 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHop, Skip, and Overthink: Diagnosing Why Reasoning Models Fumble during Multi-Hop Analysis
Aug 06, 2025The emergence of reasoning models and their integration into practical AI chat bots has led to breakthroughs in solving advanced math, deep search, and extractive question answering problems that requires a complex and multi-step thought process. Yet, a complete understanding of why these models hallucinate more than general purpose language models is missing. In this investigative study, we systematicallyexplore reasoning failures of contemporary language models on multi-hop question answering tasks. We introduce a novel, nuanced error categorization framework that examines failures across three critical dimensions: the diversity and uniqueness of source documents involved ("hops"), completeness in capturing relevant information ("coverage"), and cognitive inefficiency ("overthinking"). Through rigorous hu-man annotation, supported by complementary automated metrics, our exploration uncovers intricate error patterns often hidden by accuracy-centric evaluations. This investigative approach provides deeper insights into the cognitive limitations of current models and offers actionable guidance toward enhancing reasoning fidelity, transparency, and robustness in future language modeling efforts.
Quantifying reliance on external information over parametric knowledge during Retrieval Augmented Generation (RAG) using mechanistic analysis
Oct 01, 2024Retrieval Augmented Generation (RAG) is a widely used approach for leveraging external context in several natural language applications such as question answering and information retrieval. Yet, the exact nature in which a Language Model (LM) leverages this non-parametric memory or retrieved context isn't clearly understood. This paper mechanistically examines the RAG pipeline to highlight that LMs demonstrate a "shortcut'' effect and have a strong bias towards utilizing the retrieved context to answer questions, while relying minimally on model priors. We propose (a) Causal Mediation Analysis; for proving that parametric memory is minimally utilized when answering a question and (b) Attention Contributions and Knockouts for showing the last token residual stream do not get enriched from the subject token in the question, but gets enriched from tokens of RAG-context. We find this pronounced "shortcut'' behaviour to be true across both LLMs (e.g.,LlaMa) and SLMs (e.g., Phi)
From RAGs to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries
Jun 18, 2024



Retrieval Augmented Generation (RAG) enriches the ability of language models to reason using external context to augment responses for a given user prompt. This approach has risen in popularity due to practical applications in various applications of language models in search, question/answering, and chat-bots. However, the exact nature of how this approach works isn't clearly understood. In this paper, we mechanistically examine the RAG pipeline to highlight that language models take shortcut and have a strong bias towards utilizing only the context information to answer the question, while relying minimally on their parametric memory. We probe this mechanistic behavior in language models with: (i) Causal Mediation Analysis to show that the parametric memory is minimally utilized when answering a question and (ii) Attention Contributions and Knockouts to show that the last token residual stream do not get enriched from the subject token in the question, but gets enriched from other informative tokens in the context. We find this pronounced shortcut behaviour true across both LLaMa and Phi family of models.
Topic Segmentation of Semi-Structured and Unstructured Conversational Datasets using Language Models
Oct 26, 2023



Breaking down a document or a conversation into multiple contiguous segments based on its semantic structure is an important and challenging problem in NLP, which can assist many downstream tasks. However, current works on topic segmentation often focus on segmentation of structured texts. In this paper, we comprehensively analyze the generalization capabilities of state-of-the-art topic segmentation models on unstructured texts. We find that: (a) Current strategies of pre-training on a large corpus of structured text such as Wiki-727K do not help in transferability to unstructured conversational data. (b) Training from scratch with only a relatively small-sized dataset of the target unstructured domain improves the segmentation results by a significant margin. We stress-test our proposed Topic Segmentation approach by experimenting with multiple loss functions, in order to mitigate effects of imbalance in unstructured conversational datasets. Our empirical evaluation indicates that Focal Loss function is a robust alternative to Cross-Entropy and re-weighted Cross-Entropy loss function when segmenting unstructured and semi-structured chats.
On Surgical Fine-tuning for Language Encoders
Oct 25, 2023



Fine-tuning all the layers of a pre-trained neural language encoder (either using all the parameters or using parameter-efficient methods) is often the de-facto way of adapting it to a new task. We show evidence that for different downstream language tasks, fine-tuning only a subset of layers is sufficient to obtain performance that is close to and often better than fine-tuning all the layers in the language encoder. We propose an efficient metric based on the diagonal of the Fisher information matrix (FIM score), to select the candidate layers for selective fine-tuning. We show, empirically on GLUE and SuperGLUE tasks and across distinct language encoders, that this metric can effectively select layers leading to a strong downstream performance. Our work highlights that task-specific information corresponding to a given downstream task is often localized within a few layers, and tuning only those is sufficient for strong performance. Additionally, we demonstrate the robustness of the FIM score to rank layers in a manner that remains constant during the optimization process.
Topic Segmentation in the Wild: Towards Segmentation of Semi-structured & Unstructured Chats
Nov 27, 2022



Breaking down a document or a conversation into multiple contiguous segments based on its semantic structure is an important and challenging problem in NLP, which can assist many downstream tasks. However, current works on topic segmentation often focus on segmentation of structured texts. In this paper, we comprehensively analyze the generalization capabilities of state-of-the-art topic segmentation models on unstructured texts. We find that: (a) Current strategies of pre-training on a large corpus of structured text such as Wiki-727K do not help in transferability to unstructured texts. (b) Training from scratch with only a relatively small-sized dataset of the target unstructured domain improves the segmentation results by a significant margin.
SLATE: A Sequence Labeling Approach for Task Extraction from Free-form Inked Content
Nov 17, 2022



We present SLATE, a sequence labeling approach for extracting tasks from free-form content such as digitally handwritten (or "inked") notes on a virtual whiteboard. Our approach allows us to create a single, low-latency model to simultaneously perform sentence segmentation and classification of these sentences into task/non-task sentences. SLATE greatly outperforms a baseline two-model (sentence segmentation followed by classification model) approach, achieving a task F1 score of 84.4%, a sentence segmentation (boundary similarity) score of 88.4% and three times lower latency compared to the baseline. Furthermore, we provide insights into tackling challenges of performing NLP on the inking domain. We release both our code and dataset for this novel task.
On Optimizing Interventions in Shared Autonomy
Jan 01, 2022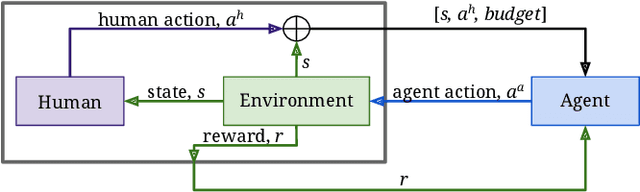

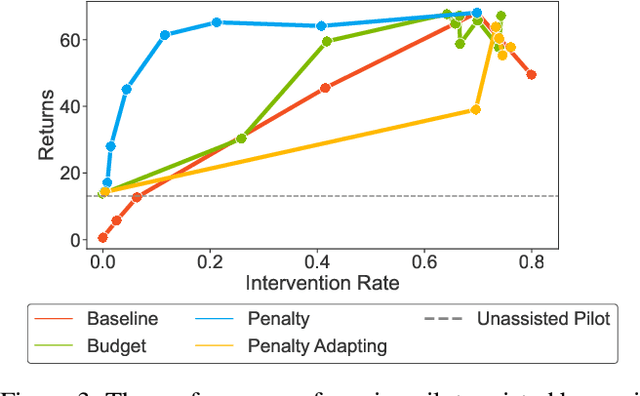
Shared autonomy refers to approaches for enabling an autonomous agent to collaborate with a human with the aim of improving human performance. However, besides improving performance, it may often also be beneficial that the agent concurrently accounts for preserving the user's experience or satisfaction of collaboration. In order to address this additional goal, we examine approaches for improving the user experience by constraining the number of interventions by the autonomous agent. We propose two model-free reinforcement learning methods that can account for both hard and soft constraints on the number of interventions. We show that not only does our method outperform the existing baseline, but also eliminates the need to manually tune a black-box hyperparameter for controlling the level of assistance. We also provide an in-depth analysis of intervention scenarios in order to further illuminate system understanding.
Optimal Resource Allocation for Serverless Queries
Jul 19, 2021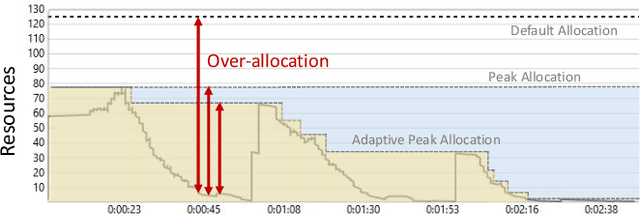
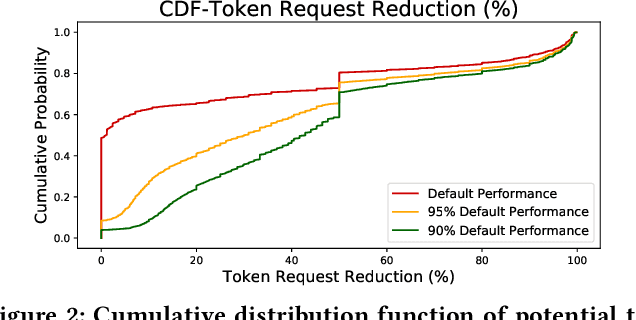

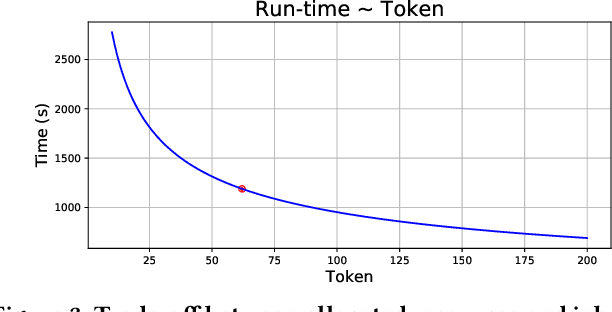
Optimizing resource allocation for analytical workloads is vital for reducing costs of cloud-data services. At the same time, it is incredibly hard for users to allocate resources per query in serverless processing systems, and they frequently misallocate by orders of magnitude. Unfortunately, prior work focused on predicting peak allocation while ignoring aggressive trade-offs between resource allocation and run-time. Additionally, these methods fail to predict allocation for queries that have not been observed in the past. In this paper, we tackle both these problems. We introduce a system for optimal resource allocation that can predict performance with aggressive trade-offs, for both new and past observed queries. We introduce the notion of a performance characteristic curve (PCC) as a parameterized representation that can compactly capture the relationship between resources and performance. To tackle training data sparsity, we introduce a novel data augmentation technique to efficiently synthesize the entire PCC using a single run of the query. Lastly, we demonstrate the advantages of a constrained loss function coupled with GNNs, over traditional ML methods, for capturing the domain specific behavior through an extensive experimental evaluation over SCOPE big data workloads at Microsoft.
Seagull: An Infrastructure for Load Prediction and Optimized Resource Allocation
Oct 16, 2020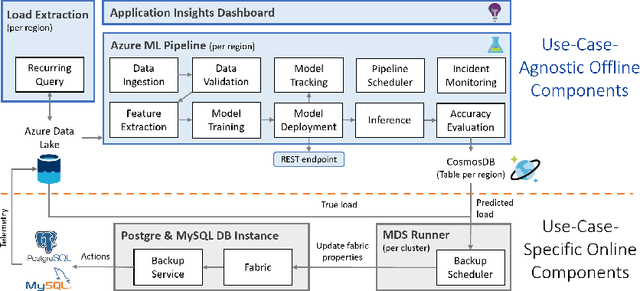
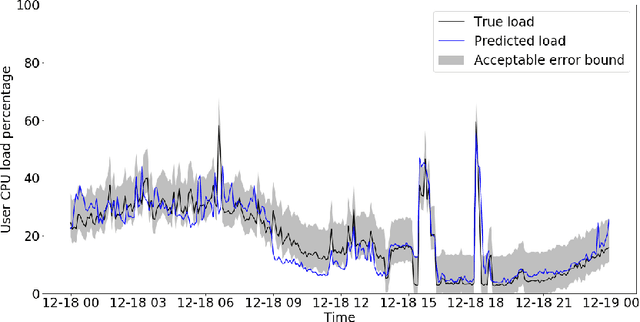
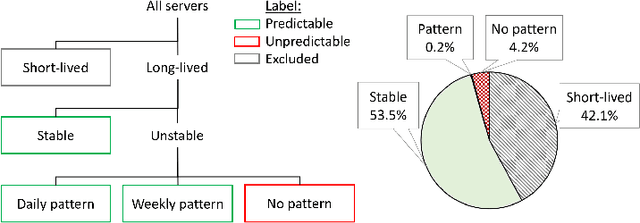
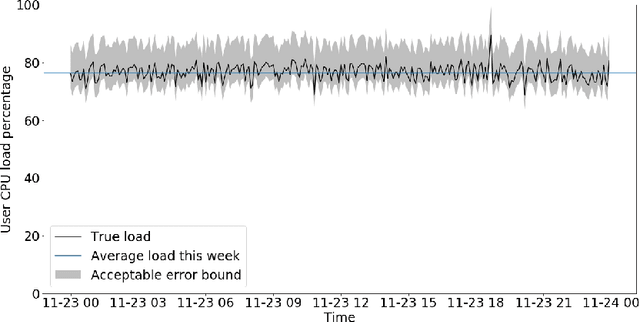
Microsoft Azure is dedicated to guarantee high quality of service to its customers, in particular, during periods of high customer activity, while controlling cost. We employ a Data Science (DS) driven solution to predict user load and leverage these predictions to optimize resource allocation. To this end, we built the Seagull infrastructure that processes per-server telemetry, validates the data, trains and deploys ML models. The models are used to predict customer load per server (24h into the future), and optimize service operations. Seagull continually re-evaluates accuracy of predictions, fallback to previously known good models and triggers alerts as appropriate. We deployed this infrastructure in production for PostgreSQL and MySQL servers across all Azure regions, and applied it to the problem of scheduling server backups during low-load time. This minimizes interference with user-induced load and improves customer experience.