 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECI: Effective Contrastive Information to Evaluate Hard-Negatives
Mar 22, 2026Hard negatives play a critical role in training and fine-tuning dense retrieval models, as they are semantically similar to positive documents yet non-relevant, and correctly distinguishing them is essential for improving retrieval accuracy. However, identifying effective hard negatives typically requires extensive ablation studies involving repeated fine-tuning with different negative sampling strategies and hyperparameters, resulting in substantial computational cost. In this paper, we introduce ECI: Effective Contrastive Information , a theoretically grounded metric grounded in Information Theory and Information Retrieval principles that enables practitioners to assess the quality of hard negatives prior to model fine-tuning. ECI evaluates negatives by optimizing the trade-off between Information Capacity the logarithmic bound on mutual information determined by set size and Discriminative Efficiency, a harmonic balance of Signal Magnitude (Hardness) and Safety (Max-Margin). Unlike heuristic approaches, ECI strictly penalizes unsafe, false-positive negatives prevalent in generative methods. We evaluate ECI across hard-negative sets mined or generated using BM25, cross-encoders, and large language models. Our results demonstrate that ECI accurately predicts downstream retrieval performance, identifying that hybrid strategies (BM25+Cross-Encoder) offer the optimal balance of volume and reliability, significantly reducing the need for costly end-to-end ablation studies.
Scaling Laws for Reranking in Information Retrieval
Mar 05, 2026Scaling laws have been observed across a wide range of tasks, such as natural language generation and dense retrieval, where performance follows predictable patterns as model size, data, and compute grow. However, these scaling laws are insufficient for understanding the scaling behavior of multi-stage retrieval systems, which typically include a reranking stage. In large-scale multi-stage retrieval systems, reranking is the final and most influential step before presenting a ranked list of items to the end user. In this work, we present the first systematic study of scaling laws for rerankers by analyzing performance across model sizes and data budgets for three popular paradigms: pointwise, pairwise, and listwise reranking. Using a detailed case study with cross-encoder rerankers, we demonstrate that performance follows a predictable power law. This regularity allows us to accurately forecast the performance of larger models for some metrics more than others using smaller-scale experiments, offering a robust methodology for saving significant computational resources. For example, we accurately estimate the NDCG of a 1B-parameter model by training and evaluating only smaller models (up to 400M parameters), in both in-domain as well as out-of-domain settings. Our experiments encompass span several loss functions, models and metrics and demonstrate that downstream metrics like NDCG, MAP (Mean Avg Precision) show reliable scaling behavior and can be forecasted accurately at scale, while highlighting the limitations of metrics like Contrastive Entropy and MRR (Mean Reciprocal Rank) which do not follow predictable scaling behavior in all instances. Our results establish scaling principles for reranking and provide actionable insights for building industrial-grade retrieval systems.
From Native Memes to Global Moderation: Cross-Cultural Evaluation of Vision-Language Models for Hateful Meme Detection
Feb 11, 2026Cultural context profoundly shapes how people interpret online content, yet vision-language models (VLMs) remain predominantly trained through Western or English-centric lenses. This limits their fairness and cross-cultural robustness in tasks like hateful meme detection. We introduce a systematic evaluation framework designed to diagnose and quantify the cross-cultural robustness of state-of-the-art VLMs across multilingual meme datasets, analyzing three axes: (i) learning strategy (zero-shot vs. one-shot), (ii) prompting language (native vs. English), and (iii) translation effects on meaning and detection. Results show that the common ``translate-then-detect'' approach deteriorate performance, while culturally aligned interventions - native-language prompting and one-shot learning - significantly enhance detection. Our findings reveal systematic convergence toward Western safety norms and provide actionable strategies to mitigate such bias, guiding the design of globally robust multimodal moderation systems.
From Native Memes to Global Moderation: Cros-Cultural Evaluation of Vision-Language Models for Hateful Meme Detection
Feb 07, 2026Cultural context profoundly shapes how people interpret online content, yet vision-language models (VLMs) remain predominantly trained through Western or English-centric lenses. This limits their fairness and cross-cultural robustness in tasks like hateful meme detection. We introduce a systematic evaluation framework designed to diagnose and quantify the cross-cultural robustness of state-of-the-art VLMs across multilingual meme datasets, analyzing three axes: (i) learning strategy (zero-shot vs. one-shot), (ii) prompting language (native vs. English), and (iii) translation effects on meaning and detection. Results show that the common ``translate-then-detect'' approach deteriorate performance, while culturally aligned interventions - native-language prompting and one-shot learning - significantly enhance detection. Our findings reveal systematic convergence toward Western safety norms and provide actionable strategies to mitigate such bias, guiding the design of globally robust multimodal moderation systems.
Quantifying reliance on external information over parametric knowledge during Retrieval Augmented Generation (RAG) using mechanistic analysis
Oct 01, 2024Retrieval Augmented Generation (RAG) is a widely used approach for leveraging external context in several natural language applications such as question answering and information retrieval. Yet, the exact nature in which a Language Model (LM) leverages this non-parametric memory or retrieved context isn't clearly understood. This paper mechanistically examines the RAG pipeline to highlight that LMs demonstrate a "shortcut'' effect and have a strong bias towards utilizing the retrieved context to answer questions, while relying minimally on model priors. We propose (a) Causal Mediation Analysis; for proving that parametric memory is minimally utilized when answering a question and (b) Attention Contributions and Knockouts for showing the last token residual stream do not get enriched from the subject token in the question, but gets enriched from tokens of RAG-context. We find this pronounced "shortcut'' behaviour to be true across both LLMs (e.g.,LlaMa) and SLMs (e.g., Phi)
From RAGs to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries
Jun 18, 2024



Retrieval Augmented Generation (RAG) enriches the ability of language models to reason using external context to augment responses for a given user prompt. This approach has risen in popularity due to practical applications in various applications of language models in search, question/answering, and chat-bots. However, the exact nature of how this approach works isn't clearly understood. In this paper, we mechanistically examine the RAG pipeline to highlight that language models take shortcut and have a strong bias towards utilizing only the context information to answer the question, while relying minimally on their parametric memory. We probe this mechanistic behavior in language models with: (i) Causal Mediation Analysis to show that the parametric memory is minimally utilized when answering a question and (ii) Attention Contributions and Knockouts to show that the last token residual stream do not get enriched from the subject token in the question, but gets enriched from other informative tokens in the context. We find this pronounced shortcut behaviour true across both LLaMa and Phi family of models.
Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads
Feb 21, 2022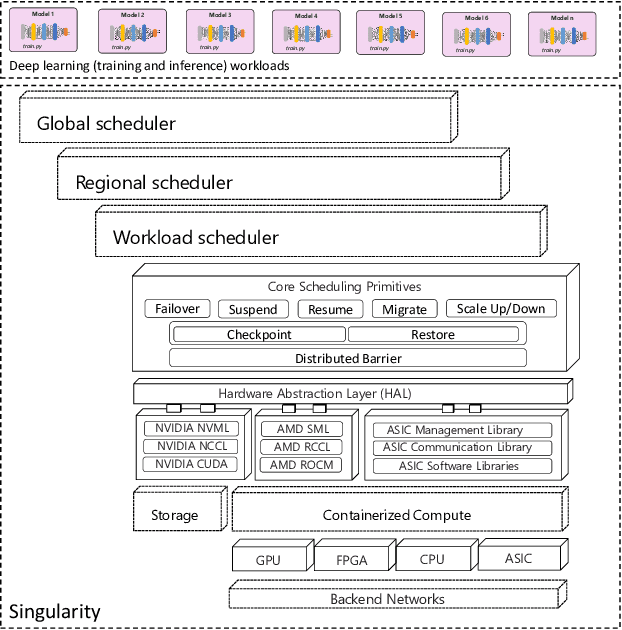
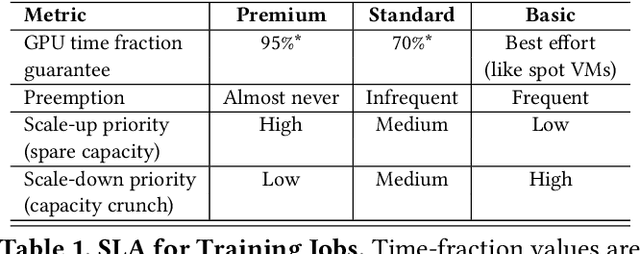
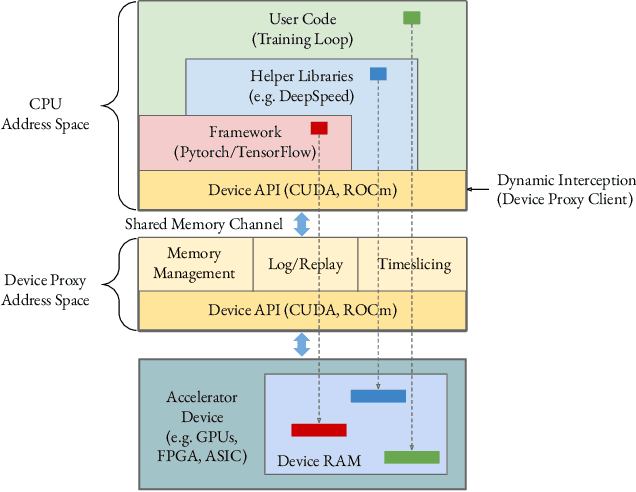
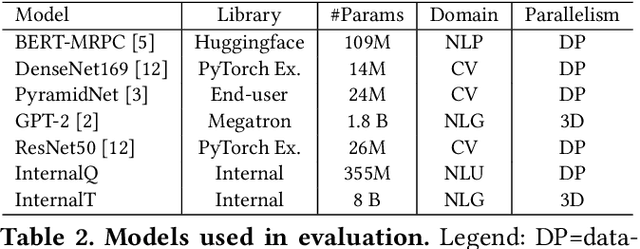
Lowering costs by driving high utilization across deep learning workloads is a crucial lever for cloud providers. We present Singularity, Microsoft's globally distributed scheduling service for highly-efficient and reliable execution of deep learning training and inference workloads. At the heart of Singularity is a novel, workload-aware scheduler that can transparently preempt and elastically scale deep learning workloads to drive high utilization without impacting their correctness or performance, across a global fleet of AI accelerators (e.g., GPUs, FPGAs). All jobs in Singularity are preemptable, migratable, and dynamically resizable (elastic) by default: a live job can be dynamically and transparently (a) preempted and migrated to a different set of nodes, cluster, data center or a region and resumed exactly from the point where the execution was preempted, and (b) resized (i.e., elastically scaled-up/down) on a varying set of accelerators of a given type. Our mechanisms are transparent in that they do not require the user to make any changes to their code or require using any custom libraries that may limit flexibility. Additionally, our approach significantly improves the reliability of deep learning workloads. We show that the resulting efficiency and reliability gains with Singularity are achieved with negligible impact on the steady-state performance. Finally, our design approach is agnostic of DNN architectures and handles a variety of parallelism strategies (e.g., data/pipeline/model parallelism).