 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Tail Performance of a Deliberation E2E ASR Model Using a Large Text Corpus
Aug 25, 2020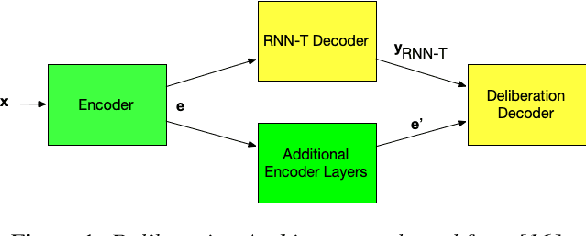
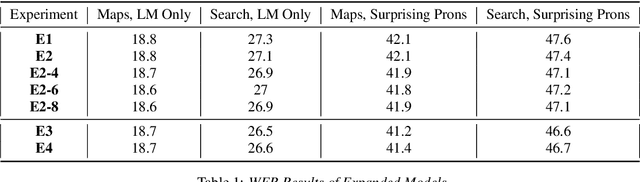
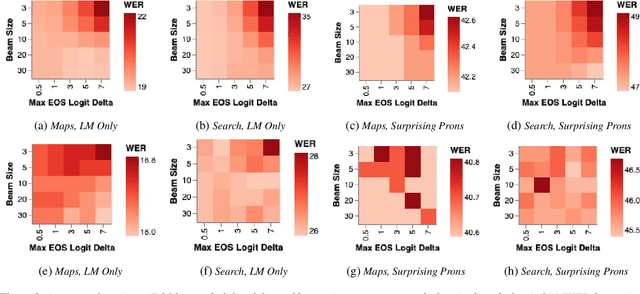
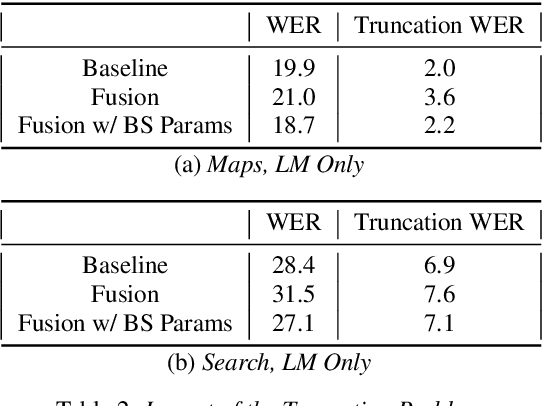
End-to-end (E2E) automatic speech recognition (ASR) systems lack the distinct language model (LM) component that characterizes traditional speech systems. While this simplifies the model architecture, it complicates the task of incorporating text-only data into training, which is important to the recognition of tail words that do not occur often in audio-text pairs. While shallow fusion has been proposed as a method for incorporating a pre-trained LM into an E2E model at inference time, it has not yet been explored for very large text corpora, and it has been shown to be very sensitive to hyperparameter settings in the beam search. In this work, we apply shallow fusion to incorporate a very large text corpus into a state-of-the-art E2EASR model. We explore the impact of model size and show that intelligent pruning of the training set can be more effective than increasing the parameter count. Additionally, we show that incorporating the LM in minimum word error rate (MWER) fine tuning makes shallow fusion far less dependent on optimal hyperparameter settings, reducing the difficulty of that tuning problem.
RNN-T Models Fail to Generalize to Out-of-Domain Audio: Causes and Solutions
May 17, 2020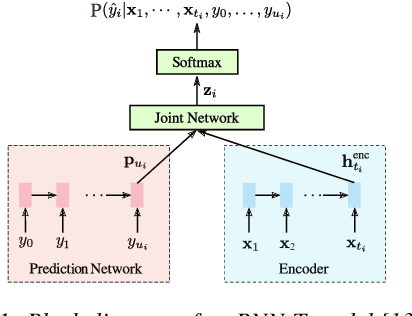
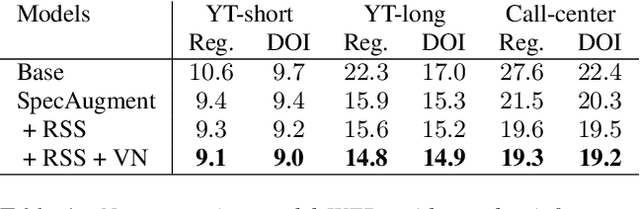
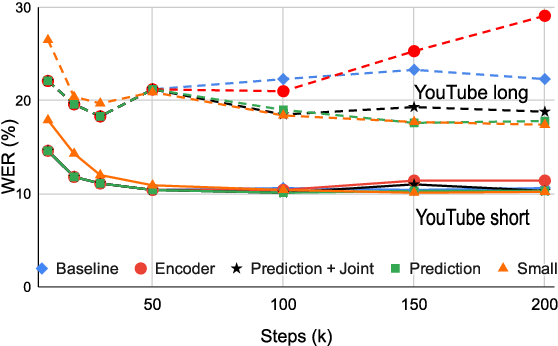
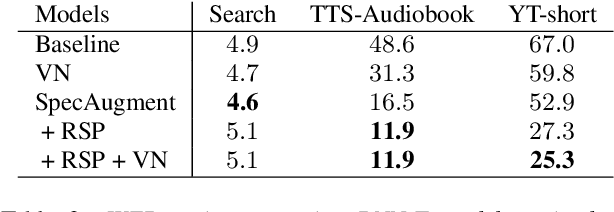
In recent years, all-neural end-to-end approaches have obtained state-of-the-art results on several challenging automatic speech recognition (ASR) tasks. However, most existing works focus on building ASR models where train and test data are drawn from the same domain. This results in poor generalization characteristics on mismatched-domains: e.g., end-to-end models trained on short segments perform poorly when evaluated on longer utterances. In this work, we analyze the generalization properties of streaming and non-streaming recurrent neural network transducer (RNN-T) based end-to-end models in order to identify model components that negatively affect generalization performance. We propose two solutions: combining multiple regularization techniques during training, and using dynamic overlapping inference. On a long-form YouTube test set, when the non-streaming RNN-T model is trained with shorter segments of data, the proposed combination improves word error rate (WER) from 22.3% to 14.8%; when the streaming RNN-T model trained on short Search queries, the proposed techniques improve WER on the YouTube set from 67.0% to 25.3%. Finally, when trained on Librispeech, we find that dynamic overlapping inference improves WER on YouTube from 99.8% to 33.0%.
Dynamic Sparsity Neural Networks for Automatic Speech Recognition
May 16, 2020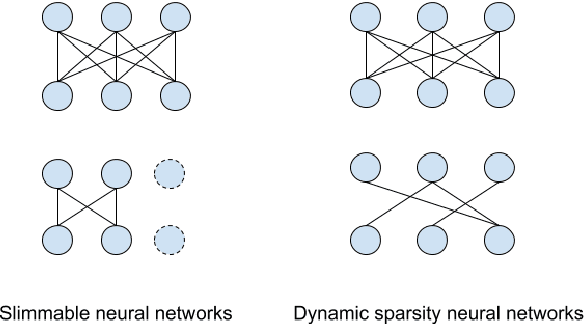
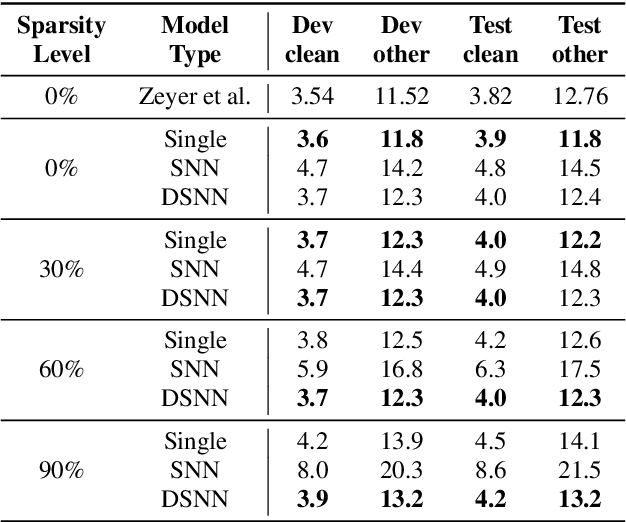
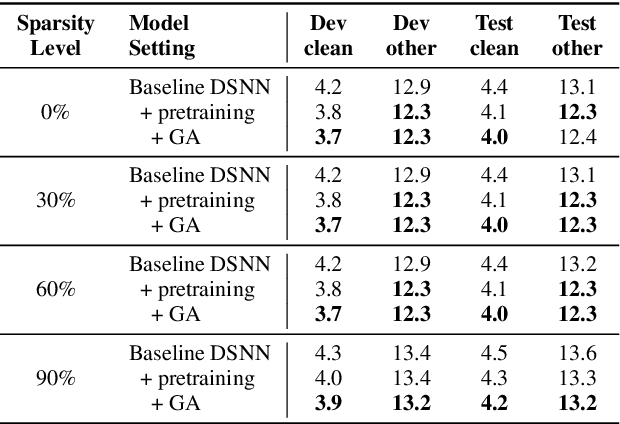
In automatic speech recognition (ASR), model pruning is a widely adopted technique that reduces model size and latency to deploy neural network models on edge devices with resource constraints. However, in order to optimize for hardware with different resource specifications and for applications that have various latency requirements, models with varying sparsity levels usually need to be trained and deployed separately. In this paper, generalizing from slimmable neural networks, we present dynamic sparsity neural networks (DSNN) that, once trained, can instantly switch to execute at any given sparsity level at run-time. We show the efficacy of such models on ASR through comprehensive experiments and demonstrate that the performance of a dynamic sparsity model is on par with, and in some cases exceeds, the performance of individually trained single sparsity networks. A trained DSNN model can therefore greatly ease the training process and simplifies deployment in diverse scenarios with resource constraints.
Conformer: Convolution-augmented Transformer for Speech Recognition
May 16, 2020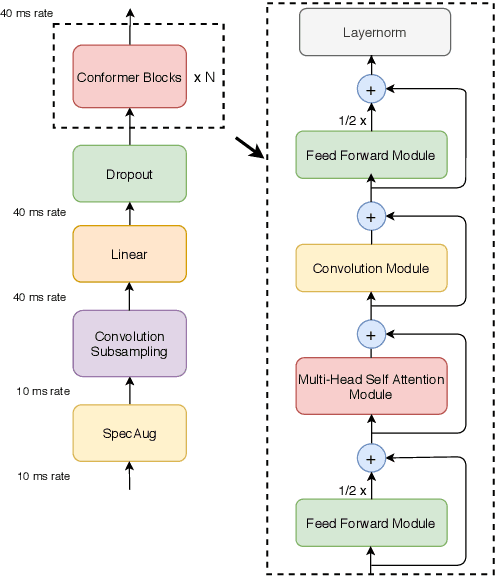
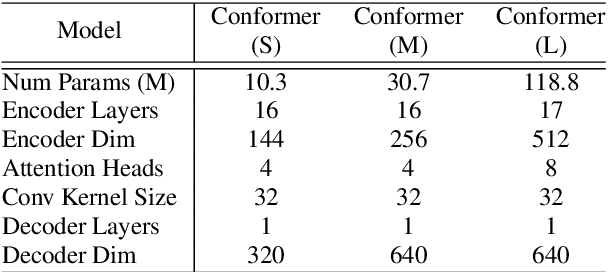

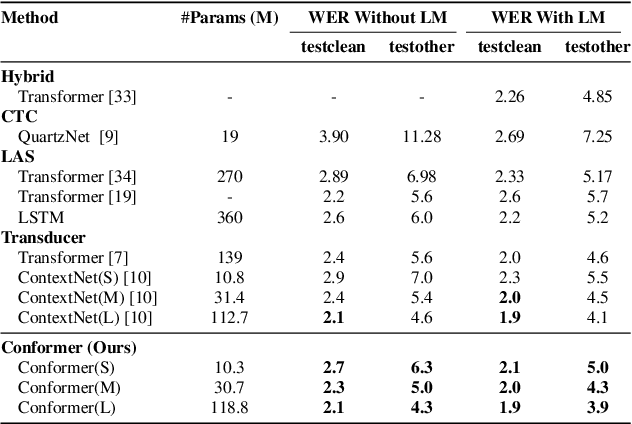
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
May 16, 2020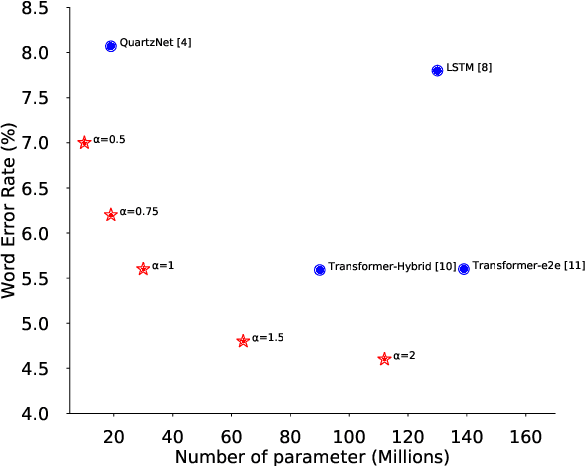
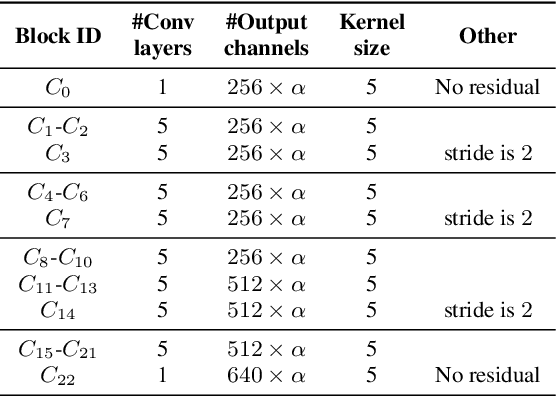
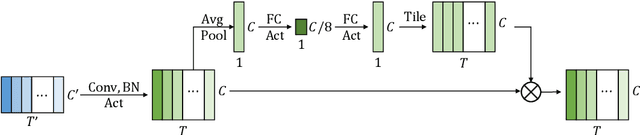
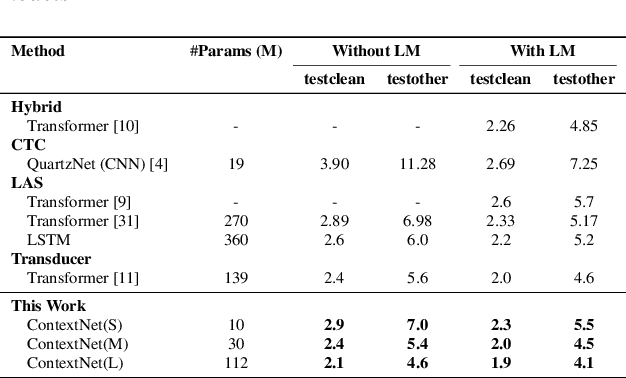
Convolutional neural networks (CNN) have shown promising results for end-to-end speech recognition, albeit still behind other state-of-the-art methods in performance. In this paper, we study how to bridge this gap and go beyond with a novel CNN-RNN-transducer architecture, which we call ContextNet. ContextNet features a fully convolutional encoder that incorporates global context information into convolution layers by adding squeeze-and-excitation modules. In addition, we propose a simple scaling method that scales the widths of ContextNet that achieves good trade-off between computation and accuracy. We demonstrate that on the widely used LibriSpeech benchmark, ContextNet achieves a word error rate (WER) of 2.1%/4.6% without external language model (LM), 1.9%/4.1% with LM and 2.9%/7.0% with only 10M parameters on the clean/noisy LibriSpeech test sets. This compares to the previous best published system of 2.0%/4.6% with LM and 3.9%/11.3% with 20M parameters. The superiority of the proposed ContextNet model is also verified on a much larger internal dataset.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020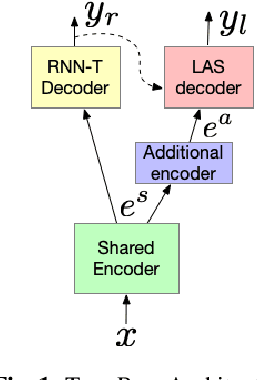
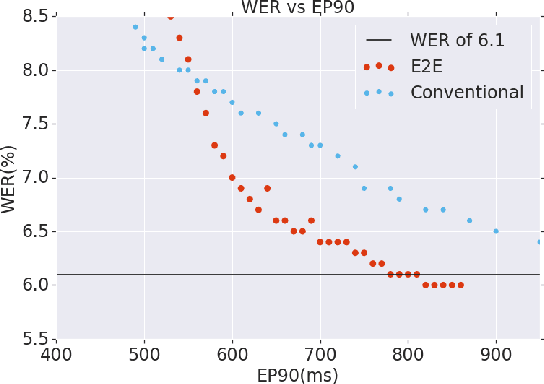
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
Mar 24, 2020
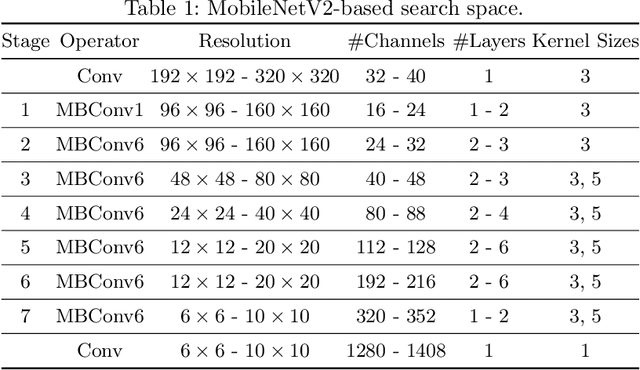
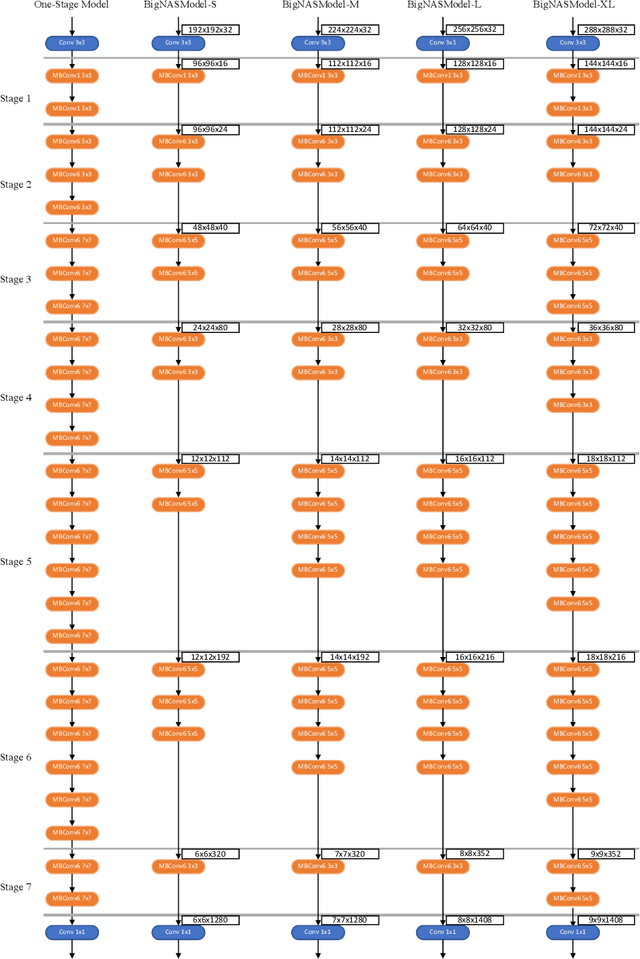
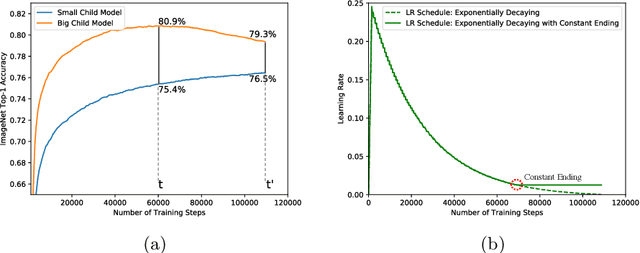
Neural architecture search (NAS) has shown promising results discovering models that are both accurate and fast. For NAS, training a one-shot model has become a popular strategy to rank the relative quality of different architectures (child models) using a single set of shared weights. However, while one-shot model weights can effectively rank different network architectures, the absolute accuracies from these shared weights are typically far below those obtained from stand-alone training. To compensate, existing methods assume that the weights must be retrained, finetuned, or otherwise post-processed after the search is completed. These steps significantly increase the compute requirements and complexity of the architecture search and model deployment. In this work, we propose BigNAS, an approach that challenges the conventional wisdom that post-processing of the weights is necessary to get good prediction accuracies. Without extra retraining or post-processing steps, we are able to train a single set of shared weights on ImageNet and use these weights to obtain child models whose sizes range from 200 to 1000 MFLOPs. Our discovered model family, BigNASModels, achieve top-1 accuracies ranging from 76.5% to 80.9%, surpassing state-of-the-art models in this range including EfficientNets and Once-for-All networks without extra retraining or post-processing. We present ablative study and analysis to further understand the proposed BigNASModels.
Deliberation Model Based Two-Pass End-to-End Speech Recognition
Mar 17, 2020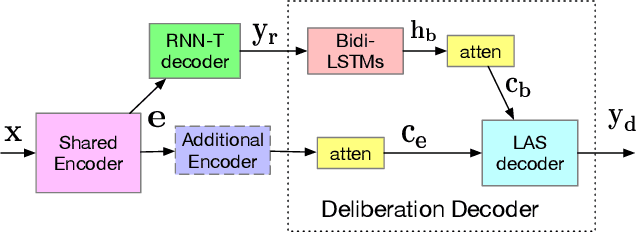
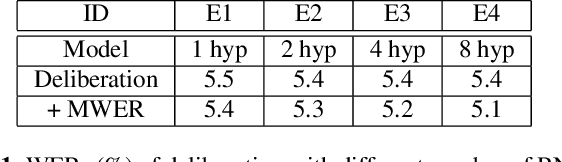
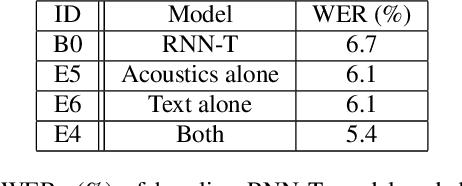
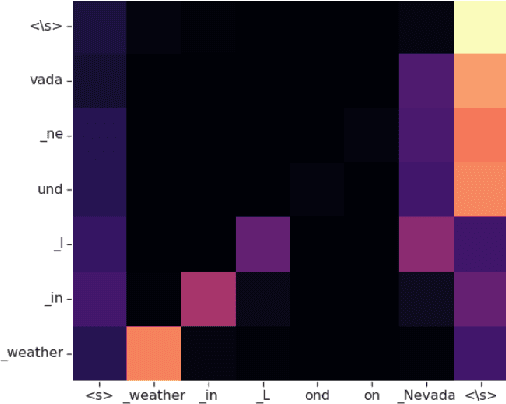
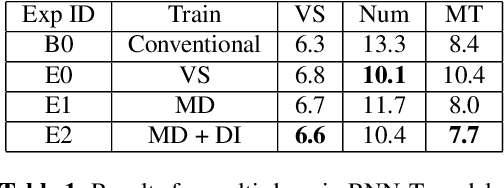
End-to-end (E2E) models have made rapid progress in automatic speech recognition (ASR) and perform competitively relative to conventional models. To further improve the quality, a two-pass model has been proposed to rescore streamed hypotheses using the non-streaming Listen, Attend and Spell (LAS) model while maintaining a reasonable latency. The model attends to acoustics to rescore hypotheses, as opposed to a class of neural correction models that use only first-pass text hypotheses. In this work, we propose to attend to both acoustics and first-pass hypotheses using a deliberation network. A bidirectional encoder is used to extract context information from first-pass hypotheses. The proposed deliberation model achieves 12% relative WER reduction compared to LAS rescoring in Google Voice Search (VS) tasks, and 23% reduction on a proper noun test set. Compared to a large conventional model, our best model performs 21% relatively better for VS. In terms of computational complexity, the deliberation decoder has a larger size than the LAS decoder, and hence requires more computations in second-pass decoding.
EfficientDet: Scalable and Efficient Object Detection
Nov 20, 2019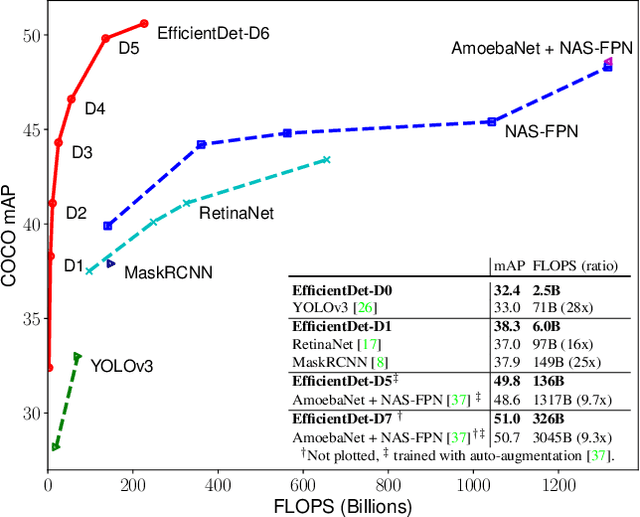
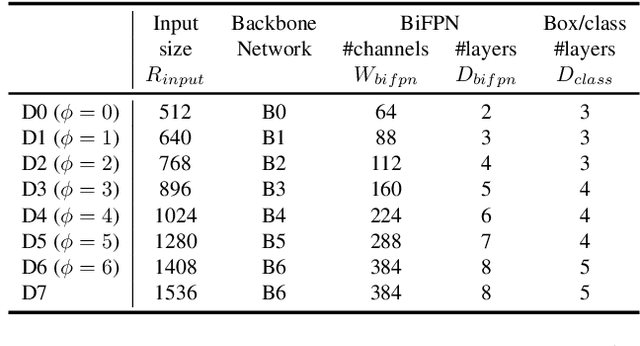
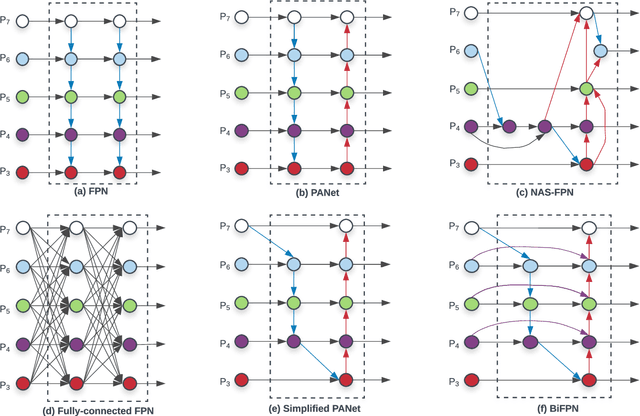
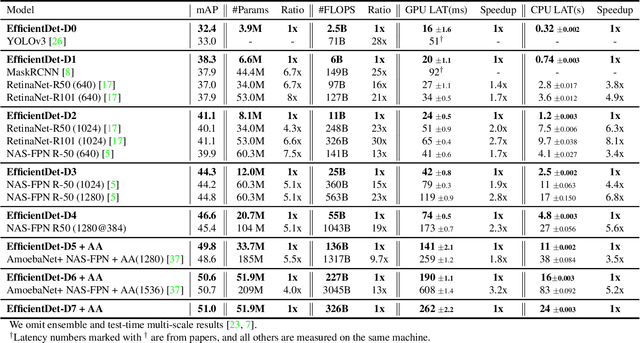
Model efficiency has become increasingly important in computer vision. In this paper, we systematically study various neural network architecture design choices for object detection and propose several key optimizations to improve efficiency. First, we propose a weighted bi-directional feature pyramid network (BiFPN), which allows easy and fast multi-scale feature fusion; Second, we propose a compound scaling method that uniformly scales the resolution, depth, and width for all backbone, feature network, and box/class prediction networks at the same time. Based on these optimizations, we have developed a new family of object detectors, called EfficientDet, which consistently achieve an order-of-magnitude better efficiency than prior art across a wide spectrum of resource constraints. In particular, without bells and whistles, our EfficientDet-D7 achieves stateof-the-art 51.0 mAP on COCO dataset with 52M parameters and 326B FLOPS1 , being 4x smaller and using 9.3x fewer FLOPS yet still more accurate (+0.3% mAP) than the best previous detector.
A comparison of end-to-end models for long-form speech recognition
Nov 06, 2019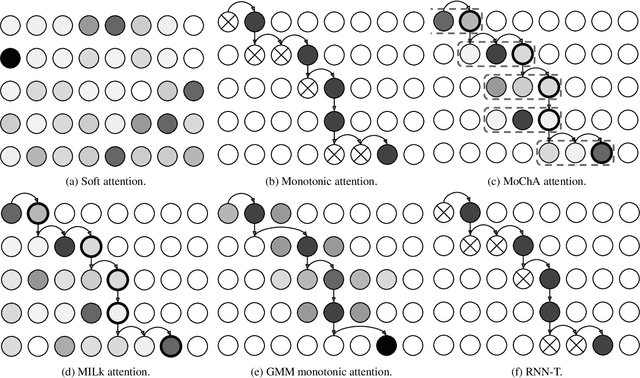

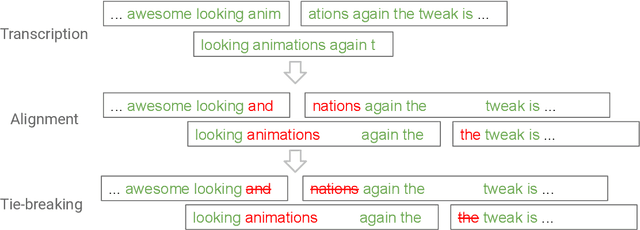
End-to-end automatic speech recognition (ASR) models, including both attention-based models and the recurrent neural network transducer (RNN-T), have shown superior performance compared to conventional systems. However, previous studies have focused primarily on short utterances that typically last for just a few seconds or, at most, a few tens of seconds. Whether such architectures are practical on long utterances that last from minutes to hours remains an open question. In this paper, we both investigate and improve the performance of end-to-end models on long-form transcription. We first present an empirical comparison of different end-to-end models on a real world long-form task and demonstrate that the RNN-T model is much more robust than attention-based systems in this regime. We next explore two improvements to attention-based systems that significantly improve its performance: restricting the attention to be monotonic, and applying a novel decoding algorithm that breaks long utterances into shorter overlapping segments. Combining these two improvements, we show that attention-based end-to-end models can be very competitive to RNN-T on long-form speech recognition.