 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Label-Free and Non-Monotonic Metric for Evaluating Denoising in Event Cameras
Jun 13, 2024



Event cameras are renowned for their high efficiency due to outputting a sparse, asynchronous stream of events. However, they are plagued by noisy events, especially in low light conditions. Denoising is an essential task for event cameras, but evaluating denoising performance is challenging. Label-dependent denoising metrics involve artificially adding noise to clean sequences, complicating evaluations. Moreover, the majority of these metrics are monotonic, which can inflate scores by removing substantial noise and valid events. To overcome these limitations, we propose the first label-free and non-monotonic evaluation metric, the area of the continuous contrast curve (AOCC), which utilizes the area enclosed by event frame contrast curves across different time intervals. This metric is inspired by how events capture the edge contours of scenes or objects with high temporal resolution. An effective denoising method removes noise without eliminating these edge-contour events, thus preserving the contrast of event frames. Consequently, contrast across various time ranges serves as a metric to assess denoising effectiveness. As the time interval lengthens, the curve will initially rise and then fall. The proposed metric is validated through both theoretical and experimental evidence.
Large Language Models as Optimizers
Sep 07, 2023



Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we propose Optimization by PROmpting (OPRO), a simple and effective approach to leverage large language models (LLMs) as optimizers, where the optimization task is described in natural language. In each optimization step, the LLM generates new solutions from the prompt that contains previously generated solutions with their values, then the new solutions are evaluated and added to the prompt for the next optimization step. We first showcase OPRO on linear regression and traveling salesman problems, then move on to prompt optimization where the goal is to find instructions that maximize the task accuracy. With a variety of LLMs, we demonstrate that the best prompts optimized by OPRO outperform human-designed prompts by up to 8% on GSM8K, and by up to 50% on Big-Bench Hard tasks.
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
May 24, 2023The mixture proportions of pretraining data domains (e.g., Wikipedia, books, web text) greatly affect language model (LM) performance. In this paper, we propose Domain Reweighting with Minimax Optimization (DoReMi), which first trains a small proxy model using group distributionally robust optimization (Group DRO) over domains to produce domain weights (mixture proportions) without knowledge of downstream tasks. We then resample a dataset with these domain weights and train a larger, full-sized model. In our experiments, we use DoReMi on a 280M-parameter proxy model to find domain weights for training an 8B-parameter model (30x larger) more efficiently. On The Pile, DoReMi improves perplexity across all domains, even when it downweights a domain. DoReMi improves average few-shot downstream accuracy by 6.5% points over a baseline model trained using The Pile's default domain weights and reaches the baseline accuracy with 2.6x fewer training steps. On the GLaM dataset, DoReMi, which has no knowledge of downstream tasks, even matches the performance of using domain weights tuned on downstream tasks.
IDO-VFI: Identifying Dynamics via Optical Flow Guidance for Video Frame Interpolation with Events
May 18, 2023



Video frame interpolation aims to generate high-quality intermediate frames from boundary frames and increase frame rate. While existing linear, symmetric and nonlinear models are used to bridge the gap from the lack of inter-frame motion, they cannot reconstruct real motions. Event cameras, however, are ideal for capturing inter-frame dynamics with their extremely high temporal resolution. In this paper, we propose an event-and-frame-based video frame interpolation method named IDO-VFI that assigns varying amounts of computation for different sub-regions via optical flow guidance. The proposed method first estimates the optical flow based on frames and events, and then decides whether to further calculate the residual optical flow in those sub-regions via a Gumbel gating module according to the optical flow amplitude. Intermediate frames are eventually generated through a concise Transformer-based fusion network. Our proposed method maintains high-quality performance while reducing computation time and computational effort by 10% and 17% respectively on Vimeo90K datasets, compared with a unified process on the whole region. Moreover, our method outperforms state-of-the-art frame-only and frames-plus-events methods on multiple video frame interpolation benchmarks. Codes and models are available at https://github.com/shicy17/IDO-VFI.
Larger language models do in-context learning differently
Mar 08, 2023



We study how in-context learning (ICL) in language models is affected by semantic priors versus input-label mappings. We investigate two setups-ICL with flipped labels and ICL with semantically-unrelated labels-across various model families (GPT-3, InstructGPT, Codex, PaLM, and Flan-PaLM). First, experiments on ICL with flipped labels show that overriding semantic priors is an emergent ability of model scale. While small language models ignore flipped labels presented in-context and thus rely primarily on semantic priors from pretraining, large models can override semantic priors when presented with in-context exemplars that contradict priors, despite the stronger semantic priors that larger models may hold. We next study semantically-unrelated label ICL (SUL-ICL), in which labels are semantically unrelated to their inputs (e.g., foo/bar instead of negative/positive), thereby forcing language models to learn the input-label mappings shown in in-context exemplars in order to perform the task. The ability to do SUL-ICL also emerges primarily with scale, and large-enough language models can even perform linear classification in a SUL-ICL setting. Finally, we evaluate instruction-tuned models and find that instruction tuning strengthens both the use of semantic priors and the capacity to learn input-label mappings, but more of the former.
Resource-Constrained Neural Architecture Search on Tabular Datasets
Apr 15, 2022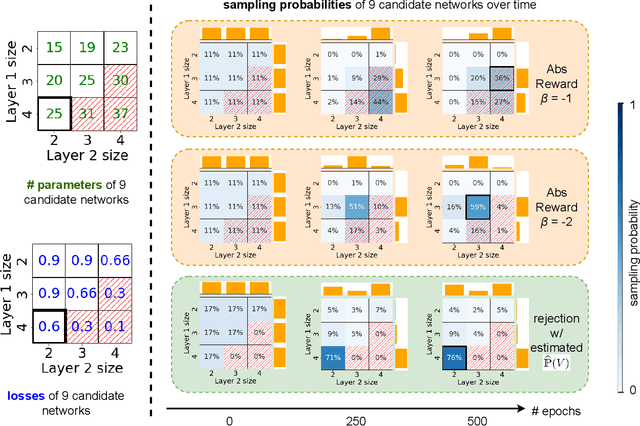
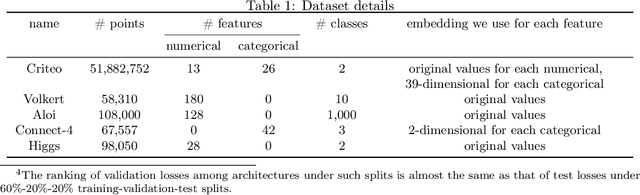
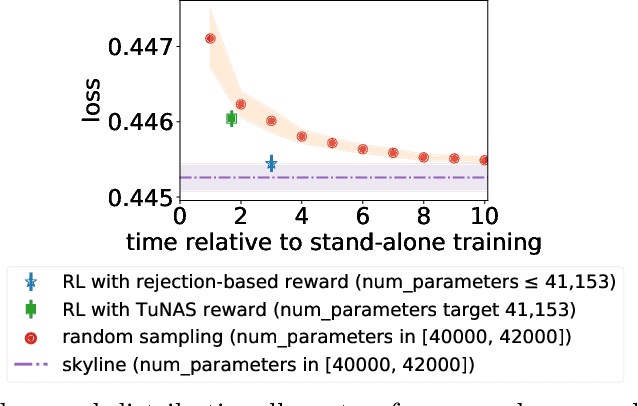
The best neural architecture for a given machine learning problem depends on many factors: not only the complexity and structure of the dataset, but also on resource constraints including latency, compute, energy consumption, etc. Neural architecture search (NAS) for tabular datasets is an important but under-explored problem. Previous NAS algorithms designed for image search spaces incorporate resource constraints directly into the reinforcement learning rewards. In this paper, we argue that search spaces for tabular NAS pose considerable challenges for these existing reward-shaping methods, and propose a new reinforcement learning (RL) controller to address these challenges. Motivated by rejection sampling, when we sample candidate architectures during a search, we immediately discard any architecture that violates our resource constraints. We use a Monte-Carlo-based correction to our RL policy gradient update to account for this extra filtering step. Results on several tabular datasets show TabNAS, the proposed approach, efficiently finds high-quality models that satisfy the given resource constraints.
Transformer Quality in Linear Time
Feb 21, 2022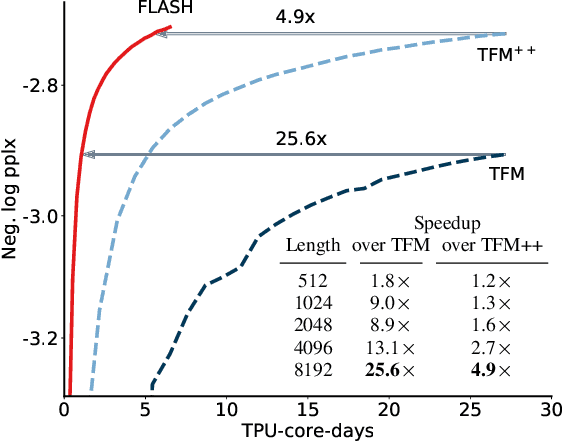
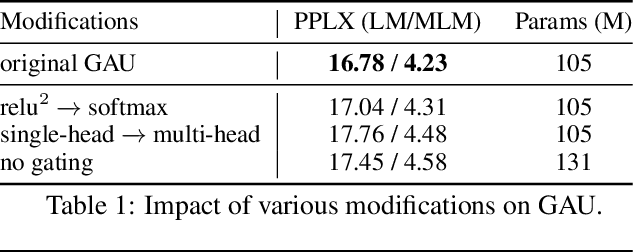
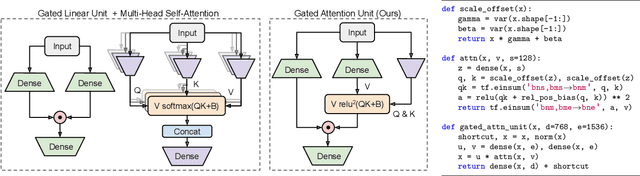

We revisit the design choices in Transformers, and propose methods to address their weaknesses in handling long sequences. First, we propose a simple layer named gated attention unit, which allows the use of a weaker single-head attention with minimal quality loss. We then propose a linear approximation method complementary to this new layer, which is accelerator-friendly and highly competitive in quality. The resulting model, named FLASH, matches the perplexity of improved Transformers over both short (512) and long (8K) context lengths, achieving training speedups of up to 4.9$\times$ on Wiki-40B and 12.1$\times$ on PG-19 for auto-regressive language modeling, and 4.8$\times$ on C4 for masked language modeling.
Mixture-of-Experts with Expert Choice Routing
Feb 18, 2022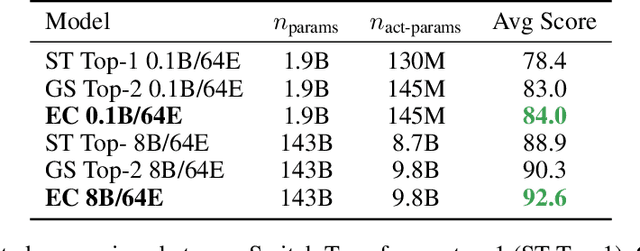
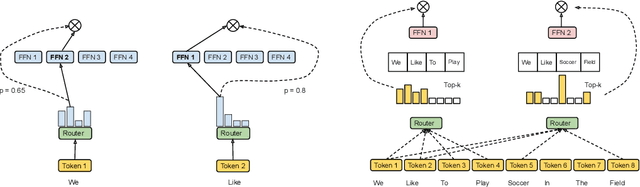
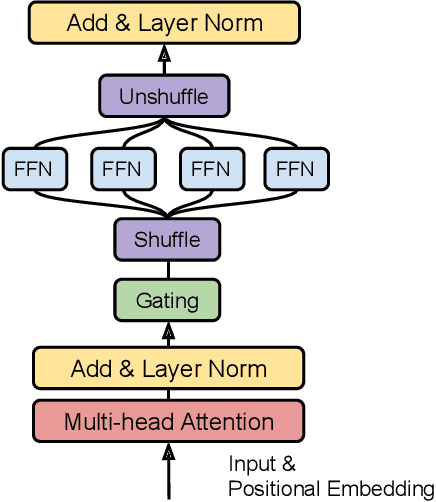

Sparsely-activated Mixture-of-experts (MoE) models allow the number of parameters to greatly increase while keeping the amount of computation for a given token or a given sample unchanged. However, a poor expert routing strategy (e.g. one resulting in load imbalance) can cause certain experts to be under-trained, leading to an expert being under or over-specialized. Prior work allocates a fixed number of experts to each token using a top-k function regardless of the relative importance of different tokens. To address this, we propose a heterogeneous mixture-of-experts employing an expert choice method. Instead of letting tokens select the top-k experts, we have experts selecting the top-k tokens. As a result, each token can be routed to a variable number of experts and each expert can have a fixed bucket size. We systematically study pre-training speedups using the same computational resources of the Switch Transformer top-1 and GShard top-2 gating of prior work and find that our method improves training convergence time by more than 2x. For the same computational cost, our method demonstrates higher performance in fine-tuning 11 selected tasks in the GLUE and SuperGLUE benchmarks. For a smaller activation cost, our method outperforms the T5 dense model in 7 out of the 11 tasks.
Combined Scaling for Zero-shot Transfer Learning
Nov 19, 2021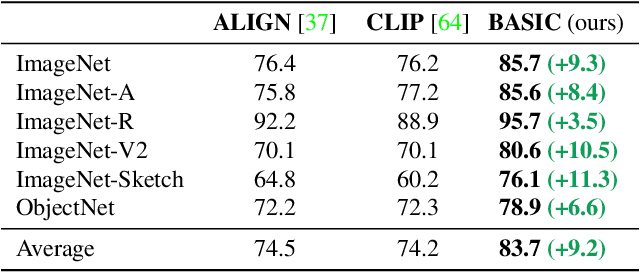
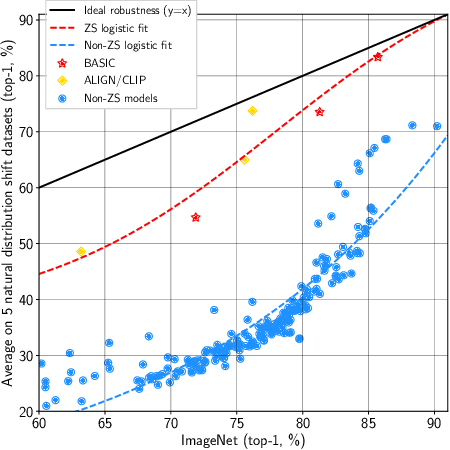
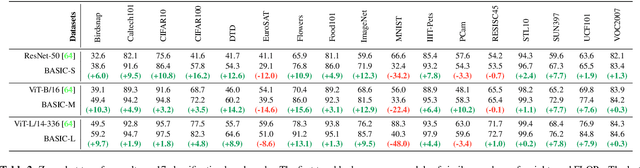

We present a combined scaling method called BASIC that achieves 85.7% top-1 zero-shot accuracy on the ImageNet ILSVRC-2012 validation set, surpassing the best-published zero-shot models - CLIP and ALIGN - by 9.3%. Our BASIC model also shows significant improvements in robustness benchmarks. For instance, on 5 test sets with natural distribution shifts such as ImageNet-{A,R,V2,Sketch} and ObjectNet, our model achieves 83.7% top-1 average accuracy, only a small drop from the its original ImageNet accuracy. To achieve these results, we scale up the contrastive learning framework of CLIP and ALIGN in three dimensions: data size, model size, and batch size. Our dataset has 6.6B noisy image-text pairs, which is 4x larger than ALIGN, and 16x larger than CLIP. Our largest model has 3B weights, which is 3.75x larger in parameters and 8x larger in FLOPs than ALIGN and CLIP. Our batch size is 65536 which is 2x more than CLIP and 4x more than ALIGN. The main challenge with scaling is the limited memory of our accelerators such as GPUs and TPUs. We hence propose a simple method of online gradient caching to overcome this limit.
Primer: Searching for Efficient Transformers for Language Modeling
Sep 17, 2021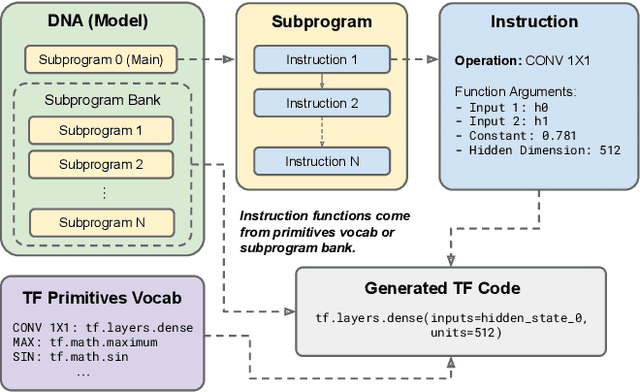
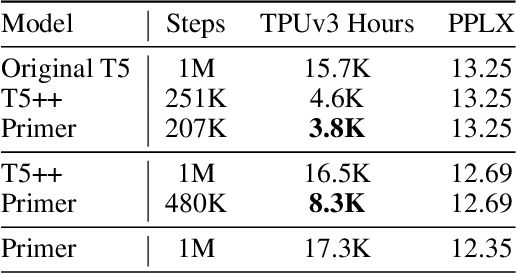
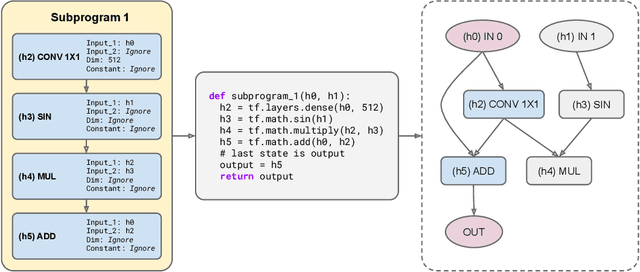
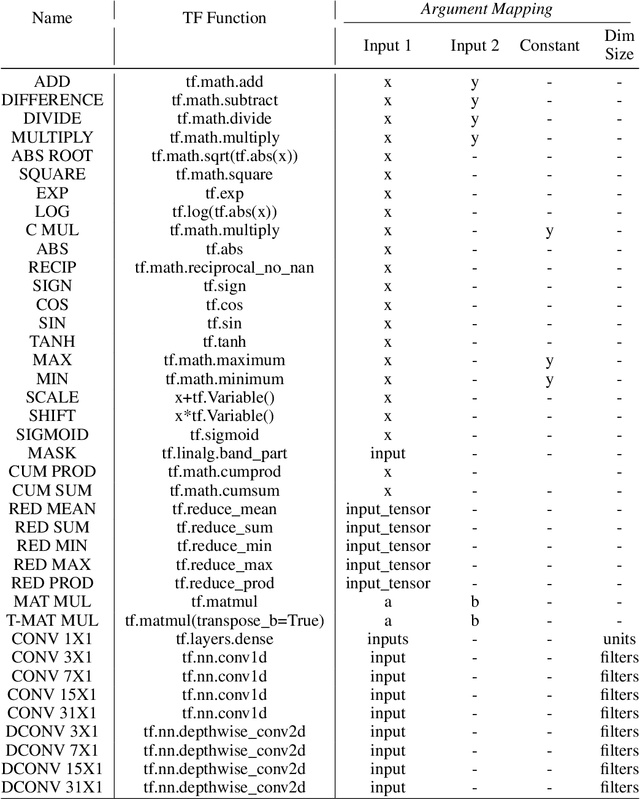
Large Transformer models have been central to recent advances in natural language processing. The training and inference costs of these models, however, have grown rapidly and become prohibitively expensive. Here we aim to reduce the costs of Transformers by searching for a more efficient variant. Compared to previous approaches, our search is performed at a lower level, over the primitives that define a Transformer TensorFlow program. We identify an architecture, named Primer, that has a smaller training cost than the original Transformer and other variants for auto-regressive language modeling. Primer's improvements can be mostly attributed to two simple modifications: squaring ReLU activations and adding a depthwise convolution layer after each Q, K, and V projection in self-attention. Experiments show Primer's gains over Transformer increase as compute scale grows and follow a power law with respect to quality at optimal model sizes. We also verify empirically that Primer can be dropped into different codebases to significantly speed up training without additional tuning. For example, at a 500M parameter size, Primer improves the original T5 architecture on C4 auto-regressive language modeling, reducing the training cost by 4X. Furthermore, the reduced training cost means Primer needs much less compute to reach a target one-shot performance. For instance, in a 1.9B parameter configuration similar to GPT-3 XL, Primer uses 1/3 of the training compute to achieve the same one-shot performance as Transformer. We open source our models and several comparisons in T5 to help with reproducibility.