Aug 06, 2025The emergence of reasoning models and their integration into practical AI chat bots has led to breakthroughs in solving advanced math, deep search, and extractive question answering problems that requires a complex and multi-step thought process. Yet, a complete understanding of why these models hallucinate more than general purpose language models is missing. In this investigative study, we systematicallyexplore reasoning failures of contemporary language models on multi-hop question answering tasks. We introduce a novel, nuanced error categorization framework that examines failures across three critical dimensions: the diversity and uniqueness of source documents involved ("hops"), completeness in capturing relevant information ("coverage"), and cognitive inefficiency ("overthinking"). Through rigorous hu-man annotation, supported by complementary automated metrics, our exploration uncovers intricate error patterns often hidden by accuracy-centric evaluations. This investigative approach provides deeper insights into the cognitive limitations of current models and offers actionable guidance toward enhancing reasoning fidelity, transparency, and robustness in future language modeling efforts.
Active Measurement: Efficient Estimation at Scale
Jul 02, 2025AI has the potential to transform scientific discovery by analyzing vast datasets with little human effort. However, current workflows often do not provide the accuracy or statistical guarantees that are needed. We introduce active measurement, a human-in-the-loop AI framework for scientific measurement. An AI model is used to predict measurements for individual units, which are then sampled for human labeling using importance sampling. With each new set of human labels, the AI model is improved and an unbiased Monte Carlo estimate of the total measurement is refined. Active measurement can provide precise estimates even with an imperfect AI model, and requires little human effort when the AI model is very accurate. We derive novel estimators, weighting schemes, and confidence intervals, and show that active measurement reduces estimation error compared to alternatives in several measurement tasks.
OpenUnlearning: Accelerating LLM Unlearning via Unified Benchmarking of Methods and Metrics
Jun 14, 2025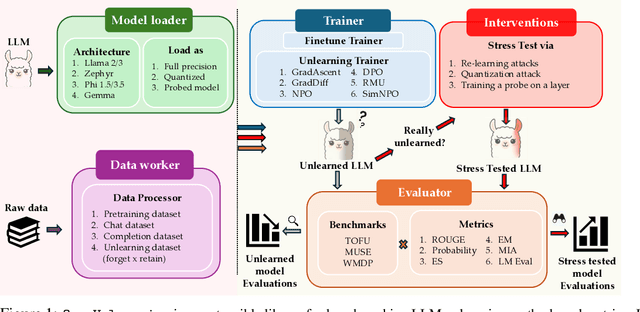



Robust unlearning is crucial for safely deploying large language models (LLMs) in environments where data privacy, model safety, and regulatory compliance must be ensured. Yet the task is inherently challenging, partly due to difficulties in reliably measuring whether unlearning has truly occurred. Moreover, fragmentation in current methodologies and inconsistent evaluation metrics hinder comparative analysis and reproducibility. To unify and accelerate research efforts, we introduce OpenUnlearning, a standardized and extensible framework designed explicitly for benchmarking both LLM unlearning methods and metrics. OpenUnlearning integrates 9 unlearning algorithms and 16 diverse evaluations across 3 leading benchmarks (TOFU, MUSE, and WMDP) and also enables analyses of forgetting behaviors across 450+ checkpoints we publicly release. Leveraging OpenUnlearning, we propose a novel meta-evaluation benchmark focused specifically on assessing the faithfulness and robustness of evaluation metrics themselves. We also benchmark diverse unlearning methods and provide a comparative analysis against an extensive evaluation suite. Overall, we establish a clear, community-driven pathway toward rigorous development in LLM unlearning research.
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Dec 17, 2024The rise of large language models (LLMs) has created a significant disparity: industrial research labs with their computational resources, expert teams, and advanced infrastructures, can effectively fine-tune LLMs, while individual developers and small organizations face barriers due to limited resources. In this paper, we aim to bridge this gap by presenting a comprehensive study on supervised fine-tuning of LLMs using instruction-tuning datasets spanning diverse knowledge domains and skills. We focus on small-sized LLMs (3B to 7B parameters) for their cost-efficiency and accessibility. We explore various training configurations and strategies across four open-source pre-trained models. We provide detailed documentation of these configurations, revealing findings that challenge several common training practices, including hyperparameter recommendations from TULU and phased training recommended by Orca. Key insights from our work include: (i) larger batch sizes paired with lower learning rates lead to improved model performance on benchmarks such as MMLU, MTBench, and Open LLM Leaderboard; (ii) early-stage training dynamics, such as lower gradient norms and higher loss values, are strong indicators of better final model performance, enabling early termination of sub-optimal runs and significant computational savings; (iii) through a thorough exploration of hyperparameters like warmup steps and learning rate schedules, we provide guidance for practitioners and find that certain simplifications do not compromise performance; and (iv) we observed no significant difference in performance between phased and stacked training strategies, but stacked training is simpler and more sample efficient. With these findings holding robustly across datasets and models, we hope this study serves as a guide for practitioners fine-tuning small LLMs and promotes a more inclusive environment for LLM research.
Quantifying reliance on external information over parametric knowledge during Retrieval Augmented Generation (RAG) using mechanistic analysis
Oct 01, 2024Retrieval Augmented Generation (RAG) is a widely used approach for leveraging external context in several natural language applications such as question answering and information retrieval. Yet, the exact nature in which a Language Model (LM) leverages this non-parametric memory or retrieved context isn't clearly understood. This paper mechanistically examines the RAG pipeline to highlight that LMs demonstrate a "shortcut'' effect and have a strong bias towards utilizing the retrieved context to answer questions, while relying minimally on model priors. We propose (a) Causal Mediation Analysis; for proving that parametric memory is minimally utilized when answering a question and (b) Attention Contributions and Knockouts for showing the last token residual stream do not get enriched from the subject token in the question, but gets enriched from tokens of RAG-context. We find this pronounced "shortcut'' behaviour to be true across both LLMs (e.g.,LlaMa) and SLMs (e.g., Phi)
From RAGs to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries
Jun 18, 2024



Retrieval Augmented Generation (RAG) enriches the ability of language models to reason using external context to augment responses for a given user prompt. This approach has risen in popularity due to practical applications in various applications of language models in search, question/answering, and chat-bots. However, the exact nature of how this approach works isn't clearly understood. In this paper, we mechanistically examine the RAG pipeline to highlight that language models take shortcut and have a strong bias towards utilizing only the context information to answer the question, while relying minimally on their parametric memory. We probe this mechanistic behavior in language models with: (i) Causal Mediation Analysis to show that the parametric memory is minimally utilized when answering a question and (ii) Attention Contributions and Knockouts to show that the last token residual stream do not get enriched from the subject token in the question, but gets enriched from other informative tokens in the context. We find this pronounced shortcut behaviour true across both LLaMa and Phi family of models.
Comparing Neighbors Together Makes it Easy: Jointly Comparing Multiple Candidates for Efficient and Effective Retrieval
May 21, 2024



A common retrieve-and-rerank paradigm involves retrieving a broad set of relevant candidates using a scalable bi-encoder, followed by expensive but more accurate cross-encoders to a limited candidate set. However, this small subset often leads to error propagation from the bi-encoders, thereby restricting the performance of the overall pipeline. To address these issues, we propose the Comparing Multiple Candidates (CMC) framework, which compares a query and multiple candidate embeddings jointly through shallow self-attention layers. While providing contextualized representations, CMC is scalable enough to handle multiple comparisons simultaneously, where comparing 2K candidates takes only twice as long as comparing 100. Practitioners can use CMC as a lightweight and effective reranker to improve top-1 accuracy. Moreover, when integrated with another retriever, CMC reranking can function as a virtually enhanced retriever. This configuration adds only negligible latency compared to using a single retriever (virtual), while significantly improving recall at K (enhanced).} Through experiments, we demonstrate that CMC, as a virtually enhanced retriever, significantly improves Recall@k (+6.7, +3.5%-p for R@16, R@64) compared to the initial retrieval stage on the ZeSHEL dataset. Meanwhile, we conduct experiments for direct reranking on entity, passage, and dialogue ranking. The results indicate that CMC is not only faster (11x) than cross-encoders but also often more effective, with improved prediction performance in Wikipedia entity linking (+0.7%-p) and DSTC7 dialogue ranking (+3.3%-p). The code and link to datasets are available at https://github.com/yc-song/cmc
WorldValuesBench: A Large-Scale Benchmark Dataset for Multi-Cultural Value Awareness of Language Models
Apr 25, 2024



The awareness of multi-cultural human values is critical to the ability of language models (LMs) to generate safe and personalized responses. However, this awareness of LMs has been insufficiently studied, since the computer science community lacks access to the large-scale real-world data about multi-cultural values. In this paper, we present WorldValuesBench, a globally diverse, large-scale benchmark dataset for the multi-cultural value prediction task, which requires a model to generate a rating response to a value question based on demographic contexts. Our dataset is derived from an influential social science project, World Values Survey (WVS), that has collected answers to hundreds of value questions (e.g., social, economic, ethical) from 94,728 participants worldwide. We have constructed more than 20 million examples of the type "(demographic attributes, value question) $\rightarrow$ answer" from the WVS responses. We perform a case study using our dataset and show that the task is challenging for strong open and closed-source models. On merely $11.1\%$, $25.0\%$, $72.2\%$, and $75.0\%$ of the questions, Alpaca-7B, Vicuna-7B-v1.5, Mixtral-8x7B-Instruct-v0.1, and GPT-3.5 Turbo can respectively achieve $<0.2$ Wasserstein 1-distance from the human normalized answer distributions. WorldValuesBench opens up new research avenues in studying limitations and opportunities in multi-cultural value awareness of LMs.